 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen BBR Meets Live Streaming
Jun 02, 2026Recently, industrial pioneers like Amazon, Tencent, ByteDance, and Huawei have been adopting BBR as their congestion control algorithm for live-streaming applications, including TikTok Live. However, BBR, originally crafted for bulk data transmission, faces multiple challenges in live-streaming scenarios. In this paper, we first explore two key issues associated with BBR due to inaccurate bandwidth estimation in live-streaming scenarios: (i) BBR cannot easily exit its startup phase, resulting in a fierce self-inflicted loss. (ii) BBR sends data at a lower rate than the available bandwidth during its stable phase. We then propose BBR-Copilot, an auxiliary congestion control component that cooperates with BBR, making BBR better adapt to live-streaming scenarios. BBR-Copilot allows for proactively generating accurate bandwidth measurement samples by smartly creating and sending extra data. We implement the BBR-Copilot prototype upon QUIC and evaluate it via testbed. Experimental evaluation results show that BBR-Copilot effectively enhances BBR's performance in live-streaming scenarios.
EmoTrans: A Benchmark for Understanding, Reasoning, and Predicting Emotion Transitions in Multimodal LLMs
Apr 25, 2026Recent multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and generation, and are increasingly used in applications such as social robots and human-computer interaction, where understanding human emotions is essential. However, existing benchmarks mainly formulate emotion understanding as a static recognition problem, leaving it largely unclear whether current MLLMs can understand emotion as a dynamic process that evolves, shifts between states, and unfolds across diverse social contexts. To bridge this gap, we present EmoTrans, a benchmark for evaluating emotion dynamics understanding in multimodal videos. EmoTrans contains 1,000 carefully collected and manually annotated video clips, covering 12 real-world scenarios, and further provides over 3,000 task-specific question-answer (QA) pairs for fine-grained evaluation. The benchmark introduces four tasks, namely Emotion Change Detection (ECD), Emotion State Identification (ESI), Emotion Transition Reasoning (ETR), and Next Emotion Prediction (NEP), forming a progressive evaluation framework from coarse-grained detection to deeper reasoning and prediction. We conduct a comprehensive evaluation of 18 state-of-the-art MLLMs on EmoTrans and obtain two main findings. First, although current MLLMs show relatively stronger performance on coarse-grained emotion change detection, they still struggle with fine-grained emotion dynamics modeling. Second, socially complex settings, especially multi-person scenarios, remain substantially challenging, while reasoning-oriented variants do not consistently yield clear improvements. To facilitate future research, we publicly release the benchmark, evaluation protocol, and code at https://github.com/Emo-gml/EmoTrans.
Nüwa: Mending the Spatial Integrity Torn by VLM Token Pruning
Feb 03, 2026Vision token pruning has proven to be an effective acceleration technique for the efficient Vision Language Model (VLM). However, existing pruning methods demonstrate excellent performance preservation in visual question answering (VQA) and suffer substantial degradation on visual grounding (VG) tasks. Our analysis of the VLM's processing pipeline reveals that strategies utilizing global semantic similarity and attention scores lose the global spatial reference frame, which is derived from the interactions of tokens' positional information. Motivated by these findings, we propose $\text{Nüwa}$, a two-stage token pruning framework that enables efficient feature aggregation while maintaining spatial integrity. In the first stage, after the vision encoder, we apply three operations, namely separation, alignment, and aggregation, which are inspired by swarm intelligence algorithms to retain information-rich global spatial anchors. In the second stage, within the LLM, we perform text-guided pruning to retain task-relevant visual tokens. Extensive experiments demonstrate that $\text{Nüwa}$ achieves SOTA performance on multiple VQA benchmarks (from 94% to 95%) and yields substantial improvements on visual grounding tasks (from 7% to 47%).
