 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatalyst4D: High-Fidelity 3D-to-4D Scene Editing via Dynamic Propagation
Mar 13, 2026Recent advances in 3D scene editing using NeRF and 3DGS enable high-quality static scene editing. In contrast, dynamic scene editing remains challenging, as methods that directly extend 2D diffusion models to 4D often produce motion artifacts, temporal flickering, and inconsistent style propagation. We introduce Catalyst4D, a framework that transfers high-quality 3D edits to dynamic 4D Gaussian scenes while maintaining spatial and temporal coherence. At its core, Anchor-based Motion Guidance (AMG) builds a set of structurally stable and spatially representative anchors from both original and edited Gaussians. These anchors serve as robust region-level references, and their correspondences are established via optimal transport to enable consistent deformation propagation without cross-region interference or motion drift. Complementarily, Color Uncertainty-guided Appearance Refinement (CUAR) preserves temporal appearance consistency by estimating per-Gaussian color uncertainty and selectively refining regions prone to occlusion-induced artifacts. Extensive experiments demonstrate that Catalyst4D achieves temporally stable, high-fidelity dynamic scene editing and outperforms existing methods in both visual quality and motion coherence.
Heterogeneous Multisource Transfer Learning via Model Averaging for Positive-Unlabeled Data
Nov 14, 2025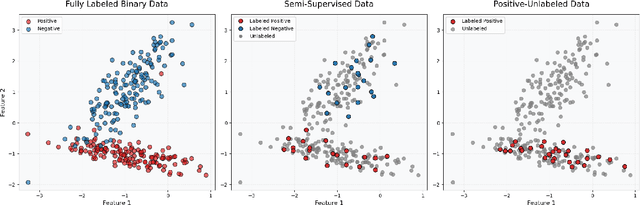
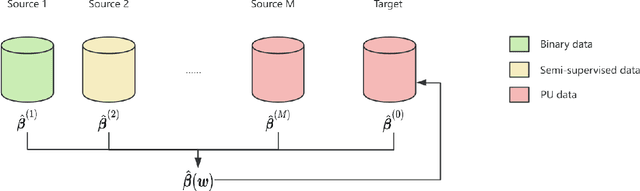
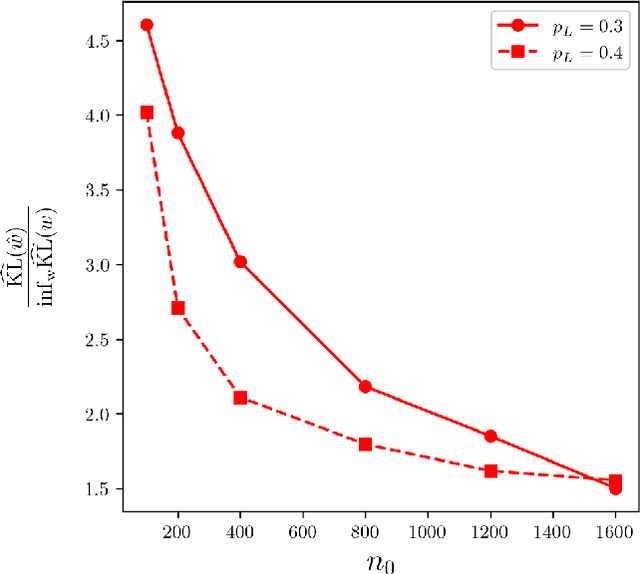
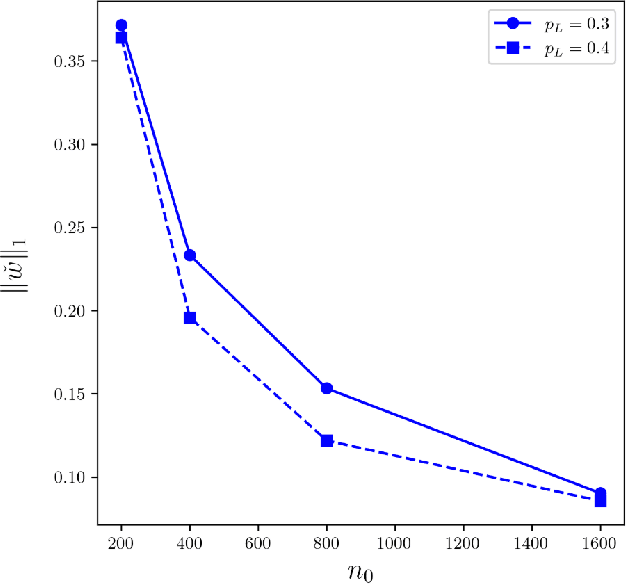
Positive-Unlabeled (PU) learning presents unique challenges due to the lack of explicitly labeled negative samples, particularly in high-stakes domains such as fraud detection and medical diagnosis. To address data scarcity and privacy constraints, we propose a novel transfer learning with model averaging framework that integrates information from heterogeneous data sources - including fully binary labeled, semi-supervised, and PU data sets - without direct data sharing. For each source domain type, a tailored logistic regression model is conducted, and knowledge is transferred to the PU target domain through model averaging. Optimal weights for combining source models are determined via a cross-validation criterion that minimizes the Kullback-Leibler divergence. We establish theoretical guarantees for weight optimality and convergence, covering both misspecified and correctly specified target models, with further extensions to high-dimensional settings using sparsity-penalized estimators. Extensive simulations and real-world credit risk data analyses demonstrate that our method outperforms other comparative methods in terms of predictive accuracy and robustness, especially under limited labeled data and heterogeneous environments.
Cross-Field Interface-Aware Neural Operators for Multiphase Flow Simulation
