 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSync: Towards Generalizable and High-Fidelity Lip Synchronization for Challenging Scenarios
Mar 04, 2026Lip synchronization aims to generate realistic talking videos that match given audio, which is essential for high-quality video dubbing. However, current methods have fundamental drawbacks: mask-based approaches suffer from local color discrepancies, while mask-free methods struggle with global background texture misalignment. Furthermore, most methods struggle with diverse real-world scenarios such as stylized avatars, face occlusion, and extreme lighting conditions. In this paper, we propose UniSync, a unified framework designed for achieving high-fidelity lip synchronization in diverse scenarios. Specifically, UniSync uses a mask-free pose-anchored training strategy to keep head motion and eliminate synthesis color artifacts, while employing mask-based blending consistent inference to ensure structural precision and smooth blending. Notably, fine-tuning on compact but diverse videos empowers our model with exceptional domain adaptability, handling complex corner cases effectively. We also introduce the RealWorld-LipSync benchmark to evaluate models under real-world demands, which covers diverse application scenarios including both human faces and stylized avatars. Extensive experiments demonstrate that UniSync significantly outperforms state-of-the-art methods, advancing the field towards truly generalizable and production-ready lip synchronization.
WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL
Feb 15, 2026Reinforcement learning (RL) promises to unlock capabilities beyond imitation learning for Vision-Language-Action (VLA) models, but its requirement for massive real-world interaction prevents direct deployment on physical robots. Recent work attempts to use learned world models as simulators for policy optimization, yet closed-loop imagined rollouts inevitably suffer from hallucination and long-horizon error accumulation. Such errors do not merely degrade visual fidelity; they corrupt the optimization signal, encouraging policies to exploit model inaccuracies rather than genuine task progress. We propose WoVR, a reliable world-model-based reinforcement learning framework for post-training VLA policies. Instead of assuming a faithful world model, WoVR explicitly regulates how RL interacts with imperfect imagined dynamics. It improves rollout stability through a controllable action-conditioned video world model, reshapes imagined interaction to reduce effective error depth via Keyframe-Initialized Rollouts, and maintains policy-simulator alignment through World Model-Policy co-evolution. Extensive experiments on LIBERO benchmarks and real-world robotic manipulation demonstrate that WoVR enables stable long-horizon imagined rollouts and effective policy optimization, improving average LIBERO success from 39.95% to 69.2% (+29.3 points) and real-robot success from 61.7% to 91.7% (+30.0 points). These results show that learned world models can serve as practical simulators for reinforcement learning when hallucination is explicitly controlled.
$γ$-FedHT: Stepsize-Aware Hard-Threshold Gradient Compression in Federated Learning
May 18, 2025Gradient compression can effectively alleviate communication bottlenecks in Federated Learning (FL). Contemporary state-of-the-art sparse compressors, such as Top-$k$, exhibit high computational complexity, up to $\mathcal{O}(d\log_2{k})$, where $d$ is the number of model parameters. The hard-threshold compressor, which simply transmits elements with absolute values higher than a fixed threshold, is thus proposed to reduce the complexity to $\mathcal{O}(d)$. However, the hard-threshold compression causes accuracy degradation in FL, where the datasets are non-IID and the stepsize $\gamma$ is decreasing for model convergence. The decaying stepsize reduces the updates and causes the compression ratio of the hard-threshold compression to drop rapidly to an aggressive ratio. At or below this ratio, the model accuracy has been observed to degrade severely. To address this, we propose $\gamma$-FedHT, a stepsize-aware low-cost compressor with Error-Feedback to guarantee convergence. Given that the traditional theoretical framework of FL does not consider Error-Feedback, we introduce the fundamental conversation of Error-Feedback. We prove that $\gamma$-FedHT has the convergence rate of $\mathcal{O}(\frac{1}{T})$ ($T$ representing total training iterations) under $\mu$-strongly convex cases and $\mathcal{O}(\frac{1}{\sqrt{T}})$ under non-convex cases, \textit{same as FedAVG}. Extensive experiments demonstrate that $\gamma$-FedHT improves accuracy by up to $7.42\%$ over Top-$k$ under equal communication traffic on various non-IID image datasets.
Learn by Selling: Equipping Large Language Models with Product Knowledge for Context-Driven Recommendations
Jul 30, 2024


The rapid evolution of large language models (LLMs) has opened up new possibilities for applications such as context-driven product recommendations. However, the effectiveness of these models in this context is heavily reliant on their comprehensive understanding of the product inventory. This paper presents a novel approach to equipping LLMs with product knowledge by training them to respond contextually to synthetic search queries that include product IDs. We delve into an extensive analysis of this method, evaluating its effectiveness, outlining its benefits, and highlighting its constraints. The paper also discusses the potential improvements and future directions for this approach, providing a comprehensive understanding of the role of LLMs in product recommendations.
