 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVFoodSeg: Elevating Open-Vocabulary Food Image Segmentation via Image-Informed Textual Representation
Apr 01, 2024In the realm of food computing, segmenting ingredients from images poses substantial challenges due to the large intra-class variance among the same ingredients, the emergence of new ingredients, and the high annotation costs associated with large food segmentation datasets. Existing approaches primarily utilize a closed-vocabulary and static text embeddings setting. These methods often fall short in effectively handling the ingredients, particularly new and diverse ones. In response to these limitations, we introduce OVFoodSeg, a framework that adopts an open-vocabulary setting and enhances text embeddings with visual context. By integrating vision-language models (VLMs), our approach enriches text embedding with image-specific information through two innovative modules, eg, an image-to-text learner FoodLearner and an Image-Informed Text Encoder. The training process of OVFoodSeg is divided into two stages: the pre-training of FoodLearner and the subsequent learning phase for segmentation. The pre-training phase equips FoodLearner with the capability to align visual information with corresponding textual representations that are specifically related to food, while the second phase adapts both the FoodLearner and the Image-Informed Text Encoder for the segmentation task. By addressing the deficiencies of previous models, OVFoodSeg demonstrates a significant improvement, achieving an 4.9\% increase in mean Intersection over Union (mIoU) on the FoodSeg103 dataset, setting a new milestone for food image segmentation.
A Map-matching Algorithm with Extraction of Multi-group Information for Low-frequency Data
Sep 18, 2022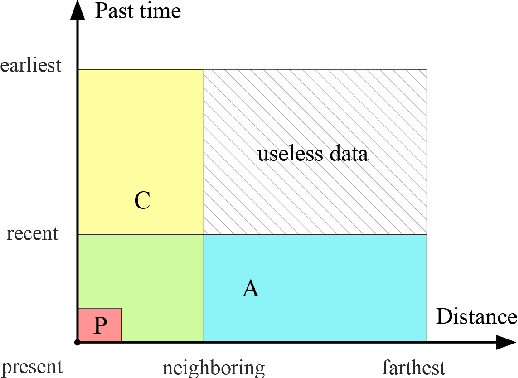
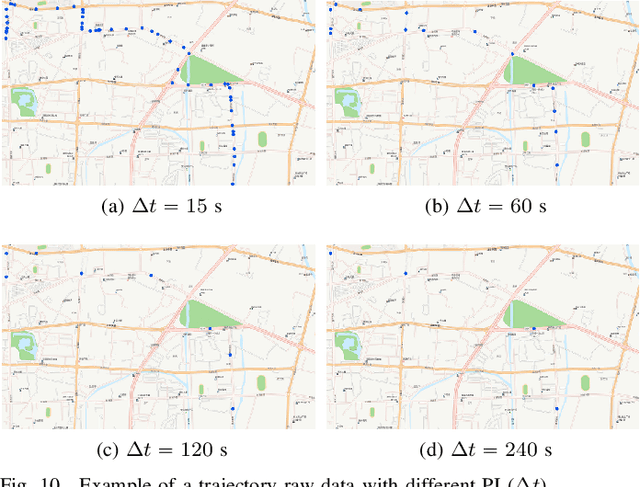
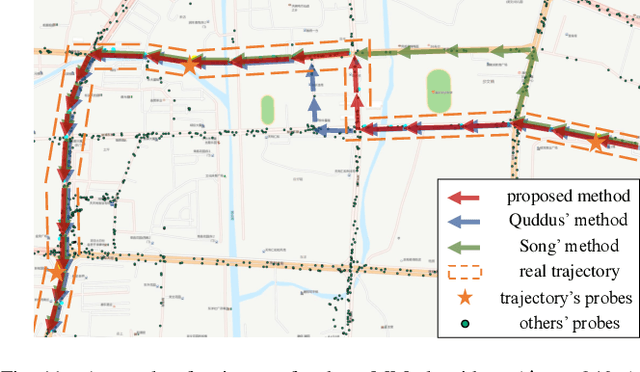
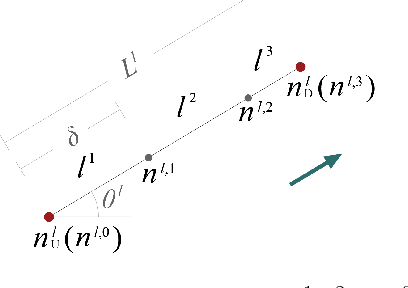
The growing use of probe vehicles generates a huge number of GNSS data. Limited by the satellite positioning technology, further improving the accuracy of map-matching is challenging work, especially for low-frequency trajectories. When matching a trajectory, the ego vehicle's spatial-temporal information of the present trip is the most useful with the least amount of data. In addition, there are a large amount of other data, e.g., other vehicles' state and past prediction results, but it is hard to extract useful information for matching maps and inferring paths. Most map-matching studies only used the ego vehicle's data and ignored other vehicles' data. Based on it, this paper designs a new map-matching method to make full use of "Big