TheraMind: A Strategic and Adaptive Agent for Longitudinal Psychological Counseling
Oct 29, 2025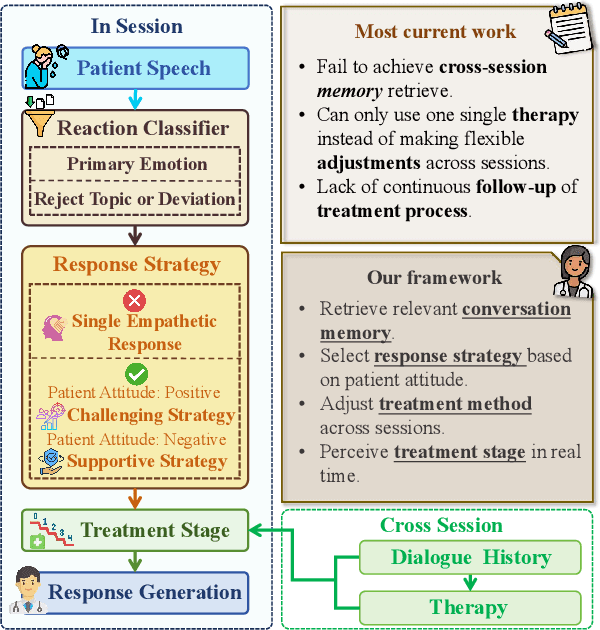
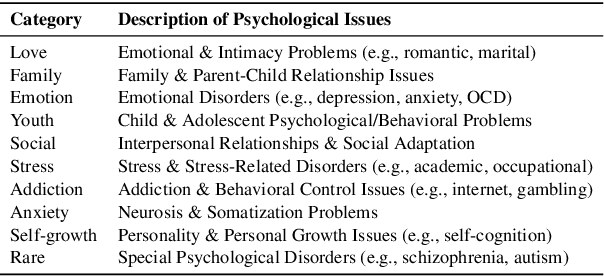
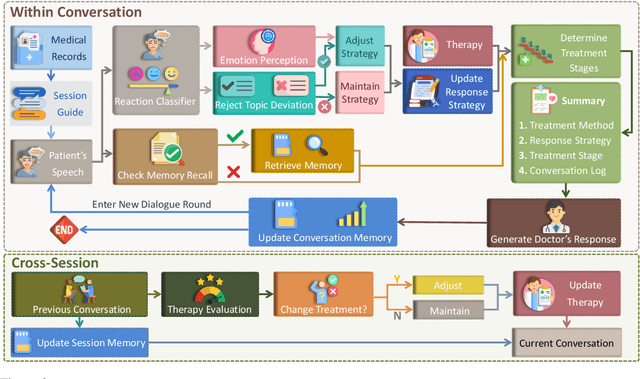
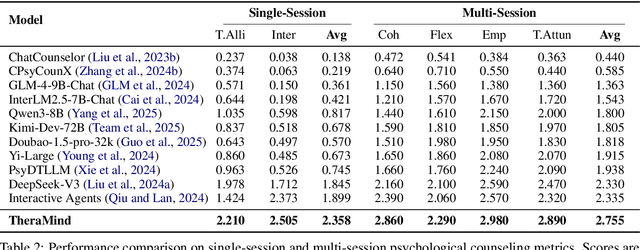
Large language models (LLMs) in psychological counseling have attracted increasing attention. However, existing approaches often lack emotional understanding, adaptive strategies, and the use of therapeutic methods across multiple sessions with long-term memory, leaving them far from real clinical practice. To address these critical gaps, we introduce TheraMind, a strategic and adaptive agent for longitudinal psychological counseling. The cornerstone of TheraMind is a novel dual-loop architecture that decouples the complex counseling process into an Intra-Session Loop for tactical dialogue management and a Cross-Session Loop for strategic therapeutic planning. The Intra-Session Loop perceives the patient's emotional state to dynamically select response strategies while leveraging cross-session memory to ensure continuity. Crucially, the Cross-Session Loop empowers the agent with long-term adaptability by evaluating the efficacy of the applied therapy after each session and adjusting the method for subsequent interactions. We validate our approach in a high-fidelity simulation environment grounded in real clinical cases. Extensive evaluations show that TheraMind outperforms other methods, especially on multi-session metrics like Coherence, Flexibility, and Therapeutic Attunement, validating the effectiveness of its dual-loop design in emulating strategic, adaptive, and longitudinal therapeutic behavior. The code is publicly available at https://0mwwm0.github.io/TheraMind/.