Nov 09, 2025Multiphase flow systems, with their complex dynamics, field discontinuities, and interphase interactions, pose significant computational challenges for traditional numerical solvers. While neural operators offer efficient alternatives, they often struggle to achieve high-resolution numerical accuracy in these systems. This limitation primarily stems from the inherent spatial heterogeneity and the scarcity of high-quality training data in multiphase flows. In this work, we propose the Interface Information-Aware Neural Operator (IANO), a novel framework that explicitly leverages interface information as a physical prior to enhance the prediction accuracy. The IANO architecture introduces two key components: 1) An interface-aware multiple function encoding mechanism jointly models multiple physical fields and interfaces, thus capturing the high-frequency physical features at the interface. 2) A geometry-aware positional encoding mechanism further establishes the relationship between interface information, physical variables, and spatial positions, enabling it to achieve pointwise super-resolution prediction even in the low-data regimes. Experimental results demonstrate that IANO outperforms baselines by $\sim$10\% in accuracy for multiphase flow simulations while maintaining robustness under data-scarce and noise-perturbed conditions.
Decomposing and Fusing Intra- and Inter-Sensor Spatio-Temporal Signal for Multi-Sensor Wearable Human Activity Recognition
Jan 19, 2025



Wearable Human Activity Recognition (WHAR) is a prominent research area within ubiquitous computing. Multi-sensor synchronous measurement has proven to be more effective for WHAR than using a single sensor. However, existing WHAR methods use shared convolutional kernels for indiscriminate temporal feature extraction across each sensor variable, which fails to effectively capture spatio-temporal relationships of intra-sensor and inter-sensor variables. We propose the DecomposeWHAR model consisting of a decomposition phase and a fusion phase to better model the relationships between modality variables. The decomposition creates high-dimensional representations of each intra-sensor variable through the improved Depth Separable Convolution to capture local temporal features while preserving their unique characteristics. The fusion phase begins by capturing relationships between intra-sensor variables and fusing their features at both the channel and variable levels. Long-range temporal dependencies are modeled using the State Space Model (SSM), and later cross-sensor interactions are dynamically captured through a self-attention mechanism, highlighting inter-sensor spatial correlations. Our model demonstrates superior performance on three widely used WHAR datasets, significantly outperforming state-of-the-art models while maintaining acceptable computational efficiency. Our codes and supplementary materials are available at https://github.com/Anakin2555/DecomposeWHAR.