data". We first sort all data into four groups according to their spatial and temporal distance from the present matching probe which allows us to sort for their usefulness. Then we design three different methods to extract valuable information (scores) from them: a score for speed and bearing, a score for historical usage, and a score for traffic state using the spectral graph Markov neutral network. Finally, we use a modified top-K shortest-path method to search the candidate paths within an ellipse region and then use the fused score to infer the path (projected location). We test the proposed method against baseline algorithms using a real-world dataset in China. The results show that all scoring methods can enhance map-matching accuracy. Furthermore, our method outperforms the others, especially when GNSS probing frequency is less than 0.01 Hz.
Collaborative Intelligent Reflecting Surface Networks with Multi-Agent Reinforcement Learning
Mar 26, 2022
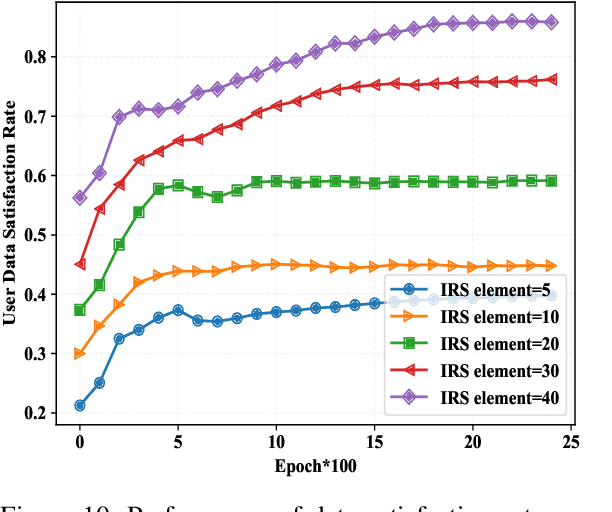

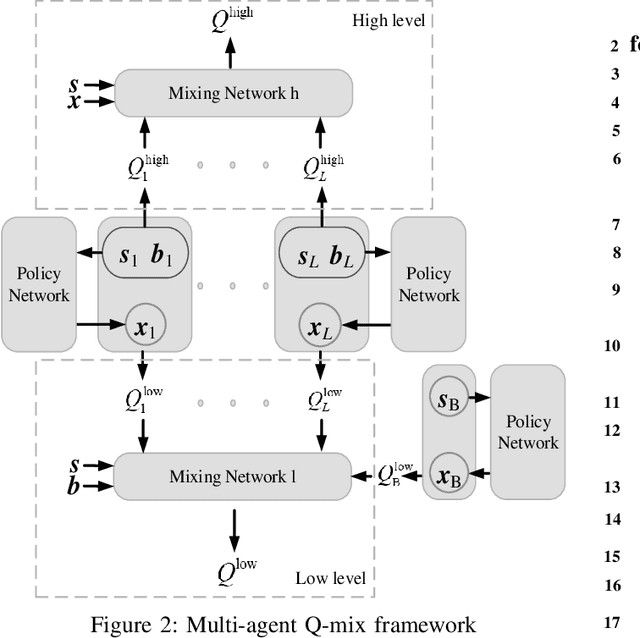
Intelligent reflecting surface (IRS) is envisioned to be widely applied in future wireless networks. In this paper, we investigate a multi-user communication system assisted by cooperative IRS devices with the capability of energy harvesting. Aiming to maximize the long-term average achievable system rate, an optimization problem is formulated by jointly designing the transmit beamforming at the base station (BS) and discrete phase shift beamforming at the IRSs, with the constraints on transmit power, user data rate requirement and IRS energy buffer size. Considering time-varying channels and stochastic arrivals of energy harvested by the IRSs, we first formulate the problem as a Markov decision process (MDP) and then develop a novel multi-agent Q-mix (MAQ) framework with two layers to decouple the optimization parameters. The higher layer is for optimizing phase shift resolutions, and the lower one is for phase shift beamforming and power allocation. Since the phase shift optimization is an integer programming problem with a large-scale action space, we improve MAQ by incorporating the Wolpertinger method, namely, MAQ-WP algorithm to achieve a sub-optimality with reduced dimensions of action space. In addition, as MAQ-WP is still of high complexity to achieve good performance, we propose a policy gradient-based MAQ algorithm, namely, MAQ-PG, by mapping the discrete phase shift actions into a continuous space at the cost of a slight performance loss. Simulation results demonstrate that the proposed MAQ-WP and MAQ-PG algorithms can converge faster and achieve data rate improvements of 10.7% and 8.8% over the conventional multi-agent DDPG, respectively.
Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation
Mar 02, 2022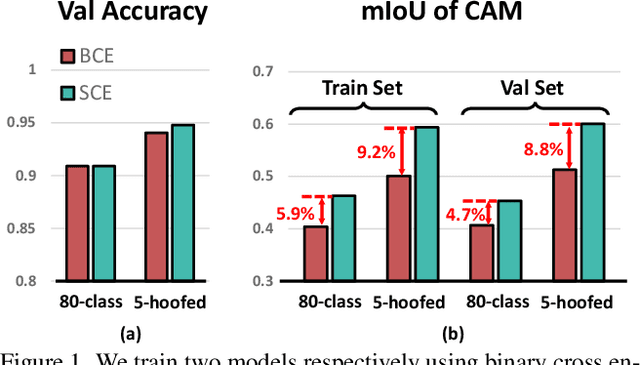
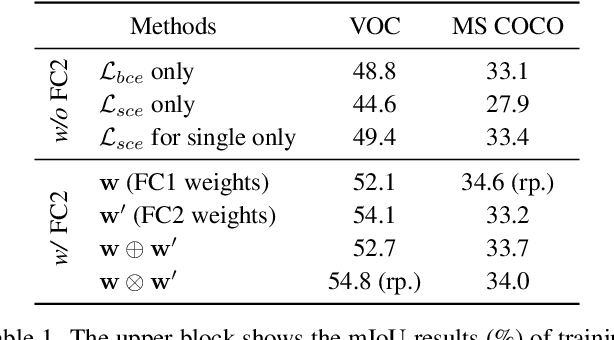
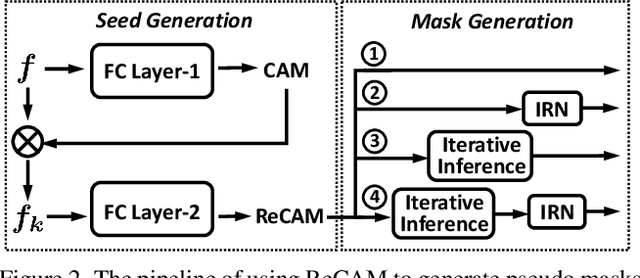
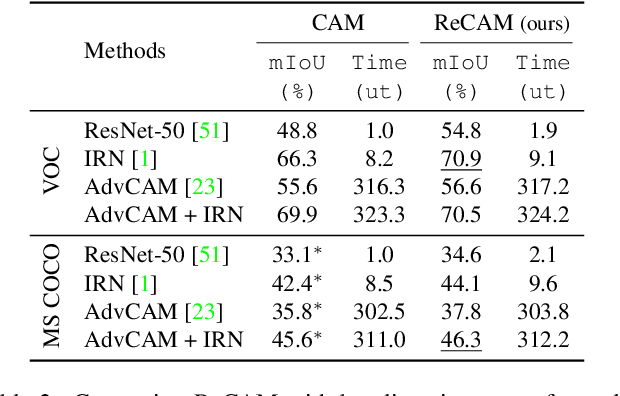
Extracting class activation maps (CAM) is arguably the most standard step of generating pseudo masks for weakly-supervised semantic segmentation (WSSS). Yet, we find that the crux of the unsatisfactory pseudo masks is the binary cross-entropy loss (BCE) widely used in CAM. Specifically, due to the sum-over-class pooling nature of BCE, each pixel in CAM may be responsive to multiple classes co-occurring in the same receptive field. As a result, given a class, its hot CAM pixels may wrongly invade the area belonging to other classes, or the non-hot ones may be actually a part of the class. To this end, we introduce an embarrassingly simple yet surprisingly effective method: Reactivating the converged CAM with BCE by using softmax cross-entropy loss (SCE), dubbed \textbf{ReCAM}. Given an image, we use CAM to extract the feature pixels of each single class, and use them with the class label to learn another fully-connected layer (after the backbone) with SCE. Once converged, we extract ReCAM in the same way as in CAM. Thanks to the contrastive nature of SCE, the pixel response is disentangled into different classes and hence less mask ambiguity is expected. The evaluation on both PASCAL VOC and MS~COCO shows that ReCAM not only generates high-quality masks, but also supports plug-and-play in any CAM variant with little overhead.
