 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Symmetric Encoder-Decoder with Residual Block for Infrared and Visible Image Fusion
May 27, 2019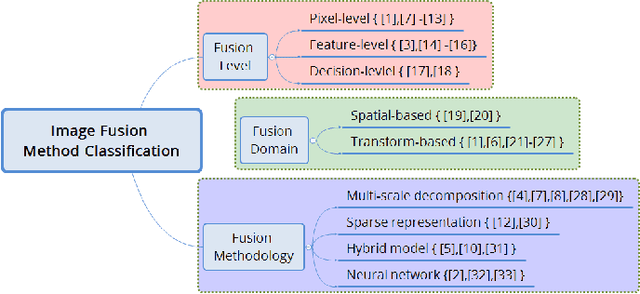

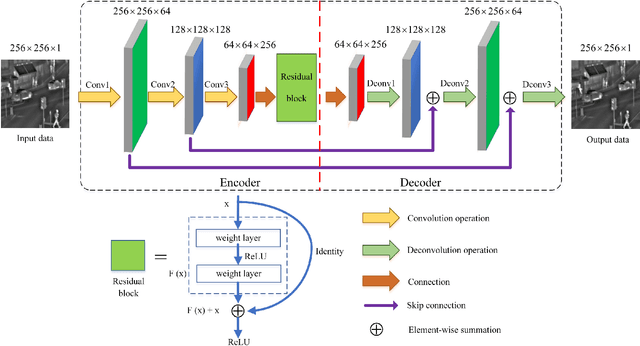
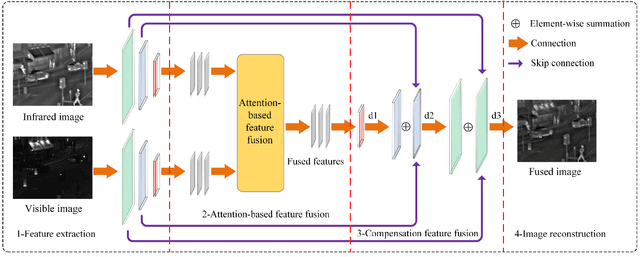
In computer vision and image processing tasks, image fusion has evolved into an attractive research field. However, recent existing image fusion methods are mostly built on pixel-level operations, which may produce unacceptable artifacts and are time-consuming. In this paper, a symmetric encoder-decoder with a residual block (SEDR) for infrared and visible image fusion is proposed. For the training stage, the SEDR network is trained with a new dataset to obtain a fixed feature extractor. For the fusion stage, first, the trained model is utilized to extract the intermediate features and compensation features of two source images. Then, extracted intermediate features are used to generate two attention maps, which are multiplied to the input features for refinement. In addition, the compensation features generated by the first two convolutional layers are merged and passed to the corresponding deconvolutional layers. At last, the refined features are fused for decoding to reconstruct the final fused image. Experimental results demonstrate that the proposed fusion method (named as SEDRFuse) outperforms the state-of-the-art fusion methods in terms of both subjective and objective evaluations.