 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKSOD: Knowledge Supplement for LLMs On Demand
Mar 10, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks, yet still produce errors in domain-specific tasks. To further improve their performance, we propose KSOD (Knowledge Supplement for LLMs On Demand), a novel framework that empowers LLMs to improve their capabilities with knowledge-based supervised fine-tuning (SFT). KSOD analyzes the causes of errors from the perspective of knowledge deficiency by identifying potential missing knowledge in LLM that may lead to the errors. Subsequently, KSOD tunes a knowledge module on knowledge dataset and verifies whether the LLM lacks the identified knowledge based on it. If the knowledge is verified, KSOD supplements the LLM with the identified knowledge using the knowledge module. Tuning LLMs on specific knowledge instead of specific task decouples task and knowledge and our experiments on two domain-specific benchmarks and four general benchmarks empirically demonstrate that KSOD enhances the performance of LLMs on tasks requiring the supplemented knowledge while preserving their performance on other tasks. Our findings shed light on the potential of improving the capabilities of LLMs with knowledge-based SFT.
Prompt-Enhanced Spatio-Temporal Graph Transfer Learning
May 21, 2024Spatio-temporal graph neural networks have demonstrated efficacy in capturing complex dependencies for urban computing tasks such as forecasting and kriging. However, their performance is constrained by the reliance on extensive data for training on specific tasks, which limits their adaptability to new urban domains with varied demands. Although transfer learning has been proposed to address this problem by leveraging knowledge across domains, cross-task generalization remains underexplored in spatio-temporal graph transfer learning methods due to the absence of a unified framework. To bridge this gap, we propose Spatio-Temporal Graph Prompting (STGP), a prompt-enhanced transfer learning framework capable of adapting to diverse tasks in data-scarce domains. Specifically, we first unify different tasks into a single template and introduce a task-agnostic network architecture that aligns with this template. This approach enables the capture of spatio-temporal dependencies shared across tasks. Furthermore, we employ learnable prompts to achieve domain and task transfer in a two-stage prompting pipeline, enabling the prompts to effectively capture domain knowledge and task-specific properties at each stage. Extensive experiments demonstrate that STGP outperforms state-of-the-art baselines in three downstream tasks forecasting, kriging, and extrapolation by a notable margin.
UniTime: A Language-Empowered Unified Model for Cross-Domain Time Series Forecasting
Oct 28, 2023Multivariate time series forecasting plays a pivotal role in contemporary web technologies. In contrast to conventional methods that involve creating dedicated models for specific time series application domains, this research advocates for a unified model paradigm that transcends domain boundaries. However, learning an effective cross-domain model presents the following challenges. First, various domains exhibit disparities in data characteristics, e.g., the number of variables, posing hurdles for existing models that impose inflexible constraints on these factors. Second, the model may encounter difficulties in distinguishing data from various domains, leading to suboptimal performance in our assessments. Third, the diverse convergence rates of time series domains can also result in compromised empirical performance. To address these issues, we propose UniTime for effective cross-domain time series learning. Concretely, UniTime can flexibly adapt to data with varying characteristics. It also uses domain instructions and a Language-TS Transformer to offer identification information and align two modalities. In addition, UniTime employs masking to alleviate domain convergence speed imbalance issues. Our extensive experiments demonstrate the effectiveness of UniTime in advancing state-of-the-art forecasting performance and zero-shot transferability.
Towards Unifying Diffusion Models for Probabilistic Spatio-Temporal Graph Learning
Oct 26, 2023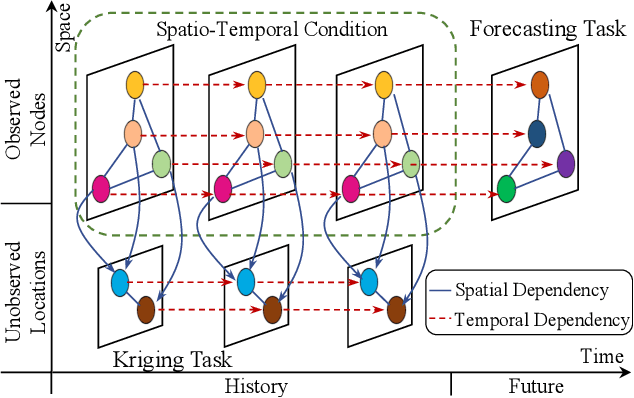