Blind deblurring for microscopic pathology images using deep learning networks
Nov 24, 2020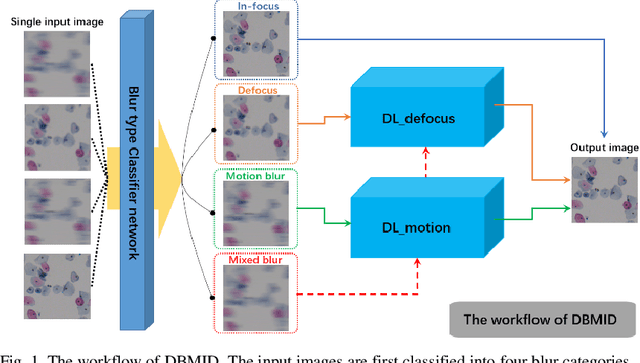
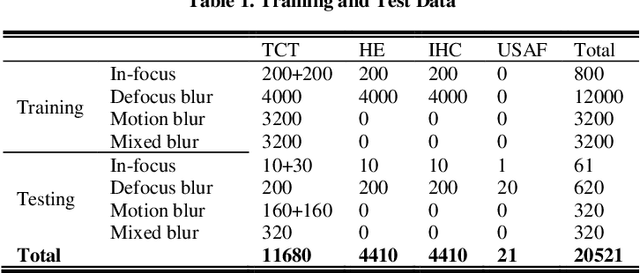
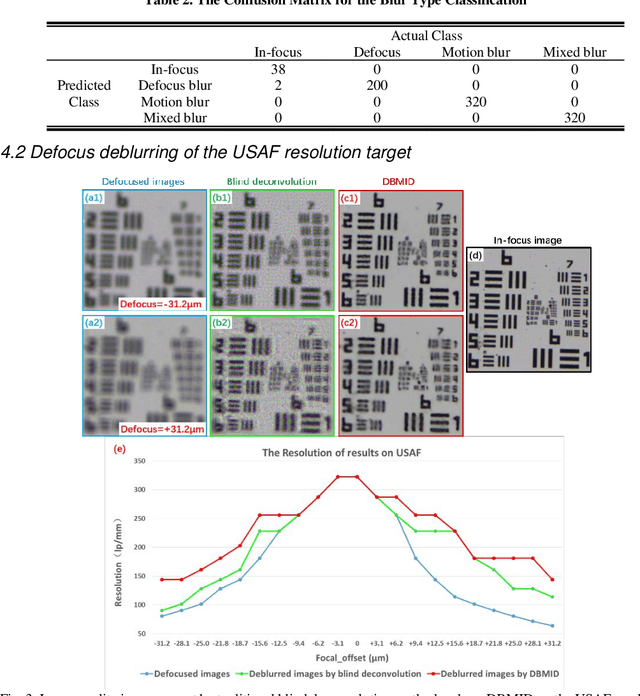
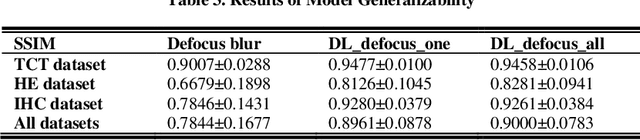
Artificial Intelligence (AI)-powered pathology is a revolutionary step in the world of digital pathology and shows great promise to increase both diagnosis accuracy and efficiency. However, defocus and motion blur can obscure tissue or cell characteristics hence compromising AI algorithms'accuracy and robustness in analyzing the images. In this paper, we demonstrate a deep-learning-based approach that can alleviate the defocus and motion blur of a microscopic image and output a sharper and cleaner image with retrieved fine details without prior knowledge of the blur type, blur extent and pathological stain. In this approach, a deep learning classifier is first trained to identify the image blur type. Then, two encoder-decoder networks are trained and used alone or in combination to deblur the input image. It is an end-to-end approach and introduces no corrugated artifacts as traditional blind deconvolution methods do. We test our approach on different types of pathology specimens and demonstrate great performance on image blur correction and the subsequent improvement on the diagnosis outcome of AI algorithms.
