 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPPan: Adapting CLIP as A Supervisor for Unsupervised Pansharpening
Nov 14, 2025Despite remarkable advancements in supervised pansharpening neural networks, these methods face domain adaptation challenges of resolution due to the intrinsic disparity between simulated reduced-resolution training data and real-world full-resolution scenarios.To bridge this gap, we propose an unsupervised pansharpening framework, CLIPPan, that enables model training at full resolution directly by taking CLIP, a visual-language model, as a supervisor. However, directly applying CLIP to supervise pansharpening remains challenging due to its inherent bias toward natural images and limited understanding of pansharpening tasks. Therefore, we first introduce a lightweight fine-tuning pipeline that adapts CLIP to recognize low-resolution multispectral, panchromatic, and high-resolution multispectral images, as well as to understand the pansharpening process. Then, building on the adapted CLIP, we formulate a novel \textit{loss integrating semantic language constraints}, which aligns image-level fusion transitions with protocol-aligned textual prompts (e.g., Wald's or Khan's descriptions), thus enabling CLIPPan to use language as a powerful supervisory signal and guide fusion learning without ground truth. Extensive experiments demonstrate that CLIPPan consistently improves spectral and spatial fidelity across various pansharpening backbones on real-world datasets, setting a new state of the art for unsupervised full-resolution pansharpening.
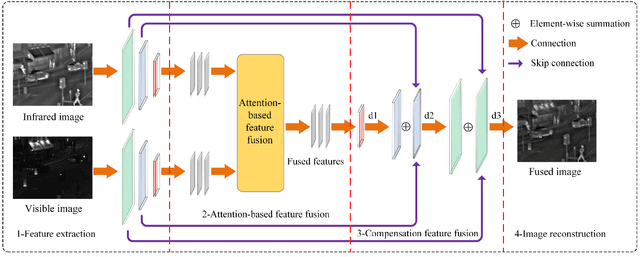
Rethinking Cross-Attention for Infrared and Visible Image Fusion
Jan 22, 2024The salient information of an infrared image and the abundant texture of a visible image can be fused to obtain a comprehensive image. As can be known, the current fusion methods based on Transformer techniques for infrared and visible (IV) images have exhibited promising performance. However, the attention mechanism of the previous Transformer-based methods was prone to extract common information from source images without considering the discrepancy information, which limited fusion performance. In this paper, by reevaluating the cross-attention mechanism, we propose an alternate Transformer fusion network (ATFuse) to fuse IV images. Our ATFuse consists of one discrepancy information injection module (DIIM) and two alternate common information injection modules (ACIIM). The DIIM is designed by modifying the vanilla cross-attention mechanism, which can promote the extraction of the discrepancy information of the source images. Meanwhile, the ACIIM is devised by alternately using the vanilla cross-attention mechanism, which can fully mine common information and integrate long dependencies. Moreover, the successful training of ATFuse is facilitated by a proposed segmented pixel loss function, which provides a good trade-off for texture detail and salient structure preservation. The qualitative and quantitative results on public datasets indicate our ATFFuse is effective and superior compared to other state-of-the-art methods.
A Symmetric Encoder-Decoder with Residual Block for Infrared and Visible Image Fusion
May 27, 2019

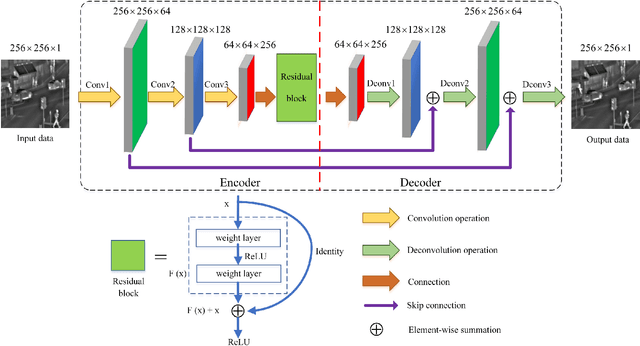
In computer vision and image processing tasks, image fusion has evolved into an attractive research field. However, recent existing image fusion methods are mostly built on pixel-level operations, which may produce unacceptable artifacts and are time-consuming. In this paper, a symmetric encoder-decoder with a residual block (SEDR) for infrared and visible image fusion is proposed. For the training stage, the SEDR network is trained with a new dataset to obtain a fixed feature extractor. For the fusion stage, first, the trained model is utilized to extract the intermediate features and compensation features of two source images. Then, extracted intermediate features are used to generate two attention maps, which are multiplied to the input features for refinement. In addition, the compensation features generated by the first two convolutional layers are merged and passed to the corresponding deconvolutional layers. At last, the refined features are fused for decoding to reconstruct the final fused image. Experimental results demonstrate that the proposed fusion method (named as SEDRFuse) outperforms the state-of-the-art fusion methods in terms of both subjective and objective evaluations.
