 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAE MobiLLM: Privacy-Aware and Efficient LLM Fine-Tuning on the Mobile Device via Additive Side-Tuning
Jul 01, 2025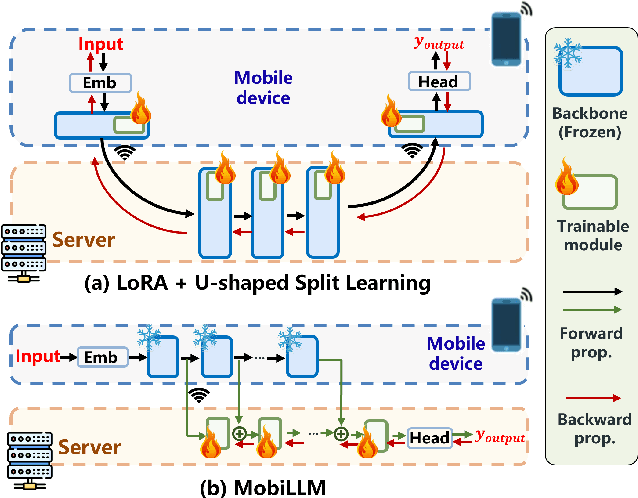
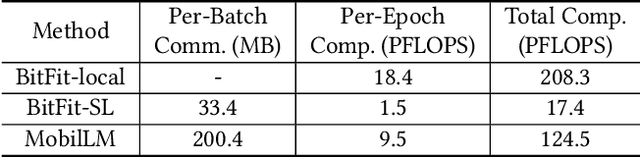
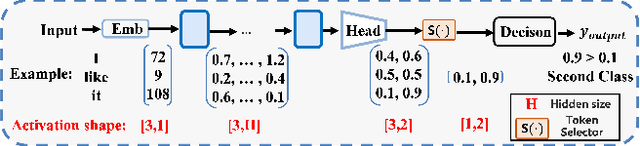
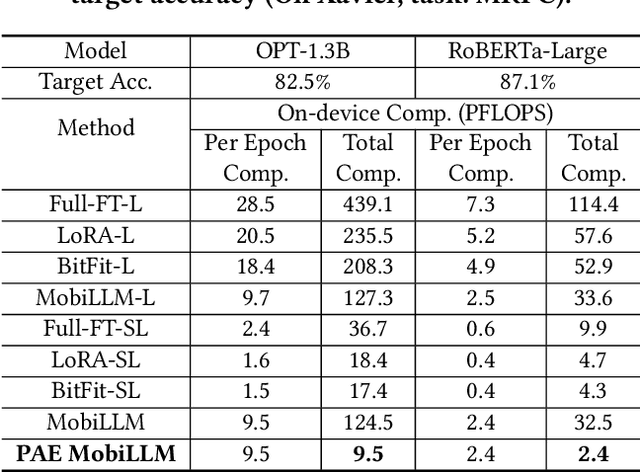
There is a huge gap between numerous intriguing applications fostered by on-device large language model (LLM) fine-tuning (FT) from fresh mobile data and the limited resources of a mobile device. While existing server-assisted methods (e.g., split learning or side-tuning) may enable LLM FT on the local mobile device, they suffer from heavy communication burdens of activation transmissions, and may disclose data, labels or fine-tuned models to the server. To address those issues, we develop PAE MobiLLM, a privacy-aware and efficient LLM FT method which can be deployed on the mobile device via server-assisted additive side-tuning. To further accelerate FT convergence and improve computing efficiency, PAE MobiLLM integrates activation caching on the server side, which allows the server to reuse historical activations and saves the mobile device from repeatedly computing forward passes for the recurring data samples. Besides, to reduce communication cost, PAE MobiLLM develops a one-token (i.e., ``pivot'' token) activation shortcut that transmits only a single activation dimension instead of full activation matrices to guide the side network tuning. Last but not least, PAE MobiLLM introduces the additive adapter side-network design which makes the server train the adapter modules based on device-defined prediction differences rather than raw ground-truth labels. In this way, the server can only assist device-defined side-network computing, and learn nothing about data, labels or fine-tuned models.