DAGC: Data-Volume-Aware Adaptive Sparsification Gradient Compression for Distributed Machine Learning in Mobile Computing
Nov 13, 2023



Distributed machine learning (DML) in mobile environments faces significant communication bottlenecks. Gradient compression has emerged as an effective solution to this issue, offering substantial benefits in environments with limited bandwidth and metered data. Yet, they encounter severe performance drop in non-IID environments due to a one-size-fits-all compression approach, which does not account for the varying data volumes across workers. Assigning varying compression ratios to workers with distinct data distributions and volumes is thus a promising solution. This study introduces an analysis of distributed SGD with non-uniform compression, which reveals that the convergence rate (indicative of the iterations needed to achieve a certain accuracy) is influenced by compression ratios applied to workers with differing volumes. Accordingly, we frame relative compression ratio assignment as an $n$-variables chi-square nonlinear optimization problem, constrained by a fixed and limited communication budget. We propose DAGC-R, which assigns the worker handling larger data volumes the conservative compression. Recognizing the computational limitations of mobile devices, we DAGC-A, which are computationally less demanding and enhances the robustness of the absolute gradient compressor in non-IID scenarios. Our experiments confirm that both the DAGC-A and DAGC-R can achieve better performance when dealing with highly imbalanced data volume distribution and restricted communication.
Writing your own book: A method for going from closed to open book QA to improve robustness and performance of smaller LLMs
May 18, 2023We introduce two novel methods, Tree-Search and Self-contextualizing QA, designed to enhance the performance of large language models (LLMs) in question-answering tasks. Tree-Search is a sampling technique specifically created to extract diverse information from an LLM for a given prompt. Self-contextualizing QA leverages Tree-Search to enable the model to create its own context using a wide range of information relevant to the prompt, evaluate it explicitly