Beyond Empathy: Integrating Diagnostic and Therapeutic Reasoning with Large Language Models for Mental Health Counseling
May 21, 2025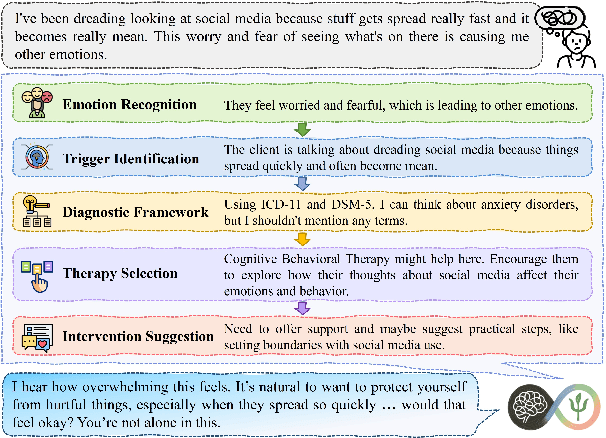

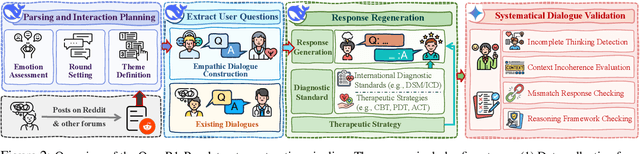
Large language models (LLMs) hold significant potential for mental health support, capable of generating empathetic responses and simulating therapeutic conversations. However, existing LLM-based approaches often lack the clinical grounding necessary for real-world psychological counseling, particularly in explicit diagnostic reasoning aligned with standards like the DSM/ICD and incorporating diverse therapeutic modalities beyond basic empathy or single strategies. To address these critical limitations, we propose PsyLLM, the first large language model designed to systematically integrate both diagnostic and therapeutic reasoning for mental health counseling. To develop the PsyLLM, we propose a novel automated data synthesis pipeline. This pipeline processes real-world mental health posts, generates multi-turn dialogue structures, and leverages LLMs guided by international diagnostic standards (e.g., DSM/ICD) and multiple therapeutic frameworks (e.g., CBT, ACT, psychodynamic) to simulate detailed clinical reasoning processes. Rigorous multi-dimensional filtering ensures the generation of high-quality, clinically aligned dialogue data. In addition, we introduce a new benchmark and evaluation protocol, assessing counseling quality across four key dimensions: comprehensiveness, professionalism, authenticity, and safety. Our experiments demonstrate that PsyLLM significantly outperforms state-of-the-art baseline models on this benchmark.
EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language Models
Feb 06, 2025



With the integration of Multimodal large language models (MLLMs) into robotic systems and various AI applications, embedding emotional intelligence (EI) capabilities into these models is essential for enabling robots to effectively address human emotional needs and interact seamlessly in real-world scenarios. Existing static, text-based, or text-image benchmarks overlook the multimodal complexities of real-world interactions and fail to capture the dynamic, multimodal nature of emotional expressions, making them inadequate for evaluating MLLMs' EI. Based on established psychological theories of EI, we build EmoBench-M, a novel benchmark designed to evaluate the EI capability of MLLMs across 13 valuation scenarios from three key dimensions: foundational emotion recognition, conversational emotion understanding, and socially complex emotion analysis. Evaluations of both open-source and closed-source MLLMs on EmoBench-M reveal a significant performance gap between them and humans, highlighting the need to further advance their EI capabilities. All benchmark resources, including code and datasets, are publicly available at https://emo-gml.github.io/.
Ister: Inverted Seasonal-Trend Decomposition Transformer for Explainable Multivariate Time Series Forecasting
Dec 25, 2024



In long-term time series forecasting, Transformer-based models have achieved great success, due to its ability to capture long-range dependencies. However, existing transformer-based methods face challenges in accurately identifying which variables play a pivotal role in the prediction process and tend to overemphasize noisy channels, thereby limiting the interpretability and practical effectiveness of the models. Besides, it faces scalability issues due to quadratic computational complexity of self-attention. In this paper, we propose a new model named Inverted Seasonal-Trend Decomposition Transformer (Ister), which addresses these challenges in long-term multivariate time series forecasting by designing an improved Transformer-based structure. Ister firstly decomposes original time series into seasonal and trend components. Then we propose a new Dot-attention mechanism to process the seasonal component, which improves both accuracy, computation complexity and interpretability. Upon completion of the training phase, it allows users to intuitively visualize the significance of each feature in the overall prediction. We conduct comprehensive experiments, and the results show that Ister achieves state-of-the-art (SOTA) performance on multiple datasets, surpassing existing models in long-term prediction tasks.
Cerberus: Efficient Inference with Adaptive Parallel Decoding and Sequential Knowledge Enhancement
Oct 17, 2024



Large language models (LLMs) often face a bottleneck in inference speed due to their reliance on auto-regressive decoding. Recently, parallel decoding has shown significant promise in enhancing inference efficiency. However, we have identified two key issues with existing parallel decoding frameworks: (1) decoding heads fail to balance prediction accuracy and the parallelism of execution, and (2) parallel decoding is not a universal solution, as it can bring unnecessary overheads at some challenging decoding steps. To address these issues, we propose Cerberus, an adaptive parallel decoding framework introduces the gating mechanism to enable the LLMs to adaptively choose appropriate decoding approaches at each decoding step, along with introducing a new paradigm of decoding heads that introduce the sequential knowledge while maintaining execution parallelism. The experiment results demonstrate that the Cerberus can achieve up to 2.12x speed up compared to auto-regressive decoding, and outperforms one of the leading parallel decoding frameworks, Medusa, with a 10% - 30% increase in acceleration and superior generation quality.