NeuroMoE: A Transformer-Based Mixture-of-Experts Framework for Multi-Modal Neurological Disorder Classification
Jun 17, 2025The integration of multi-modal Magnetic Resonance Imaging (MRI) and clinical data holds great promise for enhancing the diagnosis of neurological disorders (NDs) in real-world clinical settings. Deep Learning (DL) has recently emerged as a powerful tool for extracting meaningful patterns from medical data to aid in diagnosis. However, existing DL approaches struggle to effectively leverage multi-modal MRI and clinical data, leading to suboptimal performance. To address this challenge, we utilize a unique, proprietary multi-modal clinical dataset curated for ND research. Based on this dataset, we propose a novel transformer-based Mixture-of-Experts (MoE) framework for ND classification, leveraging multiple MRI modalities-anatomical (aMRI), Diffusion Tensor Imaging (DTI), and functional (fMRI)-alongside clinical assessments. Our framework employs transformer encoders to capture spatial relationships within volumetric MRI data while utilizing modality-specific experts for targeted feature extraction. A gating mechanism with adaptive fusion dynamically integrates expert outputs, ensuring optimal predictive performance. Comprehensive experiments and comparisons with multiple baselines demonstrate that our multi-modal approach significantly enhances diagnostic accuracy, particularly in distinguishing overlapping disease states. Our framework achieves a validation accuracy of 82.47\%, outperforming baseline methods by over 10\%, highlighting its potential to improve ND diagnosis by applying multi-modal learning to real-world clinical data.
MobiLLM: Enabling LLM Fine-Tuning on the Mobile Device via Server Assisted Side Tuning
Feb 27, 2025
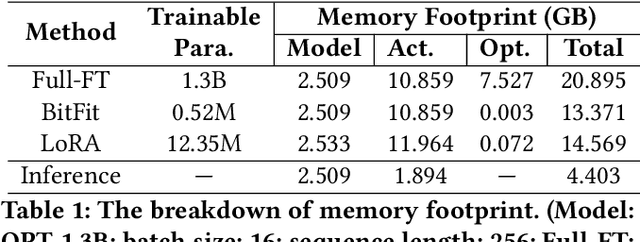
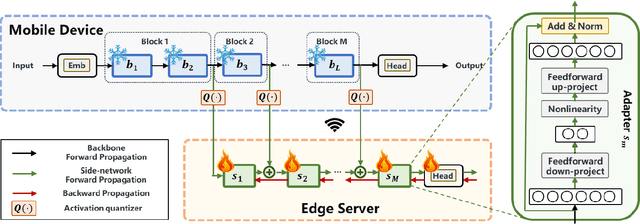
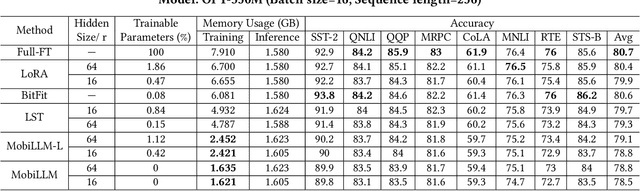
Large Language Model (LLM) at mobile devices and its potential applications never fail to fascinate. However, on-device LLM fine-tuning poses great challenges due to extremely high memory requirements and slow training speeds. Even with parameter-efficient fine-tuning (PEFT) methods that update only a small subset of parameters, resource-constrained mobile devices cannot afford them. In this paper, we propose MobiLLM to enable memory-efficient transformer LLM fine-tuning on a mobile device via server-assisted side-tuning. Particularly, MobiLLM allows the resource-constrained mobile device to retain merely a frozen backbone model, while offloading the memory and computation-intensive backpropagation of a trainable side-network to a high-performance server. Unlike existing fine-tuning methods that keep trainable parameters inside the frozen backbone, MobiLLM separates a set of parallel adapters from the backbone to create a backpropagation bypass, involving only one-way activation transfers from the mobile device to the server with low-width quantization during forward propagation. In this way, the data never leaves the mobile device while the device can remove backpropagation through the local backbone model and its forward propagation can be paralyzed with the server-side execution. Thus, MobiLLM preserves data privacy while significantly reducing the memory and computational burdens for LLM fine-tuning. Through extensive experiments, we demonstrate that MobiLLM can enable a resource-constrained mobile device, even a CPU-only one, to fine-tune LLMs and significantly reduce convergence time and memory usage.