LoCEC: Local Community-based Edge Classification in Large Online Social Networks
Feb 11, 2020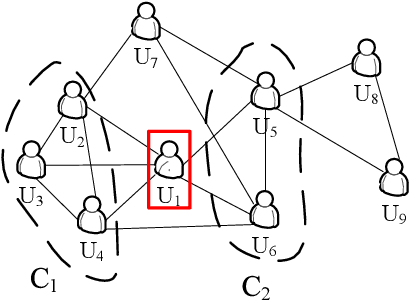
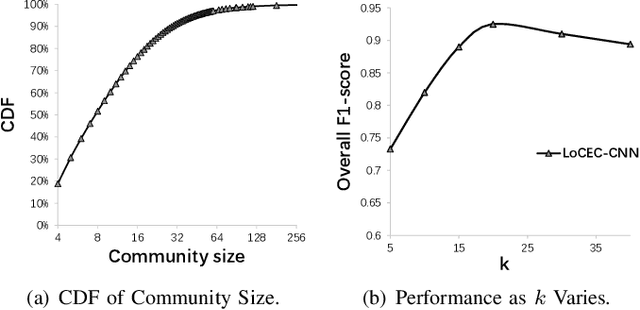
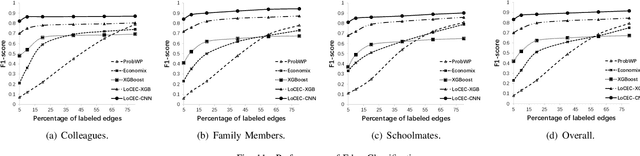
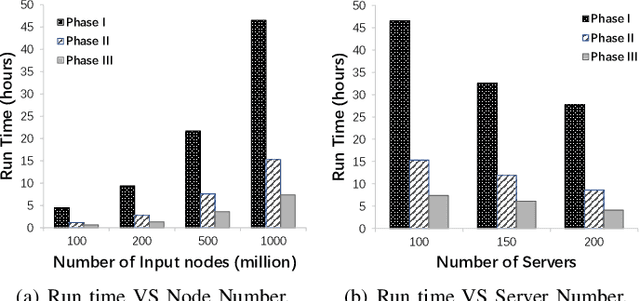
Relationships in online social networks often imply social connections in the real world. An accurate understanding of relationship types benefits many applications, e.g. social advertising and recommendation. Some recent attempts have been proposed to classify user relationships into predefined types with the help of pre-labeled relationships or abundant interaction features on relationships. Unfortunately, both relationship feature data and label data are very sparse in real social platforms like WeChat, rendering existing methods inapplicable. In this paper, we present an in-depth analysis of WeChat relationships to identify the major challenges for the relationship classification task. To tackle the challenges, we propose a Local Community-based Edge Classification (LoCEC) framework that classifies user relationships in a social network into real-world social connection types. LoCEC enforces a three-phase processing, namely local community detection, community classification and relationship classification, to address the sparsity issue of relationship features and relationship labels. Moreover, LoCEC is designed to handle large-scale networks by allowing parallel and distributed processing. We conduct extensive experiments on the real-world WeChat network with hundreds of billions of edges to validate the effectiveness and efficiency of LoCEC.
Predicting Long-Term Skeletal Motions by a Spatio-Temporal Hierarchical Recurrent Network
Nov 22, 2019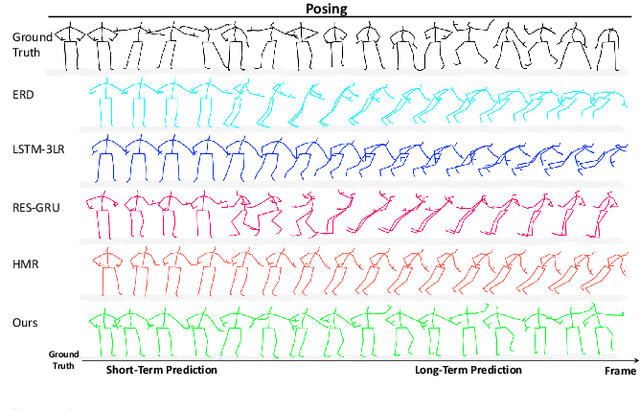
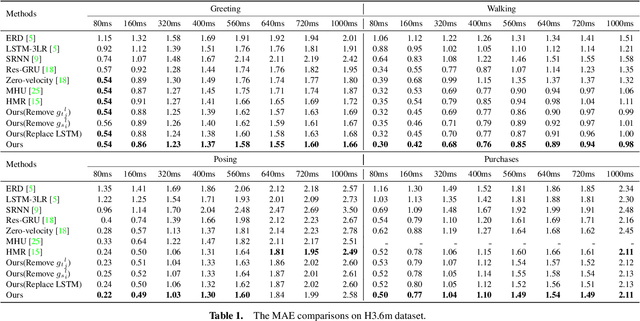
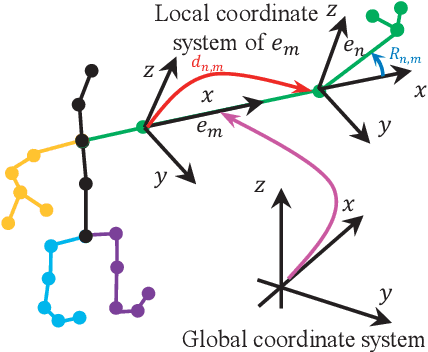
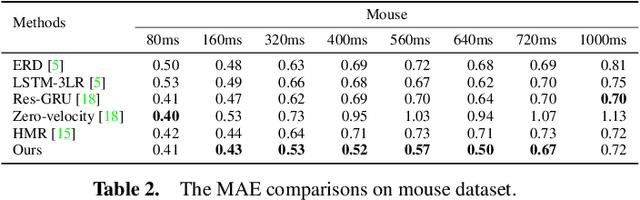