Mitigating Noise Detriment in Differentially Private Federated Learning with Model Pre-training
Aug 18, 2024



Pre-training exploits public datasets to pre-train an advanced machine learning model, so that the model can be easily tuned to adapt to various downstream tasks. Pre-training has been extensively explored to mitigate computation and communication resource consumption. Inspired by these advantages, we are the first to explore how model pre-training can mitigate noise detriment in differentially private federated learning (DPFL). DPFL is upgraded from federated learning (FL), the de-facto standard for privacy preservation when training the model across multiple clients owning private data. DPFL introduces differentially private (DP) noises to obfuscate model gradients exposed in FL, which however can considerably impair model accuracy. In our work, we compare head fine-tuning (HT) and full fine-tuning (FT), which are based on pre-training, with scratch training (ST) in DPFL through a comprehensive empirical study. Our experiments tune pre-trained models (obtained by pre-training on ImageNet-1K) with CIFAR-10, CHMNIST and Fashion-MNIST (FMNIST) datasets, respectively. The results demonstrate that HT and FT can significantly mitigate noise influence by diminishing gradient exposure times. In particular, HT outperforms FT when the privacy budget is tight or the model size is large. Visualization and explanation study further substantiates our findings. Our pioneering study introduces a new perspective on enhancing DPFL and expanding its practical applications.
The Power of Bias: Optimizing Client Selection in Federated Learning with Heterogeneous Differential Privacy
Aug 16, 2024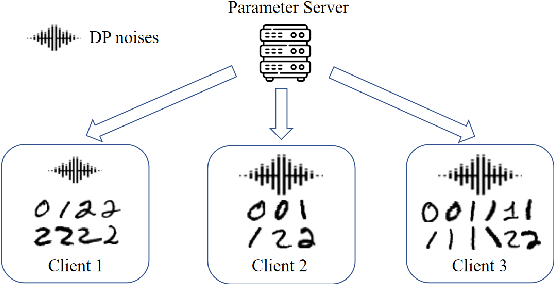
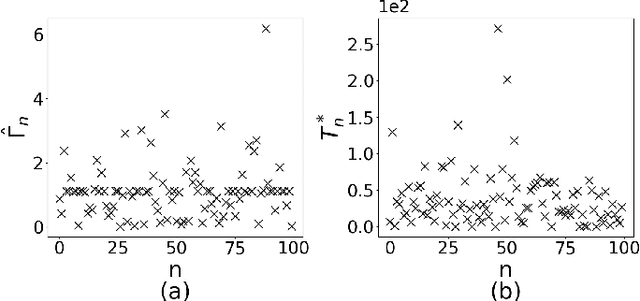
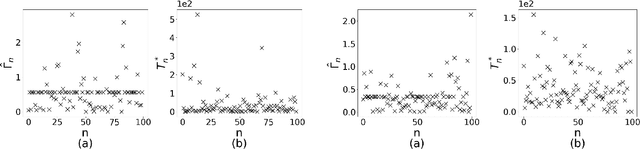
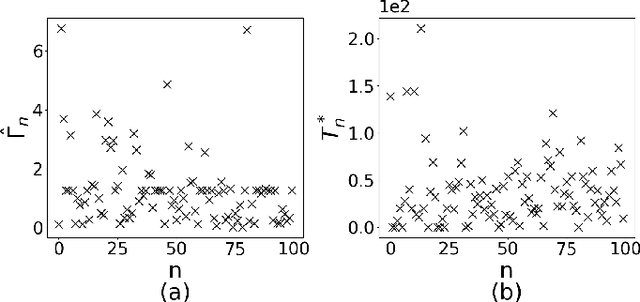
To preserve the data privacy, the federated learning (FL) paradigm emerges in which clients only expose model gradients rather than original data for conducting model training. To enhance the protection of model gradients in FL, differentially private federated learning (DPFL) is proposed which incorporates differentially private (DP) noises to obfuscate gradients before they are exposed. Yet, an essential but largely overlooked problem in DPFL is the heterogeneity of clients' privacy requirement, which can vary significantly between clients and extremely complicates the client selection problem in DPFL. In other words, both the data quality and the influence of DP noises should be taken into account when selecting clients. To address this problem, we conduct convergence analysis of DPFL under heterogeneous privacy, a generic client selection strategy, popular DP mechanisms and convex loss. Based on convergence analysis, we formulate the client selection problem to minimize the value of loss function in DPFL with heterogeneous privacy, which is a convex optimization problem and can be solved efficiently. Accordingly, we propose the DPFL-BCS (biased client selection) algorithm. The extensive experiment results with real datasets under both convex and non-convex loss functions indicate that DPFL-BCS can remarkably improve model utility compared with the SOTA baselines.