Multi-Grained Preference Enhanced Transformer for Multi-Behavior Sequential Recommendation
Nov 19, 2024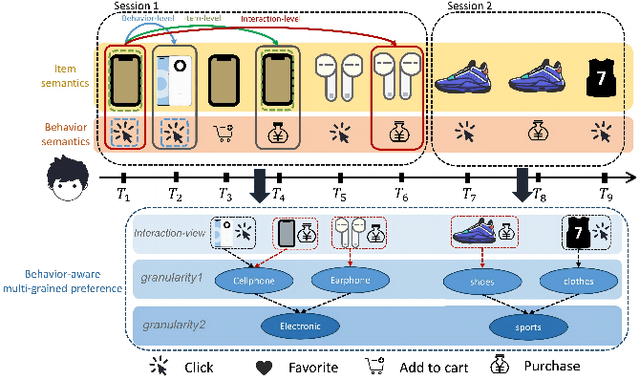
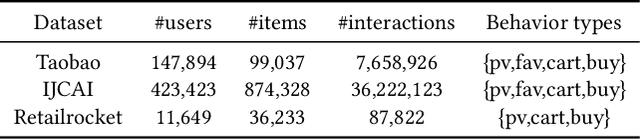
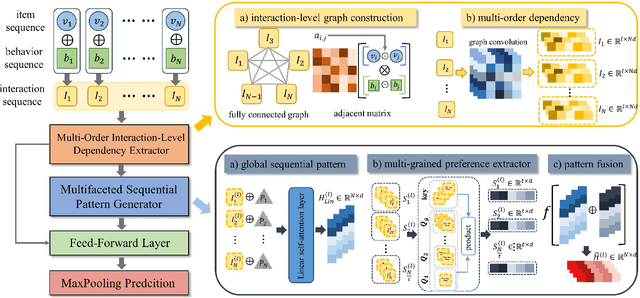
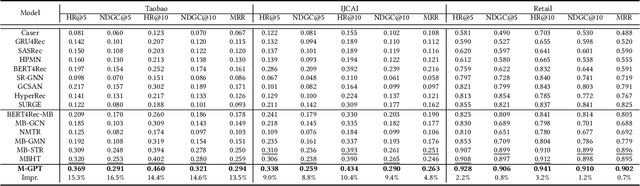
Sequential recommendation (SR) aims to predict the next purchasing item according to users' dynamic preference learned from their historical user-item interactions. To improve the performance of recommendation, learning dynamic heterogeneous cross-type behavior dependencies is indispensable for recommender system. However, there still exists some challenges in Multi-Behavior Sequential Recommendation (MBSR). On the one hand, existing methods only model heterogeneous multi-behavior dependencies at behavior-level or item-level, and modelling interaction-level dependencies is still a challenge. On the other hand, the dynamic multi-grained behavior-aware preference is hard to capture in interaction sequences, which reflects interaction-aware sequential pattern. To tackle these challenges, we propose a Multi-Grained Preference enhanced Transformer framework (M-GPT). First, M-GPT constructs a interaction-level graph of historical cross-typed interactions in a sequence. Then graph convolution is performed to derive interaction-level multi-behavior dependency representation repeatedly, in which the complex correlation between historical cross-typed interactions at specific orders can be well learned. Secondly, a novel multi-scale transformer architecture equipped with multi-grained user preference extraction is proposed to encode the interaction-aware sequential pattern enhanced by capturing temporal behavior-aware multi-grained preference . Experiments on the real-world datasets indicate that our method M-GPT consistently outperforms various state-of-the-art recommendation methods.
WHALE-FL: Wireless and Heterogeneity Aware Latency Efficient Federated Learning over Mobile Devices via Adaptive Subnetwork Scheduling
May 01, 2024As a popular distributed learning paradigm, federated learning (FL) over mobile devices fosters numerous applications, while their practical deployment is hindered by participating devices' computing and communication heterogeneity. Some pioneering research efforts proposed to extract subnetworks from the global model, and assign as large a subnetwork as possible to the device for local training based on its full computing and communications capacity. Although such fixed size subnetwork assignment enables FL training over heterogeneous mobile devices, it is unaware of (i) the dynamic changes of devices' communication and computing conditions and (ii) FL training progress and its dynamic requirements of local training contributions, both of which may cause very long FL training delay. Motivated by those dynamics, in this paper, we develop a wireless and heterogeneity aware latency efficient FL (WHALE-FL) approach to accelerate FL training through adaptive subnetwork scheduling. Instead of sticking to the fixed size subnetwork, WHALE-FL introduces a novel subnetwork selection utility function to capture device and FL training dynamics, and guides the mobile device to adaptively select the subnetwork size for local training based on (a) its computing and communication capacity, (b) its dynamic computing and/or communication conditions, and (c) FL training status and its corresponding requirements for local training contributions. Our evaluation shows that, compared with peer designs, WHALE-FL effectively accelerates FL training without sacrificing learning accuracy.
