 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantizing Diffusion Models from a Sampling-Aware Perspective
May 04, 2025Diffusion models have recently emerged as the dominant approach in visual generation tasks. However, the lengthy denoising chains and the computationally intensive noise estimation networks hinder their applicability in low-latency and resource-limited environments. Previous research has endeavored to address these limitations in a decoupled manner, utilizing either advanced samplers or efficient model quantization techniques. In this study, we uncover that quantization-induced noise disrupts directional estimation at each sampling step, further distorting the precise directional estimations of higher-order samplers when solving the sampling equations through discretized numerical methods, thereby altering the optimal sampling trajectory. To attain dual acceleration with high fidelity, we propose a sampling-aware quantization strategy, wherein a Mixed-Order Trajectory Alignment technique is devised to impose a more stringent constraint on the error bounds at each sampling step, facilitating a more linear probability flow. Extensive experiments on sparse-step fast sampling across multiple datasets demonstrate that our approach preserves the rapid convergence characteristics of high-speed samplers while maintaining superior generation quality. Code will be made publicly available soon.
Training Data Provenance Verification: Did Your Model Use Synthetic Data from My Generative Model for Training?
Mar 12, 2025High-quality open-source text-to-image models have lowered the threshold for obtaining photorealistic images significantly, but also face potential risks of misuse. Specifically, suspects may use synthetic data generated by these generative models to train models for specific tasks without permission, when lacking real data resources especially. Protecting these generative models is crucial for the well-being of their owners. In this work, we propose the first method to this important yet unresolved issue, called Training data Provenance Verification (TrainProVe). The rationale behind TrainProVe is grounded in the principle of generalization error bound, which suggests that, for two models with the same task, if the distance between their training data distributions is smaller, their generalization ability will be closer. We validate the efficacy of TrainProVe across four text-to-image models (Stable Diffusion v1.4, latent consistency model, PixArt-$\alpha$, and Stable Cascade). The results show that TrainProVe achieves a verification accuracy of over 99\% in determining the provenance of suspicious model training data, surpassing all previous methods. Code is available at https://github.com/xieyc99/TrainProVe.
Deep Feature Response Discriminative Calibration
Nov 16, 2024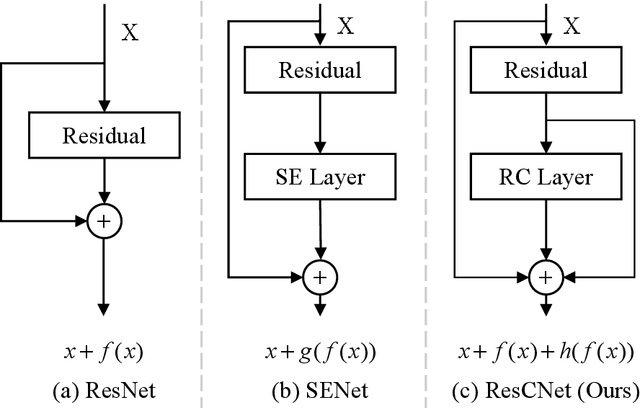
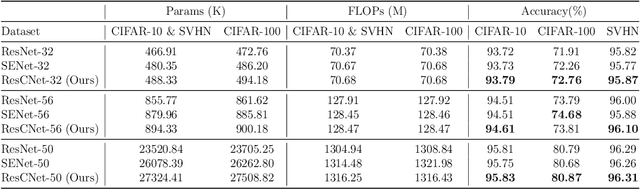
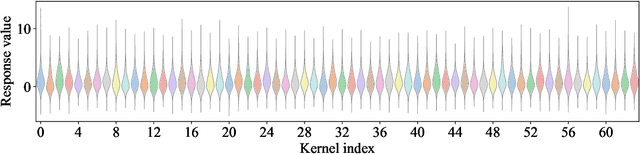
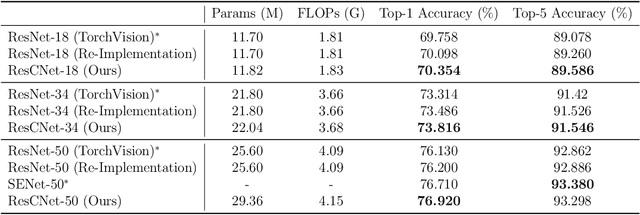