The primary goal of skeletal motion prediction is to generate future motion by observing a sequence of 3D skeletons. A key challenge in motion prediction is the fact that a motion can often be performed in several different ways, with each consisting of its own configuration of poses and their spatio-temporal dependencies, and as a result, the predicted poses often converge to the motionless poses or non-human like motions in long-term prediction. This leads us to define a hierarchical recurrent network model that explicitly characterizes these internal configurations of poses and their local and global spatio-temporal dependencies. The model introduces a latent vector variable from the Lie algebra to represent spatial and temporal relations simultaneously. Furthermore, a structured stack LSTM-based decoder is devised to decode the predicted poses with a new loss function defined to estimate the quantized weight of each body part in a pose. Empirical evaluations on benchmark datasets suggest our approach significantly outperforms the state-of-the-art methods on both short-term and long-term motion prediction.
Axially-shifted pattern illumination for macroscale turbidity suppression and virtual volumetric confocal imaging without axial scanning
Dec 14, 2018
Structured illumination has been widely used for optical sectioning and 3D surface recovery. In a typical implementation, multiple images under non-uniform pattern illumination are used to recover a single object section. Axial scanning of the sample or the objective lens is needed for acquiring the 3D volumetric data. Here we demonstrate the use of axially-shifted pattern illumination (asPI) for virtual volumetric confocal imaging without axial scanning. In the reported approach, we project illumination patterns at a tilted angle with respect to the detection optics. As such, the illumination patterns shift laterally at different z sections and the sample information at different z-sections can be recovered based on the captured 2D images. We demonstrate the reported approach for virtual confocal imaging through a diffusing layer and underwater 3D imaging through diluted milk. We show that we can acquire the entire confocal volume in ~1s with a throughput of 420 megapixels per second. Our approach may provide new insights for developing confocal light ranging and detection systems in degraded visual environments.