and return a open book answer to the initial prompt . We demonstrate that the quality of generated answers improves according to various metrics, including accuracy, informativeness, coherence, and consistency, as evaluated by GPT3.5(text-davinci-003). Furthermore, we show that our methods result in increased robustness and that performance is positively correlated with tree size, benefiting both answer quality and robustness. Finally, we discuss other promising applications of Tree-Search, highlighting its potential to enhance a broad range of tasks beyond question-answering. \noindent We also discuss several areas for future work, including refining the Tree-Search and Self-Contextualizing QA methods, improving the coherence of the generated context, and investigating the impact of bootstrapping on model robustness
Rapid focus map surveying for whole slide imaging with continues sample motion
Jul 06, 2017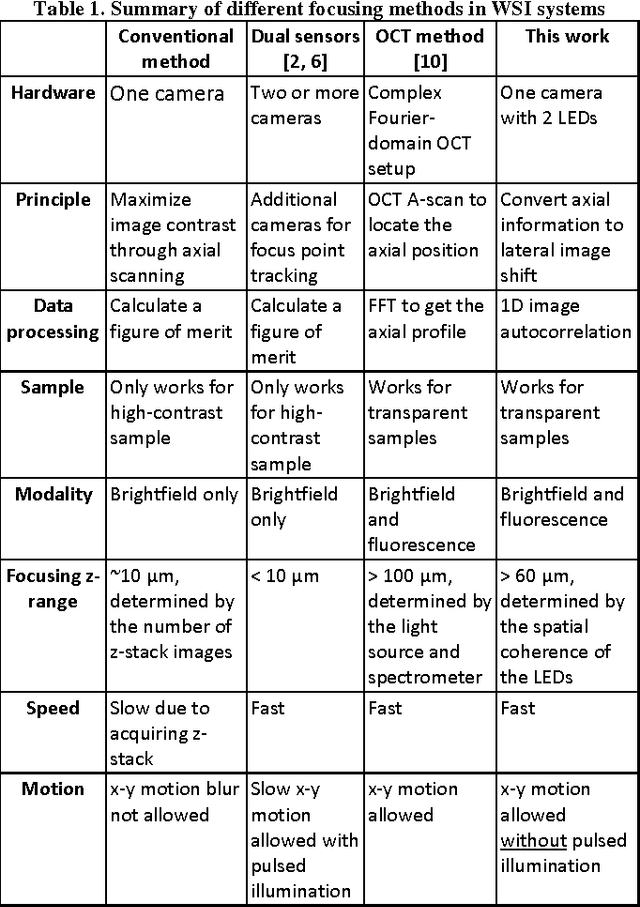
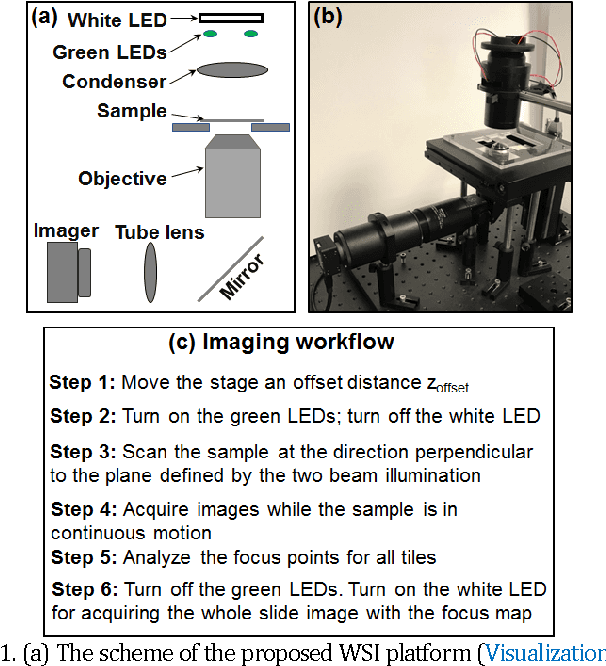
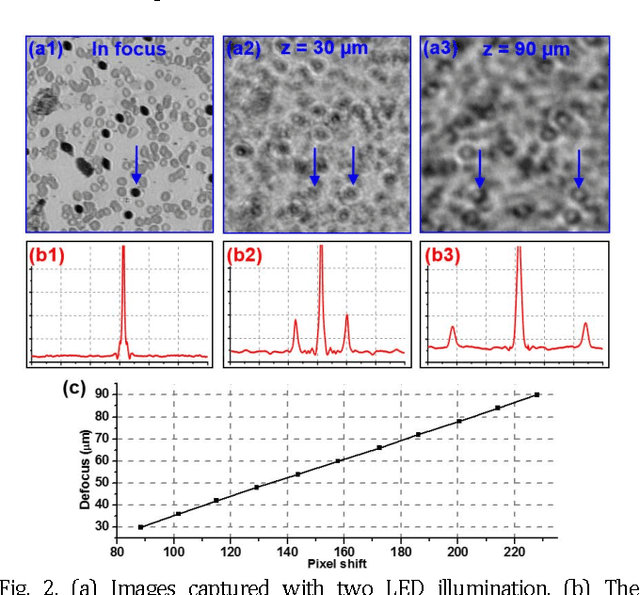
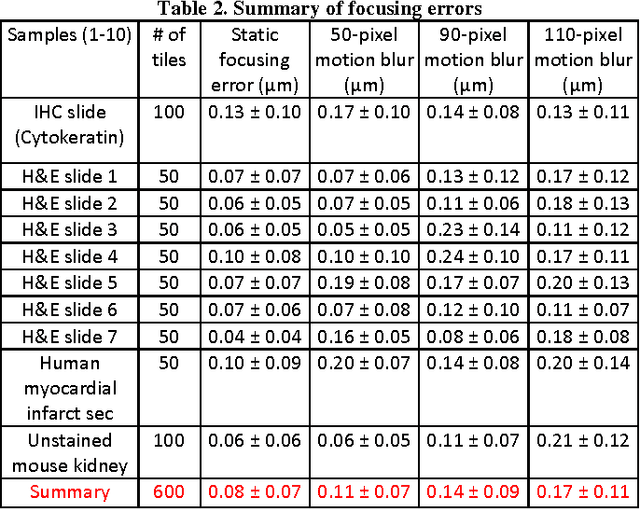
Whole slide imaging (WSI) has recently been cleared for primary diagnosis in the US. A critical challenge of WSI is to perform accurate focusing in high speed. Traditional systems create a focus map prior to scanning. For each focus point on the map, sample needs to be static in the x-y plane and axial scanning is needed to maximize the contrast. Here we report a novel focus map surveying method for WSI. The reported method requires no axial scanning, no additional camera and lens, works for stained and transparent samples, and allows continuous sample motion in the surveying process. It can be used for both brightfield and fluorescence WSI. By using a 20X, 0.75 NA objective lens, we demonstrate a mean focusing error of ~0.08 microns in the static mode and ~0.17 microns in the continuous motion mode. The reported method may provide a turnkey solution for most existing WSI systems for its simplicity, robustness, accuracy, and high-speed. It may also standardize the imaging performance of WSI systems for digital pathology and find other applications in high-content microscopy such as DNA sequencing and time-lapse live-cell imaging.