Deep neural networks (DNNs) have numerous applications across various domains. Several optimization techniques, such as ResNet and SENet, have been proposed to improve model accuracy. These techniques improve the model performance by adjusting or calibrating feature responses according to a uniform standard. However, they lack the discriminative calibration for different features, thereby introducing limitations in the model output. Therefore, we propose a method that discriminatively calibrates feature responses. The preliminary experimental results indicate that the neural feature response follows a Gaussian distribution. Consequently, we compute confidence values by employing the Gaussian probability density function, and then integrate these values with the original response values. The objective of this integration is to improve the feature discriminability of the neural feature response. Based on the calibration values, we propose a plugin-based calibration module incorporated into a modified ResNet architecture, termed Response Calibration Networks (ResCNet). Extensive experiments on datasets like CIFAR-10, CIFAR-100, SVHN, and ImageNet demonstrate the effectiveness of the proposed approach. The developed code is publicly available at https://github.com/tcmyxc/ResCNet.
LG-CAV: Train Any Concept Activation Vector with Language Guidance
Oct 14, 2024



Concept activation vector (CAV) has attracted broad research interest in explainable AI, by elegantly attributing model predictions to specific concepts. However, the training of CAV often necessitates a large number of high-quality images, which are expensive to curate and thus limited to a predefined set of concepts. To address this issue, we propose Language-Guided CAV (LG-CAV) to harness the abundant concept knowledge within the certain pre-trained vision-language models (e.g., CLIP). This method allows training any CAV without labeled data, by utilizing the corresponding concept descriptions as guidance. To bridge the gap between vision-language model and the target model, we calculate the activation values of concept descriptions on a common pool of images (probe images) with vision-language model and utilize them as language guidance to train the LG-CAV. Furthermore, after training high-quality LG-CAVs related to all the predicted classes in the target model, we propose the activation sample reweighting (ASR), serving as a model correction technique, to improve the performance of the target model in return. Experiments on four datasets across nine architectures demonstrate that LG-CAV achieves significantly superior quality to previous CAV methods given any concept, and our model correction method achieves state-of-the-art performance compared to existing concept-based methods. Our code is available at https://github.com/hqhQAQ/LG-CAV.
PruningBench: A Comprehensive Benchmark of Structural Pruning
Jun 18, 2024



Structural pruning has emerged as a promising approach for producing more efficient models. Nevertheless, the community suffers from a lack of standardized benchmarks and metrics, leaving the progress in this area not fully comprehended. To fill this gap, we present the first comprehensive benchmark, termed \textit{PruningBench}, for structural pruning. PruningBench showcases the following three characteristics: 1) PruningBench employs a unified and consistent framework for evaluating the effectiveness of diverse structural pruning techniques; 2) PruningBench systematically evaluates 16 existing pruning methods, encompassing a wide array of models (e.g., CNNs and ViTs) and tasks (e.g., classification and detection); 3) PruningBench provides easily implementable interfaces to facilitate the implementation of future pruning methods, and enables the subsequent researchers to incorporate their work into our leaderboards. We provide an online pruning platform http://pruning.vipazoo.cn for customizing pruning tasks and reproducing all results in this paper. Codes will be made publicly available.