A Large-Scale Benchmark for Food Image Segmentation
May 12, 2021
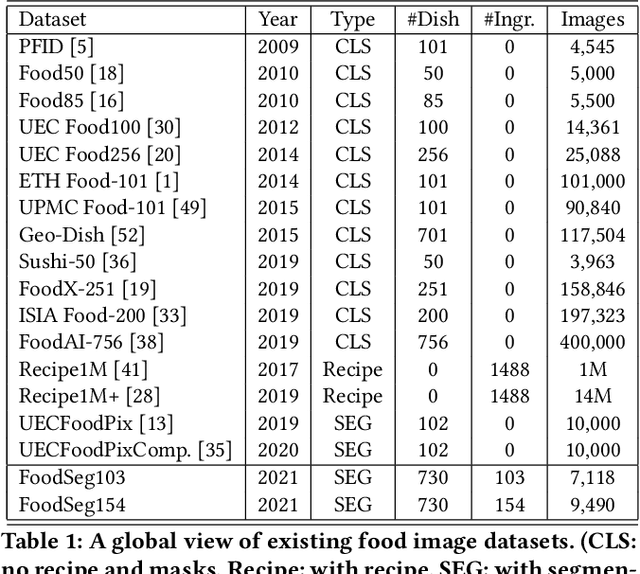

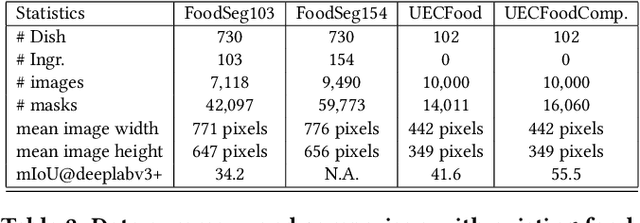
Food image segmentation is a critical and indispensible task for developing health-related applications such as estimating food calories and nutrients. Existing food image segmentation models are underperforming due to two reasons: (1) there is a lack of high quality food image datasets with fine-grained ingredient labels and pixel-wise location masks -- the existing datasets either carry coarse ingredient labels or are small in size; and (2) the complex appearance of food makes it difficult to localize and recognize ingredients in food images, e.g., the ingredients may overlap one another in the same image, and the identical ingredient may appear distinctly in different food images. In this work, we build a new food image dataset FoodSeg103 (and its extension FoodSeg154) containing 9,490 images. We annotate these images with 154 ingredient classes and each image has an average of 6 ingredient labels and pixel-wise masks. In addition, we propose a multi-modality pre-training approach called ReLeM that explicitly equips a segmentation model with rich and semantic food knowledge. In experiments, we use three popular semantic segmentation methods (i.e., Dilated Convolution based, Feature Pyramid based, and Vision Transformer based) as baselines, and evaluate them as well as ReLeM on our new datasets. We believe that the FoodSeg103 (and its extension FoodSeg154) and the pre-trained models using ReLeM can serve as a benchmark to facilitate future works on fine-grained food image understanding. We make all these datasets and methods public at \url{https://xiongweiwu.github.io/foodseg103.html}.