DEDGAT: Dual Embedding of Directed Graph Attention Networks for Detecting Financial Risk
Mar 06, 2023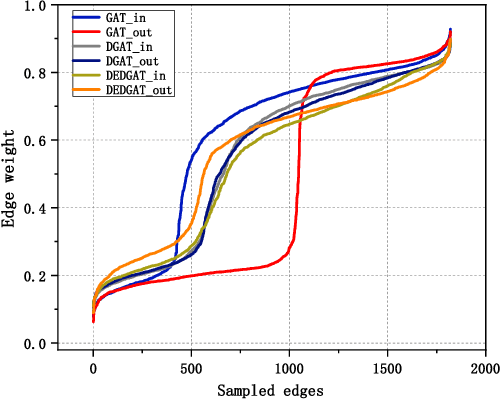
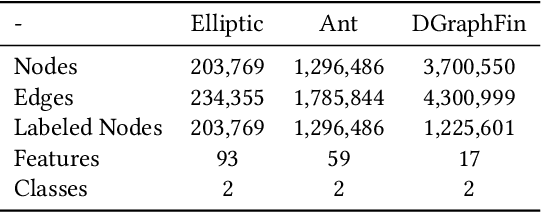
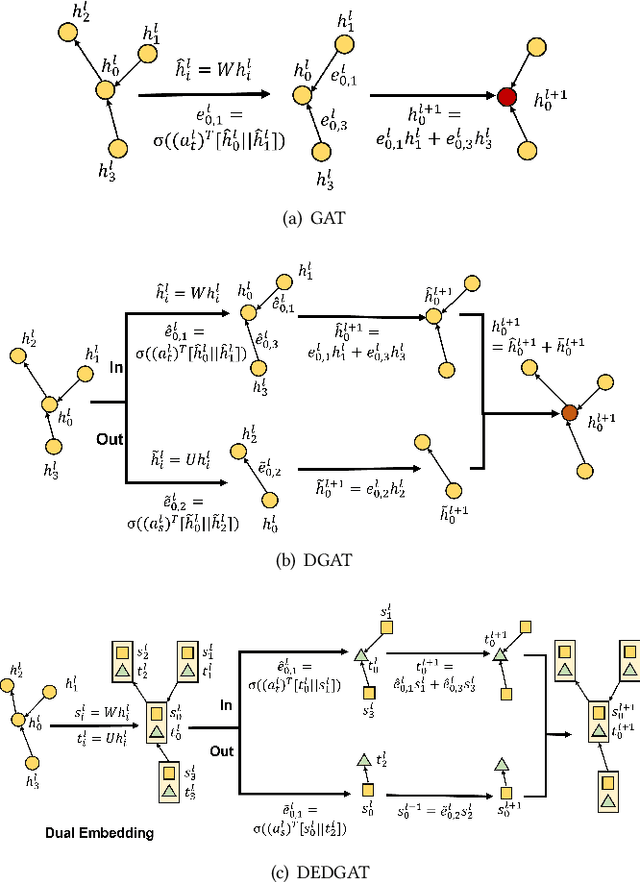
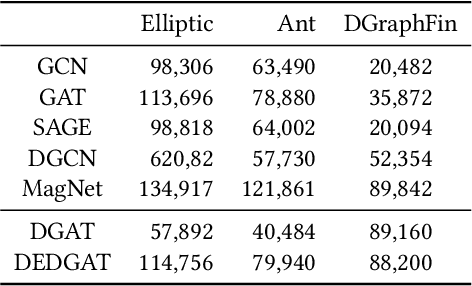
Graph representation plays an important role in the field of financial risk control, where the relationship among users can be constructed in a graph manner. In practical scenarios, the relationships between nodes in risk control tasks are bidirectional, e.g., merchants having both revenue and expense behaviors. Graph neural networks designed for undirected graphs usually aggregate discriminative node or edge representations with an attention strategy, but cannot fully exploit the out-degree information when used for the tasks built on directed graph, which leads to the problem of a directional bias. To tackle this problem, we propose a Directed Graph ATtention network called DGAT, which explicitly takes out-degree into attention calculation. In addition to having directional requirements, the same node might have different representations of its input and output, and thus we further propose a dual embedding of DGAT, referred to as DEDGAT. Specifically, DEDGAT assigns in-degree and out-degree representations to each node and uses these two embeddings to calculate the attention weights of in-degree and out-degree nodes, respectively. Experiments performed on the benchmark datasets show that DGAT and DEDGAT obtain better classification performance compared to undirected GAT. Also,the visualization results demonstrate that our methods can fully use both in-degree and out-degree information.