Spatio-temporal graph learning is a fundamental problem in the Web of Things era, which enables a plethora of Web applications such as smart cities, human mobility and climate analysis. Existing approaches tackle different learning tasks independently, tailoring their models to unique task characteristics. These methods, however, fall short of modeling intrinsic uncertainties in the spatio-temporal data. Meanwhile, their specialized designs limit their universality as general spatio-temporal learning solutions. In this paper, we propose to model the learning tasks in a unified perspective, viewing them as predictions based on conditional information with shared spatio-temporal patterns. Based on this proposal, we introduce Unified Spatio-Temporal Diffusion Models (USTD) to address the tasks uniformly within the uncertainty-aware diffusion framework. USTD is holistically designed, comprising a shared spatio-temporal encoder and attention-based denoising networks that are task-specific. The shared encoder, optimized by a pre-training strategy, effectively captures conditional spatio-temporal patterns. The denoising networks, utilizing both cross- and self-attention, integrate conditional dependencies and generate predictions. Opting for forecasting and kriging as downstream tasks, we design Gated Attention (SGA) and Temporal Gated Attention (TGA) for each task, with different emphases on the spatial and temporal dimensions, respectively. By combining the advantages of deterministic encoders and probabilistic diffusion models, USTD achieves state-of-the-art performances compared to deterministic and probabilistic baselines in both tasks, while also providing valuable uncertainty estimates.
LargeST: A Benchmark Dataset for Large-Scale Traffic Forecasting
Jun 14, 2023
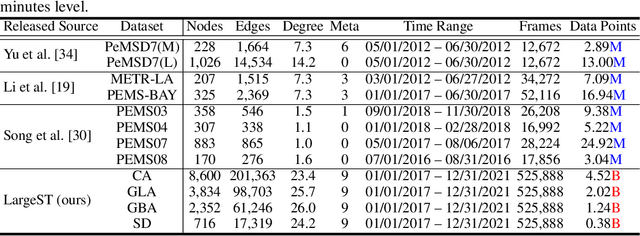


Traffic forecasting plays a critical role in smart city initiatives and has experienced significant advancements thanks to the power of deep learning in capturing non-linear patterns of traffic data. However, the promising results achieved on current public datasets may not be applicable to practical scenarios due to limitations within these datasets. First, the limited sizes of them may not reflect the real-world scale of traffic networks. Second, the temporal coverage of these datasets is typically short, posing hurdles in studying long-term patterns and acquiring sufficient samples for training deep models. Third, these datasets often lack adequate metadata for sensors, which compromises the reliability and interpretability of the data. To mitigate these limitations, we introduce the LargeST benchmark dataset. It encompasses a total number of 8,600 sensors with a 5-year time coverage and includes comprehensive metadata. Using LargeST, we perform in-depth data analysis to extract data insights, benchmark well-known baselines in terms of their performance and efficiency, and identify challenges as well as opportunities for future research. We release the datasets and baseline implementations at: https://github.com/liuxu77/LargeST.
Graph Neural Processes for Spatio-Temporal Extrapolation
May 30, 2023

