 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnon: Extrapolating Adaptivity Beyond SGD and Adam
May 06, 2026Adaptive optimizers such as Adam have achieved great success in training large-scale models like large language models and diffusion models. However, they often generalize worse than non-adaptive methods, such as SGD on classical architectures like CNNs. We identify a key cause of this performance gap: adaptivity in pre-conditioners, which limits the optimizer's ability to adapt to diverse optimization landscapes. To address this, we propose Anon (Adaptivity Non-restricted Optimizer with Novel convergence technique), a novel optimizer with continuously tunable adaptivity in R, allowing it to interpolate between SGD-like and Adam-like behaviors and even extrapolate beyond both. To ensure convergence across the entire adaptivity spectrum, we introduce incremental delay update (IDU), a novel mechanism that is more flexible than AMSGrad's hard max-tracking strategy and enhances robustness to gradient noise. We theoretically establish convergence guarantees under both convex and non-convex settings. Empirically, Anon consistently outperforms state-of-the-art optimizers on representative image classification, diffusion, and language modeling tasks. These results demonstrate that adaptivity can serve as a valuable tunable design principle, and Anon provides the first unified and reliable framework capable of bridging the gap between classical and modern optimizers and surpassing their advantageous properties.
CLIPPan: Adapting CLIP as A Supervisor for Unsupervised Pansharpening
Nov 14, 2025Despite remarkable advancements in supervised pansharpening neural networks, these methods face domain adaptation challenges of resolution due to the intrinsic disparity between simulated reduced-resolution training data and real-world full-resolution scenarios.To bridge this gap, we propose an unsupervised pansharpening framework, CLIPPan, that enables model training at full resolution directly by taking CLIP, a visual-language model, as a supervisor. However, directly applying CLIP to supervise pansharpening remains challenging due to its inherent bias toward natural images and limited understanding of pansharpening tasks. Therefore, we first introduce a lightweight fine-tuning pipeline that adapts CLIP to recognize low-resolution multispectral, panchromatic, and high-resolution multispectral images, as well as to understand the pansharpening process. Then, building on the adapted CLIP, we formulate a novel \textit{loss integrating semantic language constraints}, which aligns image-level fusion transitions with protocol-aligned textual prompts (e.g., Wald's or Khan's descriptions), thus enabling CLIPPan to use language as a powerful supervisory signal and guide fusion learning without ground truth. Extensive experiments demonstrate that CLIPPan consistently improves spectral and spatial fidelity across various pansharpening backbones on real-world datasets, setting a new state of the art for unsupervised full-resolution pansharpening.
ARIW-Framework: Adaptive Robust Iterative Watermarking Framework
May 19, 2025With the rapid rise of large models, copyright protection for generated image content has become a critical security challenge. Although deep learning watermarking techniques offer an effective solution for digital image copyright protection, they still face limitations in terms of visual quality, robustness and generalization. To address these issues, this paper proposes an adaptive robust iterative watermarking framework (ARIW-Framework) that achieves high-quality watermarked images while maintaining exceptional robustness and generalization performance. Specifically, we introduce an iterative approach to optimize the encoder for generating robust residuals. The encoder incorporates noise layers and a decoder to compute robustness weights for residuals under various noise attacks. By employing a parallel optimization strategy, the framework enhances robustness against multiple types of noise attacks. Furthermore, we leverage image gradients to determine the embedding strength at each pixel location, significantly improving the visual quality of the watermarked images. Extensive experiments demonstrate that the proposed method achieves superior visual quality while exhibiting remarkable robustness and generalization against noise attacks.
Rethinking Cross-Attention for Infrared and Visible Image Fusion
Jan 22, 2024The salient information of an infrared image and the abundant texture of a visible image can be fused to obtain a comprehensive image. As can be known, the current fusion methods based on Transformer techniques for infrared and visible (IV) images have exhibited promising performance. However, the attention mechanism of the previous Transformer-based methods was prone to extract common information from source images without considering the discrepancy information, which limited fusion performance. In this paper, by reevaluating the cross-attention mechanism, we propose an alternate Transformer fusion network (ATFuse) to fuse IV images. Our ATFuse consists of one discrepancy information injection module (DIIM) and two alternate common information injection modules (ACIIM). The DIIM is designed by modifying the vanilla cross-attention mechanism, which can promote the extraction of the discrepancy information of the source images. Meanwhile, the ACIIM is devised by alternately using the vanilla cross-attention mechanism, which can fully mine common information and integrate long dependencies. Moreover, the successful training of ATFuse is facilitated by a proposed segmented pixel loss function, which provides a good trade-off for texture detail and salient structure preservation. The qualitative and quantitative results on public datasets indicate our ATFFuse is effective and superior compared to other state-of-the-art methods.
Evaluation of company investment value based on machine learning
Sep 30, 2020
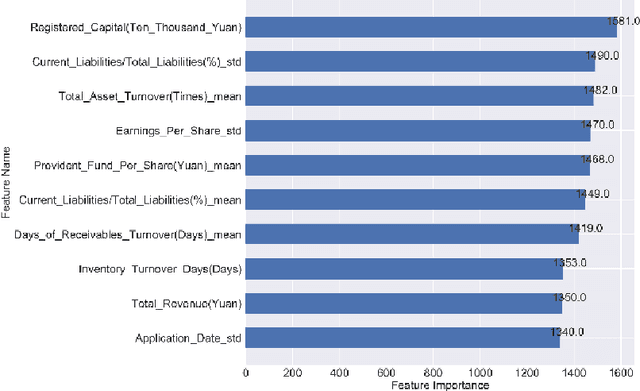
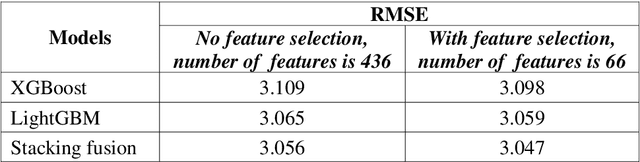
In this paper, company investment value evaluation models are established based on comprehensive company information. After data mining and extracting a set of 436 feature parameters, an optimal subset of features is obtained by dimension reduction through tree-based feature selection, followed by the 5-fold cross-validation using XGBoost and LightGBM models. The results show that the Root-Mean-Square Error (RMSE) reached 3.098 and 3.059, respectively. In order to further improve the stability and generalization capability, Bayesian Ridge Regression has been used to train a stacking model based on the XGBoost and LightGBM models. The corresponding RMSE is up to 3.047. Finally, the importance of different features to the LightGBM model is analysed.