Solving Fourier ptychographic imaging problems via neural network modeling and TensorFlow
Mar 09, 2018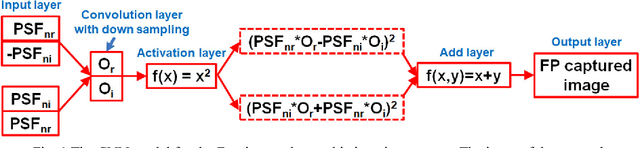


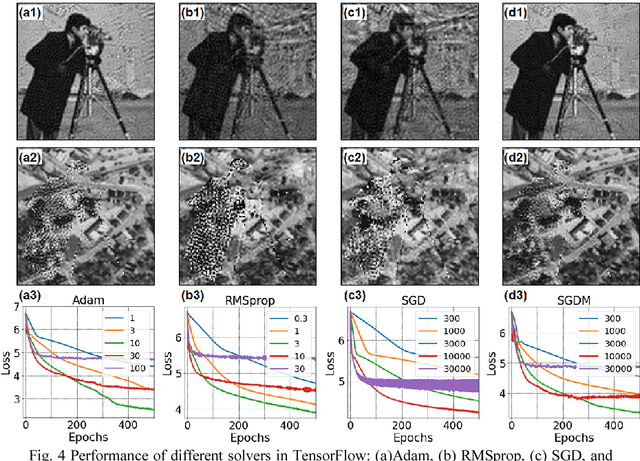
Fourier ptychography is a recently developed imaging approach for large field-of-view and high-resolution microscopy. Here we model the Fourier ptychographic forward imaging process using a convolution neural network (CNN) and recover the complex object information in the network training process. In this approach, the input of the network is the point spread function in the spatial domain or the coherent transfer function in the Fourier domain. The object is treated as 2D learnable weights of a convolution or a multiplication layer. The output of the network is modeled as the loss function we aim to minimize. The batch size of the network corresponds to the number of captured low-resolution images in one forward / backward pass. We use a popular open-source machine learning library, TensorFlow, for setting up the network and conducting the optimization process. We analyze the performance of different learning rates, different solvers, and different batch sizes. It is shown that a large batch size with the Adam optimizer achieves the best performance in general. To accelerate the phase retrieval process, we also discuss a strategy to implement Fourier-magnitude projection using a multiplication neural network model. Since convolution and multiplication are the two most-common operations in imaging modeling, the reported approach may provide a new perspective to examine many coherent and incoherent systems. As a demonstration, we discuss the extensions of the reported networks for modeling single-pixel imaging and structured illumination microscopy (SIM). 