Recent Advances in Deep Learning for Object Detection
Aug 10, 2019



Object detection is a fundamental visual recognition problem in computer vision and has been widely studied in the past decades. Visual object detection aims to find objects of certain target classes with precise localization in a given image and assign each object instance a corresponding class label. Due to the tremendous successes of deep learning based image classification, object detection techniques using deep learning have been actively studied in recent years. In this paper, we give a comprehensive survey of recent advances in visual object detection with deep learning. By reviewing a large body of recent related work in literature, we systematically analyze the existing object detection frameworks and organize the survey into three major parts: (i) detection components, (ii) learning strategies, and (iii) applications & benchmarks. In the survey, we cover a variety of factors affecting the detection performance in detail, such as detector architectures, feature learning, proposal generation, sampling strategies, etc. Finally, we discuss several future directions to facilitate and spur future research for visual object detection with deep learning. Keywords: Object Detection, Deep Learning, Deep Convolutional Neural Networks
Feature Agglomeration Networks for Single Stage Face Detection
Sep 10, 2018



Recent years have witnessed promising results of face detection using deep learning. Despite making remarkable progresses, face detection in the wild remains an open research challenge especially when detecting faces at vastly different scales and characteristics. In this paper, we propose a novel simple yet effective framework of "Feature Agglomeration Networks" (FANet) to build a new single stage face detector, which not only achieves state-of-the-art performance but also runs efficiently. As inspired by Feature Pyramid Networks (FPN), the key idea of our framework is to exploit inherent multi-scale features of a single convolutional neural network by aggregating higher-level semantic feature maps of different scales as contextual cues to augment lower-level feature maps via a hierarchical agglomeration manner at marginal extra computation cost. We further propose a Hierarchical Loss to effectively train the FANet model. We evaluate the proposed FANet detector on several public face detection benchmarks, including PASCAL face, FDDB and WIDER FACE datasets and achieved state-of-the-art results. Our detector can run in real time for VGA-resolution images on GPU.
Single-Shot Bidirectional Pyramid Networks for High-Quality Object Detection