Towards end-to-end pulsed eddy current classification and regression with CNN
Feb 22, 2019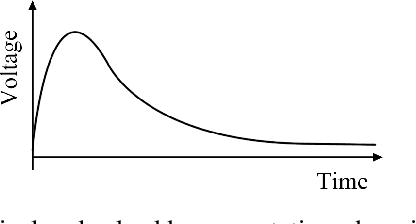
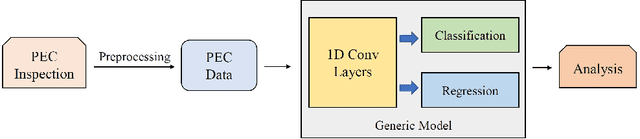
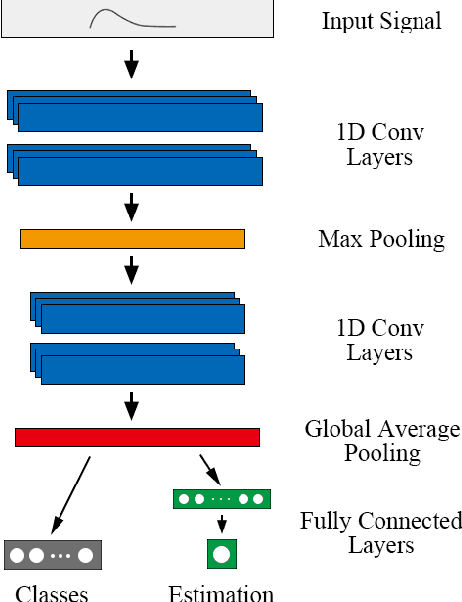
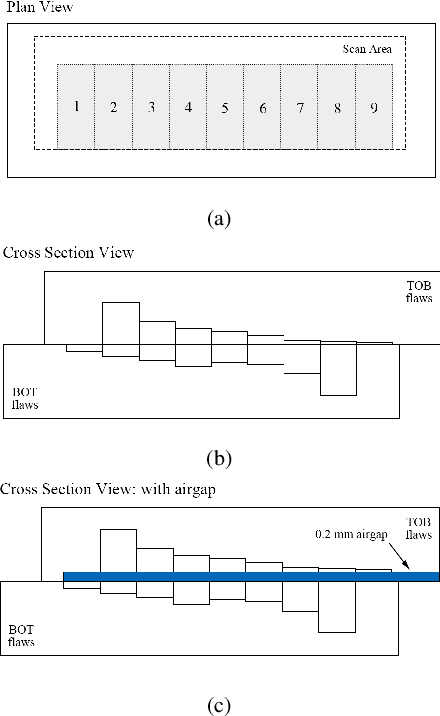
Pulsed eddy current (PEC) is an effective electromagnetic non-destructive inspection (NDI) technique for metal materials, which has already been widely adopted in detecting cracking and corrosion in some multi-layer structures. Automatically inspecting the defects in these structures would be conducive to further analysis and treatment of them. In this paper, we propose an effective end-to-end model using convolutional neural networks (CNN) to learn effective features from PEC data. Specifically, we construct a multi-task generic model, based on 1D CNN, to predict both the class and depth of flaws simultaneously. Extensive experiments demonstrate our model is capable of handling both classification and regression tasks on PEC data. Our proposed model obtains higher accuracy and lower error compared to other standard methods.