Simple Graph Condensation
Mar 22, 2024



The burdensome training costs on large-scale graphs have aroused significant interest in graph condensation, which involves tuning Graph Neural Networks (GNNs) on a small condensed graph for use on the large-scale original graph. Existing methods primarily focus on aligning key metrics between the condensed and original graphs, such as gradients, distribution and trajectory of GNNs, yielding satisfactory performance on downstream tasks. However, these complex metrics necessitate intricate computations and can potentially disrupt the optimization process of the condensation graph, making the condensation process highly demanding and unstable. Motivated by the recent success of simplified models in various fields, we propose a simplified approach to metric alignment in graph condensation, aiming to reduce unnecessary complexity inherited from GNNs. In our approach, we eliminate external parameters and exclusively retain the target condensed graph during the condensation process. Following the hierarchical aggregation principles of GNNs, we introduce the Simple Graph Condensation (SimGC) framework, which aligns the condensed graph with the original graph from the input layer to the prediction layer, guided by a pre-trained Simple Graph Convolution (SGC) model on the original graph. As a result, both graphs possess the similar capability to train GNNs. This straightforward yet effective strategy achieves a significant speedup of up to 10 times compared to existing graph condensation methods while performing on par with state-of-the-art baselines. Comprehensive experiments conducted on seven benchmark datasets demonstrate the effectiveness of SimGC in prediction accuracy, condensation time, and generalization capability. Our code will be made publicly available.
Training-Free Pretrained Model Merging
Mar 15, 2024
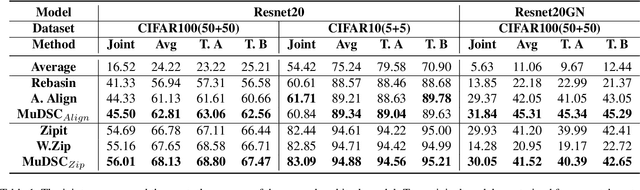
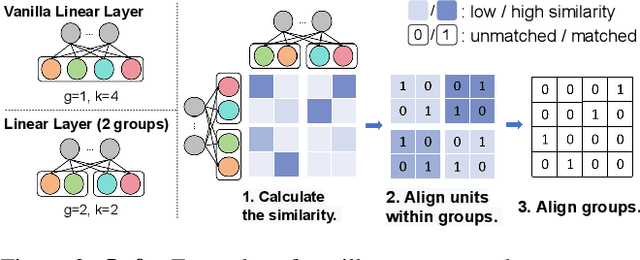
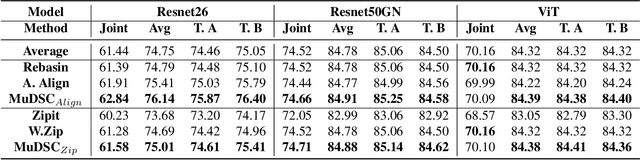
Recently, model merging techniques have surfaced as a solution to combine multiple single-talent models into a single multi-talent model. However, previous endeavors in this field have either necessitated additional training or fine-tuning processes, or require that the models possess the same pre-trained initialization. In this work, we identify a common drawback in prior works w.r.t. the inconsistency of unit similarity in the weight space and the activation space. To address this inconsistency, we propose an innovative model merging framework, coined as merging under dual-space constraints (MuDSC). Specifically, instead of solely maximizing the objective of a single space, we advocate for the exploration of permutation matrices situated in a region with a unified high similarity in the dual space, achieved through the linear combination of activation and weight similarity matrices. In order to enhance usability, we have also incorporated adaptations for group structure, including Multi-Head Attention and Group Normalization. Comprehensive experimental comparisons demonstrate that MuDSC can significantly boost the performance of merged models with various task combinations and architectures. Furthermore, the visualization of the merged model within the multi-task loss landscape reveals that MuDSC enables the merged model to reside in the overlapping segment, featuring a unified lower loss for each task. Our code is publicly available at https://github.com/zju-vipa/training_free_model_merging.