CyclicFL: A Cyclic Model Pre-Training Approach to Efficient Federated Learning
Jan 28, 2023Since random initial models in Federated Learning (FL) can easily result in unregulated Stochastic Gradient Descent (SGD) processes, existing FL methods greatly suffer from both slow convergence and poor accuracy, especially for non-IID scenarios. To address this problem, we propose a novel FL method named CyclicFL, which can quickly derive effective initial models to guide the SGD processes, thus improving the overall FL training performance. Based on the concept of Continual Learning (CL), we prove that CyclicFL approximates existing centralized pre-training methods in terms of classification and prediction performance. Meanwhile, we formally analyze the significance of data consistency between the pre-training and training stages of CyclicFL, showing the limited Lipschitzness of loss for the pre-trained models by CyclicFL. Unlike traditional centralized pre-training methods that require public proxy data, CyclicFL pre-trains initial models on selected clients cyclically without exposing their local data. Therefore, they can be easily integrated into any security-critical FL methods. Comprehensive experimental results show that CyclicFL can not only improve the classification accuracy by up to 16.21%, but also significantly accelerate the overall FL training processes.
Efficient Federated Learning for AIoT Applications Using Knowledge Distillation
Nov 29, 2021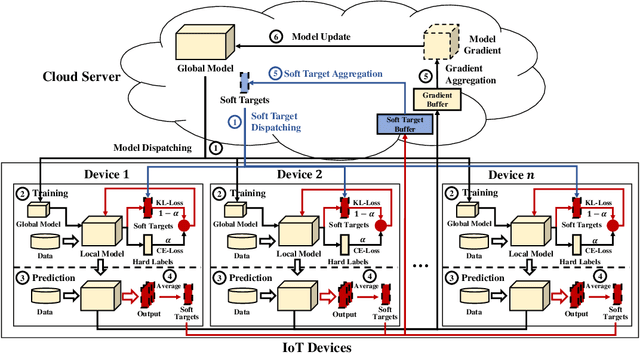
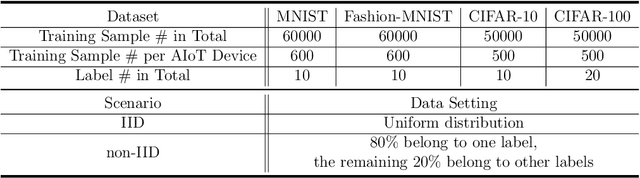
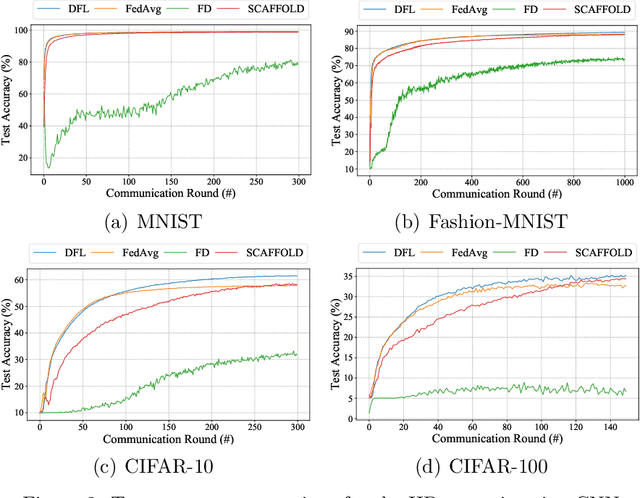
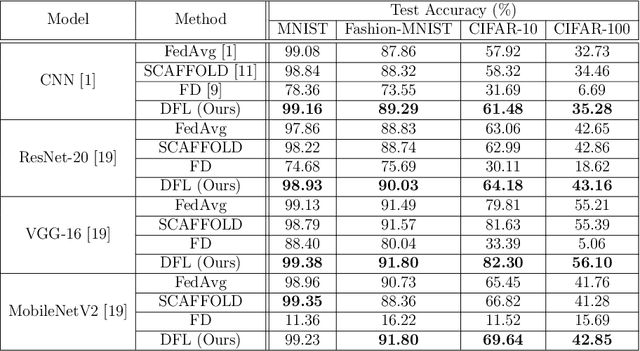
As a promising distributed machine learning paradigm, Federated Learning (FL) trains a central model with decentralized data without compromising user privacy, which has made it widely used by Artificial Intelligence Internet of Things (AIoT) applications. However, the traditional FL suffers from model inaccuracy since it trains local models using hard labels of data and ignores useful information of incorrect predictions with small probabilities. Although various solutions try to tackle the bottleneck of the traditional FL, most of them introduce significant communication and memory overhead, making the deployment of large-scale AIoT devices a great challenge. To address the above problem, this paper presents a novel Distillation-based Federated Learning (DFL) architecture that enables efficient and accurate FL for AIoT applications. Inspired by Knowledge Distillation (KD) that can increase the model accuracy, our approach adds the soft targets used by KD