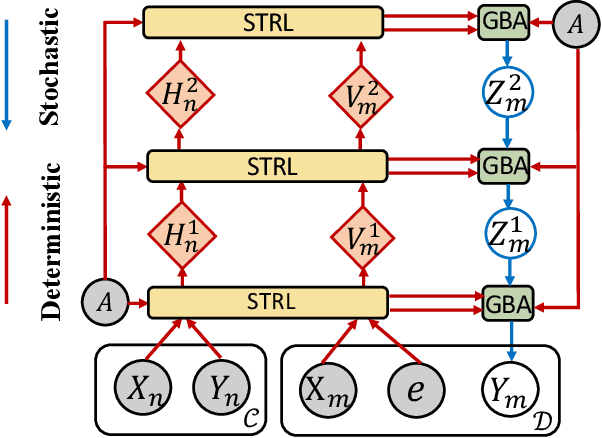

We study the task of spatio-temporal extrapolation that generates data at target locations from surrounding contexts in a graph. This task is crucial as sensors that collect data are sparsely deployed, resulting in a lack of fine-grained information due to high deployment and maintenance costs. Existing methods either use learning-based models like Neural Networks or statistical approaches like Gaussian Processes for this task. However, the former lacks uncertainty estimates and the latter fails to capture complex spatial and temporal correlations effectively. To address these issues, we propose Spatio-Temporal Graph Neural Processes (STGNP), a neural latent variable model which commands these capabilities simultaneously. Specifically, we first learn deterministic spatio-temporal representations by stacking layers of causal convolutions and cross-set graph neural networks. Then, we learn latent variables for target locations through vertical latent state transitions along layers and obtain extrapolations. Importantly during the transitions, we propose Graph Bayesian Aggregation (GBA), a Bayesian graph aggregator that aggregates contexts considering uncertainties in context data and graph structure. Extensive experiments show that STGNP has desirable properties such as uncertainty estimates and strong learning capabilities, and achieves state-of-the-art results by a clear margin.
Decoupling Long- and Short-Term Patterns in Spatiotemporal Inference
Sep 16, 2021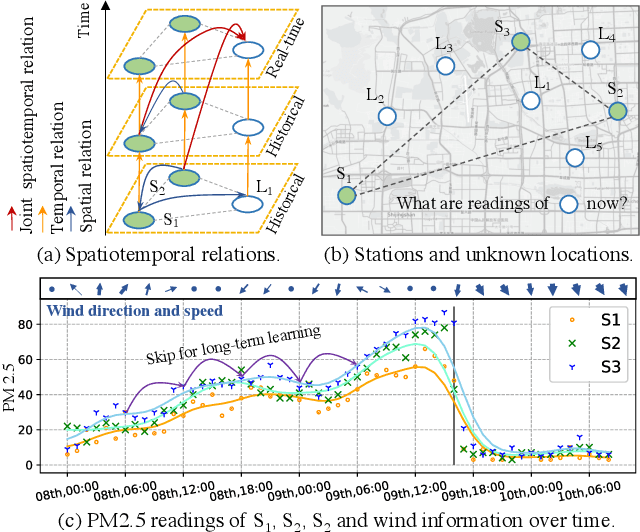
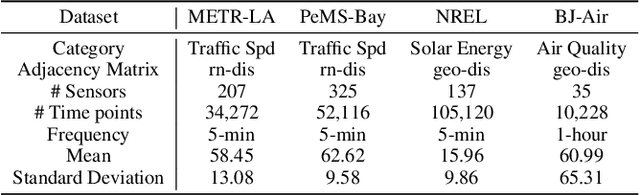


Sensors are the key to sensing the environment and imparting benefits to smart cities in many aspects, such as providing real-time air quality information throughout an urban area. However, a prerequisite is to obtain fine-grained knowledge of the environment. There is a limit to how many sensors can be installed in the physical world due to non-negligible expenses. In this paper, we propose to infer real-time information of any given location in a city based on historical and current observations from the available sensors (termed spatiotemporal inference). Our approach decouples the modeling of short-term and long-term patterns, relying on two major components. Firstly, unlike previous studies that separated the spatial and temporal relation learning, we introduce a joint spatiotemporal graph attention network that learns the short-term dependencies across both the spatial and temporal dimensions. Secondly, we propose an adaptive graph recurrent network with a time skip for capturing long-term patterns. The adaptive adjacency matrices are learned inductively first as the inputs of a recurrent network to learn dynamic dependencies. Experimental results on four public read-world datasets show that our method reduces state-of-the-art baseline mean absolute errors by 5%~12%.
Unsupervised Domain Adaptation Network with Category-Centric Prototype Aligner for Biomedical Image Segmentation
Mar 03, 2021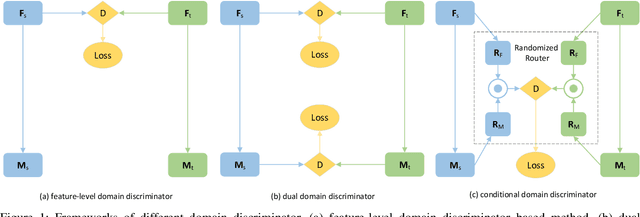
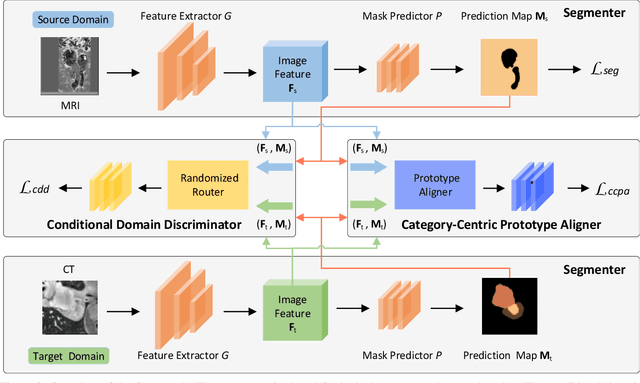
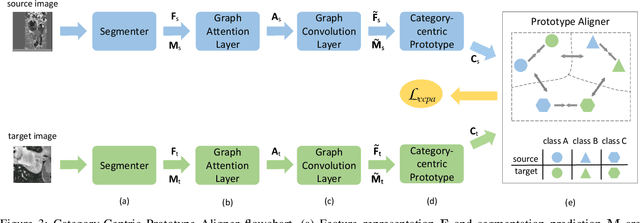
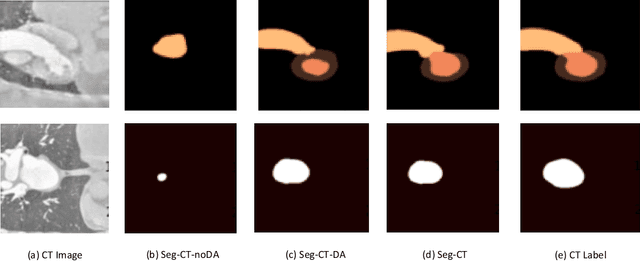
With the widespread success of deep learning in biomedical image segmentation, domain shift becomes a critical and challenging problem, as the gap between two domains can severely affect model performance when deployed to unseen data with heterogeneous features. To alleviate this problem, we present a novel unsupervised domain adaptation network, for generalizing models learned from the labeled source domain to the unlabeled target domain for cross-modality biomedical image segmentation. Specifically, our approach consists of two key modules, a conditional domain discriminator~(CDD) and a category-centric prototype aligner~(CCPA). The CDD, extended from conditional domain adversarial networks in classifier tasks, is effective and robust in handling complex cross-modality biomedical images. The CCPA, improved from the graph-induced prototype alignment mechanism in cross-domain object detection, can exploit precise instance-level features through an elaborate prototype representation. In addition, it can address the negative effect of class imbalance via entropy-based loss. Extensive experiments on a public benchmark for the cardiac substructure segmentation task demonstrate that our method significantly improves performance on the target domain.
Incorporate Semantic Structures into Machine Translation Evaluation via UCCA
Oct 22, 2020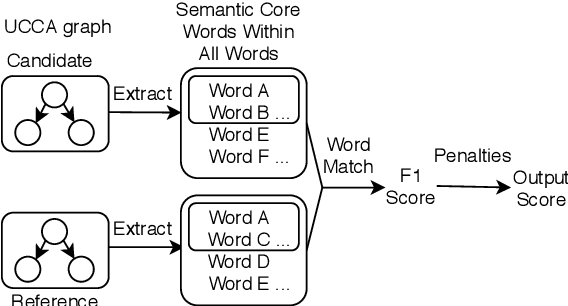