Mar 22, 2018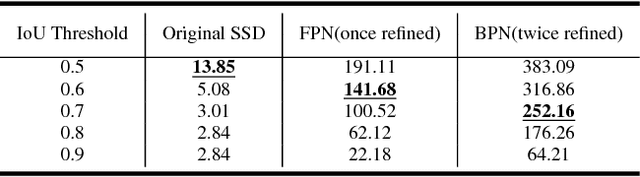
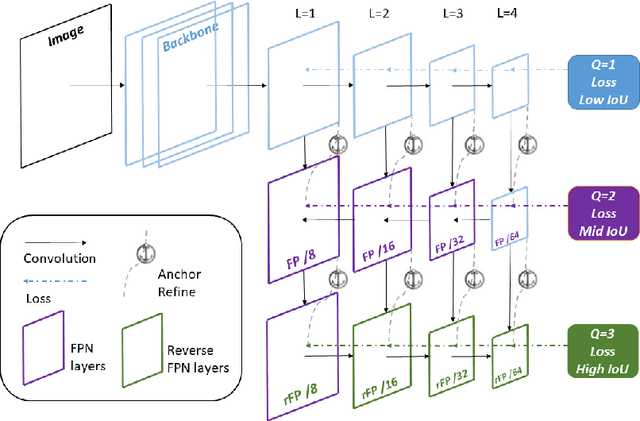
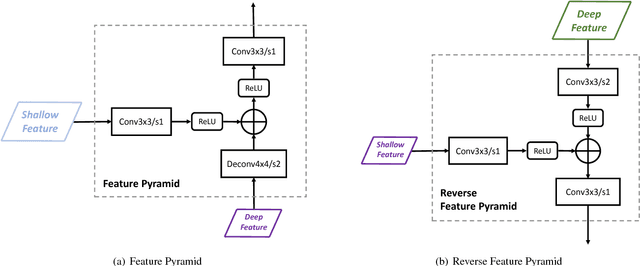
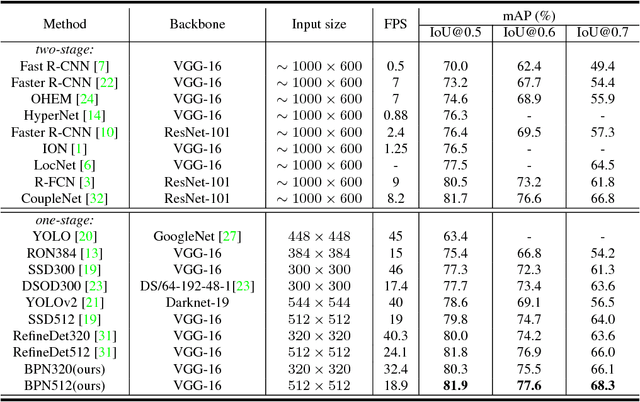
Recent years have witnessed many exciting achievements for object detection using deep learning techniques. Despite achieving significant progresses, most existing detectors are designed to detect objects with relatively low-quality prediction of locations, i.e., often trained with the threshold of Intersection over Union (IoU) set to 0.5 by default, which can yield low-quality or even noisy detections. It remains an open challenge for how to devise and train a high-quality detector that can achieve more precise localization (i.e., IoU$>$0.5) without sacrificing the detection performance. In this paper, we propose a novel single-shot detection framework of Bidirectional Pyramid Networks (BPN) towards high-quality object detection, which consists of two novel components: (i) a Bidirectional Feature Pyramid structure for more effective and robust feature representations; and (ii) a Cascade Anchor Refinement to gradually refine the quality of predesigned anchors for more effective training. Our experiments showed that the proposed BPN achieves the best performances among all the single-stage object detectors on both PASCAL VOC and MS COCO datasets, especially for high-quality detections.
LOGO-Net: Large-scale Deep Logo Detection and Brand Recognition with Deep Region-based Convolutional Networks
Nov 13, 2015
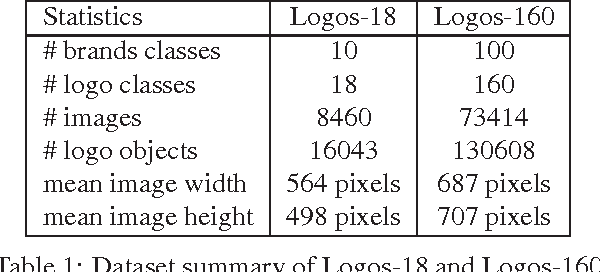
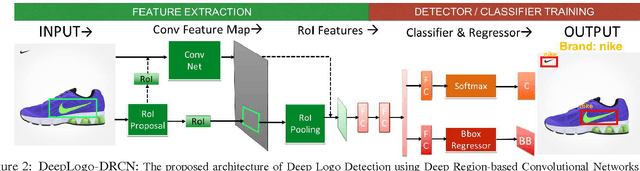
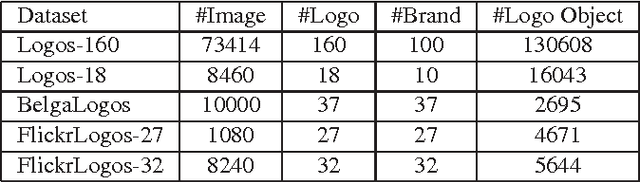
Logo detection from images has many applications, particularly for brand recognition and intellectual property protection. Most existing studies for logo recognition and detection are based on small-scale datasets which are not comprehensive enough when exploring emerging deep learning techniques. In this paper, we introduce "LOGO-Net", a large-scale logo image database for logo detection and brand recognition from real-world product images. To facilitate research, LOGO-Net has two datasets: (i)"logos-18" consists of 18 logo classes, 10 brands, and 16,043 logo objects, and (ii) "logos-160" consists of 160 logo classes, 100 brands, and 130,608 logo objects. We describe the ideas and challenges for constructing such a large-scale database. Another key contribution of this work is to apply emerging deep learning techniques for logo detection and brand recognition tasks, and conduct extensive experiments by exploring several state-of-the-art deep region-based convolutional networks techniques for object detection tasks. The LOGO-net will be released at http://logo-net.org/