to the FL model training, which occupies negligible network resources. The soft targets are generated by local sample predictions of each AIoT device after each round of local training and used for the next round of model training. During the local training of DFL, both soft targets and hard labels are used as approximation objectives of model predictions to improve model accuracy by supplementing the knowledge of soft targets. To further improve the performance of our DFL model, we design a dynamic adjustment strategy for tuning the ratio of two loss functions used in KD, which can maximize the use of both soft targets and hard labels. Comprehensive experimental results on well-known benchmarks show that our approach can significantly improve the model accuracy of FL with both Independent and Identically Distributed (IID) and non-IID data.
Shift-BNN: Highly-Efficient Probabilistic Bayesian Neural Network Training via Memory-Friendly Pattern Retrieving
Oct 07, 2021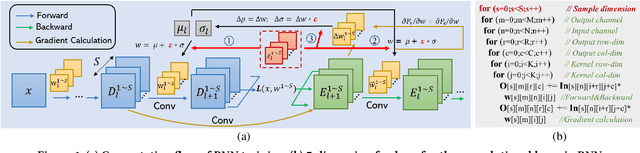
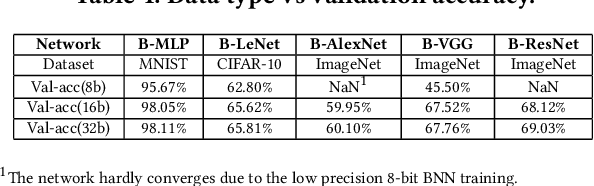
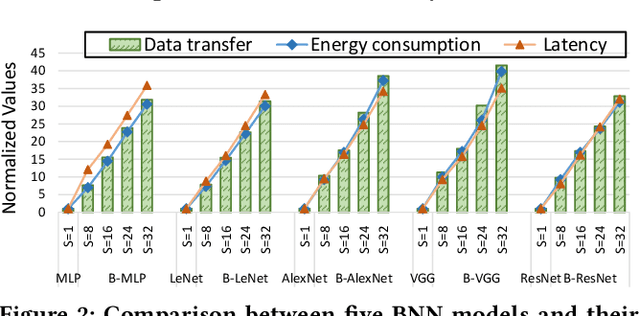
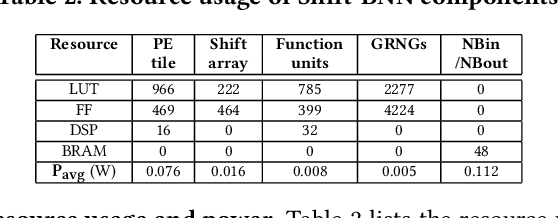
Bayesian Neural Networks (BNNs) that possess a property of uncertainty estimation have been increasingly adopted in a wide range of safety-critical AI applications which demand reliable and robust decision making, e.g., self-driving, rescue robots, medical image diagnosis. The training procedure of a probabilistic BNN model involves training an ensemble of sampled DNN models, which induces orders of magnitude larger volume of data movement than training a single DNN model. In this paper, we reveal that the root cause for BNN training inefficiency originates from the massive off-chip data transfer by Gaussian Random Variables (GRVs). To tackle this challenge, we propose a novel design that eliminates all the off-chip data transfer by GRVs through the reversed shifting of Linear Feedback Shift Registers (LFSRs) without incurring any training accuracy loss. To efficiently support our LFSR reversion strategy at the hardware level, we explore the design space of the current DNN accelerators and identify the optimal computation mapping scheme to best accommodate our strategy. By leveraging this finding, we design and prototype the first highly efficient BNN training accelerator, named Shift-BNN, that is low-cost and scalable. Extensive evaluation on five representative BNN models demonstrates that Shift-BNN achieves an average of 4.9x (up to 10.8x) boost in energy efficiency and 1.6x (up to 2.8x) speedup over the baseline DNN training accelerator.