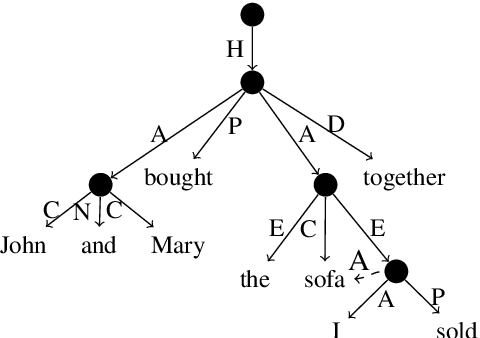

Copying mechanism has been commonly used in neural paraphrasing networks and other text generation tasks, in which some important words in the input sequence are preserved in the output sequence. Similarly, in machine translation, we notice that there are certain words or phrases appearing in all good translations of one source text, and these words tend to convey important semantic information. Therefore, in this work, we define words carrying important semantic meanings in sentences as semantic core words. Moreover, we propose an MT evaluation approach named Semantically Weighted Sentence Similarity (SWSS). It leverages the power of UCCA to identify semantic core words, and then calculates sentence similarity scores on the overlap of semantic core words. Experimental results show that SWSS can consistently improve the performance of popular MT evaluation metrics which are based on lexical similarity.
Evaluation of company investment value based on machine learning
Sep 30, 2020
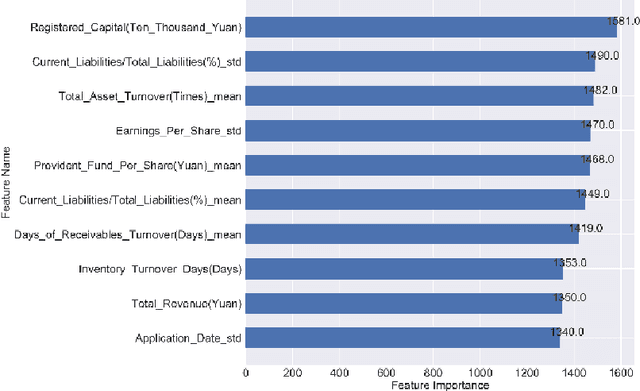
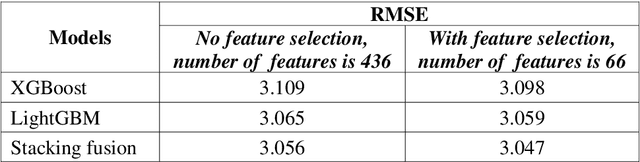
In this paper, company investment value evaluation models are established based on comprehensive company information. After data mining and extracting a set of 436 feature parameters, an optimal subset of features is obtained by dimension reduction through tree-based feature selection, followed by the 5-fold cross-validation using XGBoost and LightGBM models. The results show that the Root-Mean-Square Error (RMSE) reached 3.098 and 3.059, respectively. In order to further improve the stability and generalization capability, Bayesian Ridge Regression has been used to train a stacking model based on the XGBoost and LightGBM models. The corresponding RMSE is up to 3.047. Finally, the importance of different features to the LightGBM model is analysed.