4-frame resolution doubling is demonstrated using a neural network for SIM. We have made our implementation code open-source for the broad research community.
Rapid focus map surveying for whole slide imaging with continues sample motion
Jul 06, 2017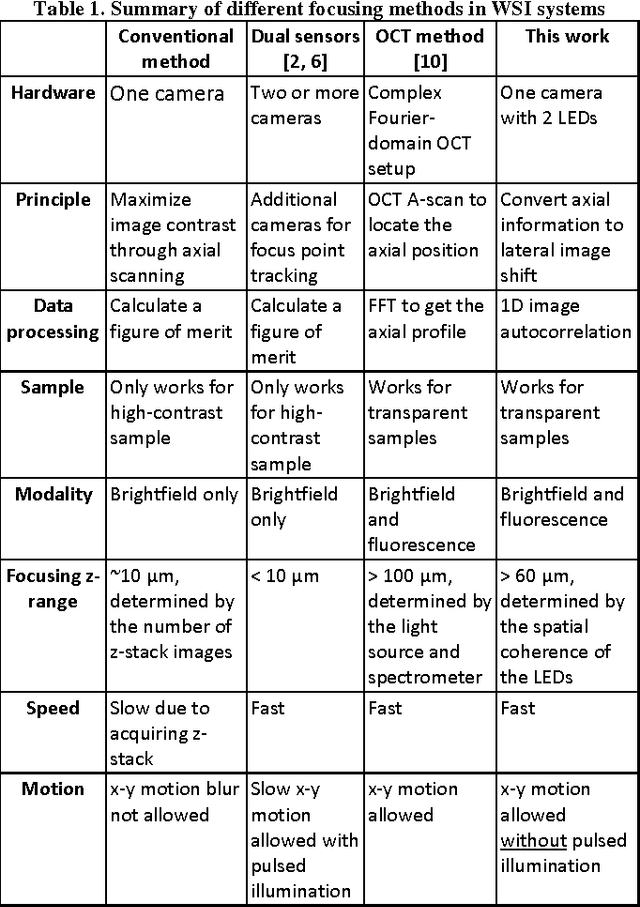
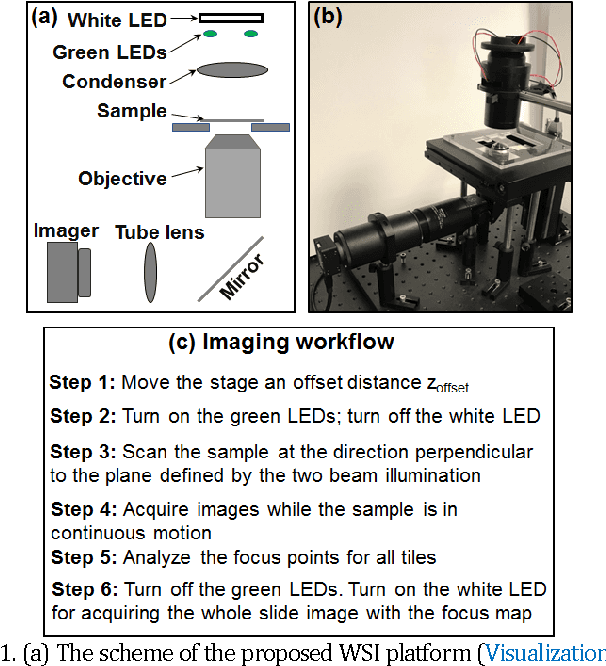
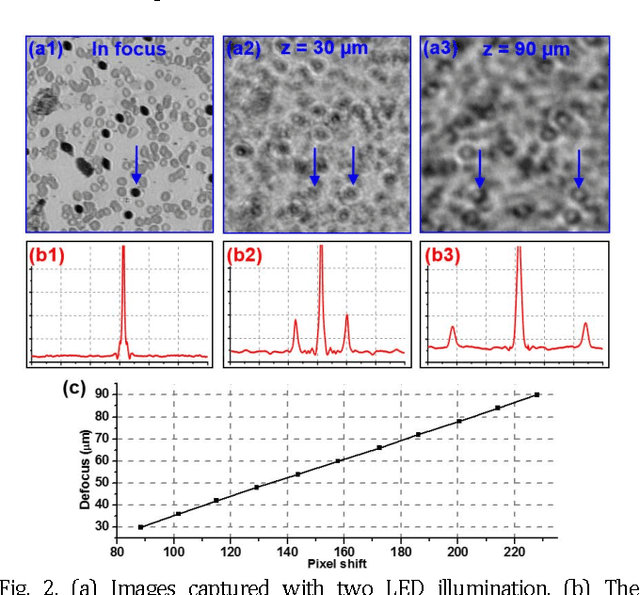
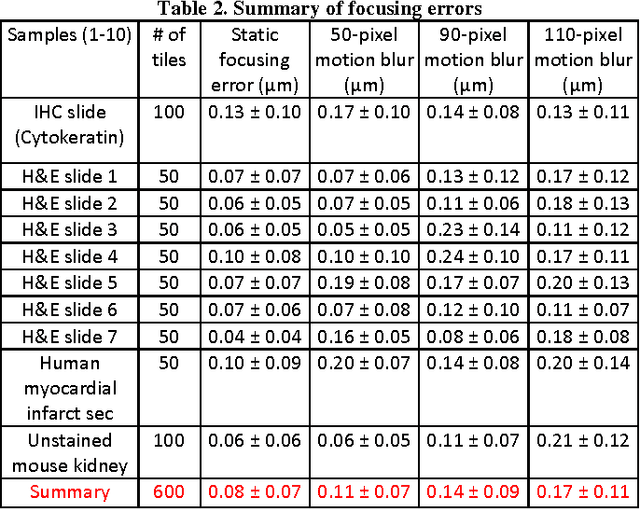
Whole slide imaging (WSI) has recently been cleared for primary diagnosis in the US. A critical challenge of WSI is to perform accurate focusing in high speed. Traditional systems create a focus map prior to scanning. For each focus point on the map, sample needs to be static in the x-y plane and axial scanning is needed to maximize the contrast. Here we report a novel focus map surveying method for WSI. The reported method requires no axial scanning, no additional camera and lens, works for stained and transparent samples, and allows continuous sample motion in the surveying process. It can be used for both brightfield and fluorescence WSI. By using a 20X, 0.75 NA objective lens, we demonstrate a mean focusing error of ~0.08 microns in the static mode and ~0.17 microns in the continuous motion mode. The reported method may provide a turnkey solution for most existing WSI systems for its simplicity, robustness, accuracy, and high-speed. It may also standardize the imaging performance of WSI systems for digital pathology and find other applications in high-content microscopy such as DNA sequencing and time-lapse live-cell imaging.