A Large-Scale Benchmark for Food Image Segmentation
May 12, 2021
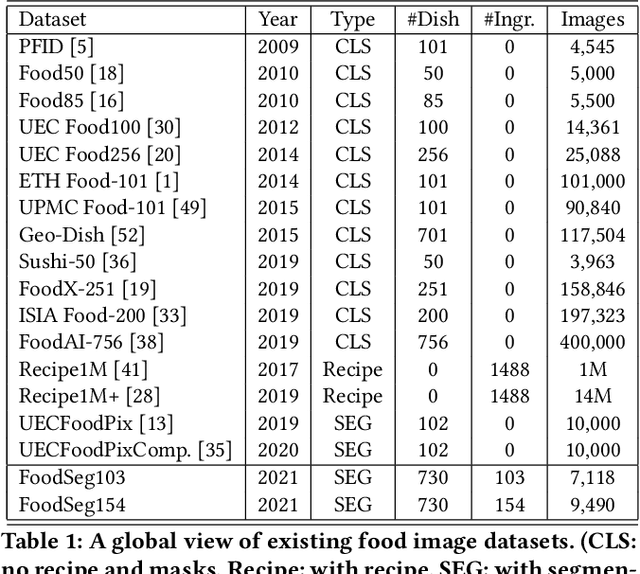

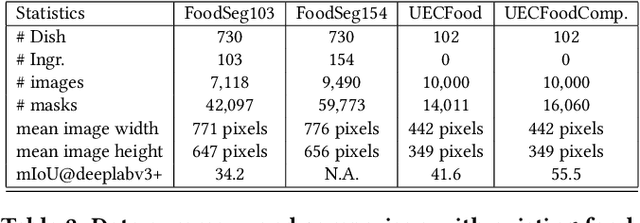
Food image segmentation is a critical and indispensible task for developing health-related applications such as estimating food calories and nutrients. Existing food image segmentation models are underperforming due to two reasons: (1) there is a lack of high quality food image datasets with fine-grained ingredient labels and pixel-wise location masks -- the existing datasets either carry coarse ingredient labels or are small in size; and (2) the complex appearance of food makes it difficult to localize and recognize ingredients in food images, e.g., the ingredients may overlap one another in the same image, and the identical ingredient may appear distinctly in different food images. In this work, we build a new food image dataset FoodSeg103 (and its extension FoodSeg154) containing 9,490 images. We annotate these images with 154 ingredient classes and each image has an average of 6 ingredient labels and pixel-wise masks. In addition, we propose a multi-modality pre-training approach called ReLeM that explicitly equips a segmentation model with rich and semantic food knowledge. In experiments, we use three popular semantic segmentation methods (i.e., Dilated Convolution based, Feature Pyramid based, and Vision Transformer based) as baselines, and evaluate them as well as ReLeM on our new datasets. We believe that the FoodSeg103 (and its extension FoodSeg154) and the pre-trained models using ReLeM can serve as a benchmark to facilitate future works on fine-grained food image understanding. We make all these datasets and methods public at \url{https://xiongweiwu.github.io/foodseg103.html}.