Comparison Knowledge Translation for Generalizable Image Classification
May 07, 2022


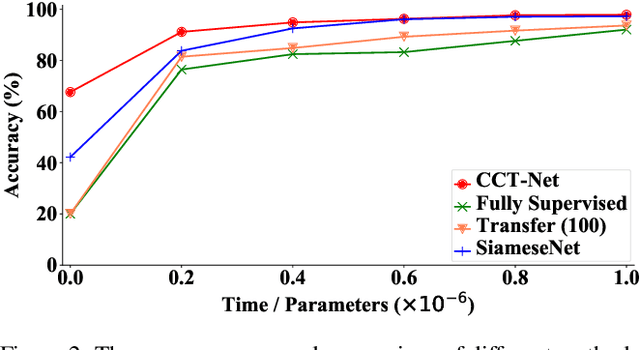
Deep learning has recently achieved remarkable performance in image classification tasks, which depends heavily on massive annotation. However, the classification mechanism of existing deep learning models seems to contrast to humans' recognition mechanism. With only a glance at an image of the object even unknown type, humans can quickly and precisely find other same category objects from massive images, which benefits from daily recognition of various objects. In this paper, we attempt to build a generalizable framework that emulates the humans' recognition mechanism in the image classification task, hoping to improve the classification performance on unseen categories with the support of annotations of other categories. Specifically, we investigate a new task termed Comparison Knowledge Translation (CKT). Given a set of fully labeled categories, CKT aims to translate the comparison knowledge learned from the labeled categories to a set of novel categories. To this end, we put forward a Comparison Classification Translation Network (CCT-Net), which comprises a comparison classifier and a matching discriminator. The comparison classifier is devised to classify whether two images belong to the same category or not, while the matching discriminator works together in an adversarial manner to ensure whether classified results match the truth. Exhaustive experiments show that CCT-Net achieves surprising generalization ability on unseen categories and SOTA performance on target categories.
LOGO-Net: Large-scale Deep Logo Detection and Brand Recognition with Deep Region-based Convolutional Networks
Nov 13, 2015
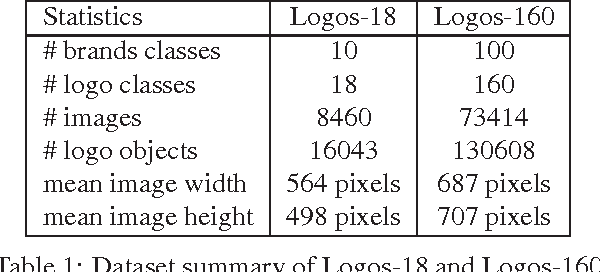
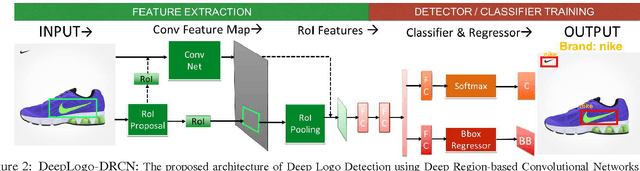
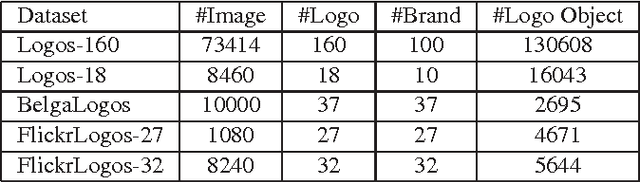
Logo detection from images has many applications, particularly for brand recognition and intellectual property protection. Most existing studies for logo recognition and detection are based on small-scale datasets which are not comprehensive enough when exploring emerging deep learning techniques. In this paper, we introduce "LOGO-Net", a large-scale logo image database for logo detection and brand recognition from real-world product images. To facilitate research, LOGO-Net has two datasets: (i)"logos-18" consists of 18 logo classes, 10 brands, and 16,043 logo objects, and (ii) "logos-160" consists of 160 logo classes, 100 brands, and 130,608 logo objects. We describe the ideas and challenges for constructing such a large-scale database. Another key contribution of this work is to apply emerging deep learning techniques for logo detection and brand recognition tasks, and conduct extensive experiments by exploring several state-of-the-art deep region-based convolutional networks techniques for object detection tasks. The LOGO-net will be released at http://logo-net.org/