 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Scale Generative Reranking: A Tree-based Generative Rerank Method at Meituan
Apr 07, 2026In modern multi-stage recommendation systems, reranking plays a critical role by modeling contextual information. Due to inherent challenges such as the combinatorial space complexity, an increasing number of methods adopt the generative paradigm: the generator produces the optimal list during inference, while an evaluator guides the generator's optimization during the training phase. However, these methods still face two problems. Firstly, these generators fail to produce optimal generation results due to the lack of both local and global perspectives, regardless of whether the generation strategy is autoregressive or non-autoregressive. Secondly, the goal inconsistency problem between the generator and the evaluator during training complicates the guidance signal and leading to suboptimal performance. To address these issues, we propose the \textbf{N}ext-\textbf{S}cale \textbf{G}eneration \textbf{R}eranking (NSGR), a tree-based generative framework. Specifically, we introduce a next-scale generator (NSG) that progressively expands a recommendation list from user interests in a coarse-to-fine manner, balancing global and local perspectives. Furthermore, we design a multi-scale neighbor loss, which leverages a tree-based multi-scale evaluator (MSE) to provide scale-specific guidance to the NSG at each scale. Extensive experiments on public and industrial datasets validate the effectiveness of NSGR. And NSGR has been successfully deployed on the Meituan food delivery platform.
MBGR: Multi-Business Prediction for Generative Recommendation at Meituan
Apr 03, 2026Generative recommendation (GR) has recently emerged as a promising paradigm for industrial recommendations. GR leverages Semantic IDs (SIDs) to reduce the encoding-decoding space and employs the Next Token Prediction (NTP) framework to explore scaling laws. However, existing GR methods suffer from two critical issues: (1) a \textbf{seesaw phenomenon} in multi-business scenarios arises due to NTP's inability to capture complex cross-business behavioral patterns; and (2) a unified SID space causes \textbf{representation confusion} by failing to distinguish distinct semantic information across businesses. To address these issues, we propose Multi-Business Generative Recommendation (MBGR), the first GR framework tailored for multi-business scenarios. Our framework comprises three key components. First, we design a Business-aware semantic ID (BID) module that preserves semantic integrity via domain-aware tokenization. Then, we introduce a Multi-Business Prediction (MBP) structure to provide business-specific prediction capabilities. Furthermore, we develop a Label Dynamic Routing (LDR) module that transforms sparse multi-business labels into dense labels to further enhance the multi-business generation capability. Extensive offline and online experiments on Meituan's food delivery platform validate MBGR's effectiveness, and we have successfully deployed it in production.
DREAM: Deep Research Evaluation with Agentic Metrics
Feb 21, 2026Deep Research Agents generate analyst-grade reports, yet evaluating them remains challenging due to the absence of a single ground truth and the multidimensional nature of research quality. Recent benchmarks propose distinct methodologies, yet they suffer from the Mirage of Synthesis, where strong surface-level fluency and citation alignment can obscure underlying factual and reasoning defects. We characterize this gap by introducing a taxonomy across four verticals that exposes a critical capability mismatch: static evaluators inherently lack the tool-use capabilities required to assess temporal validity and factual correctness. To address this, we propose DREAM (Deep Research Evaluation with Agentic Metrics), a framework that instantiates the principle of capability parity by making evaluation itself agentic. DREAM structures assessment through an evaluation protocol combining query-agnostic metrics with adaptive metrics generated by a tool-calling agent, enabling temporally aware coverage, grounded verification, and systematic reasoning probes. Controlled evaluations demonstrate DREAM is significantly more sensitive to factual and temporal decay than existing benchmarks, offering a scalable, reference-free evaluation paradigm.
DOS: Dual-Flow Orthogonal Semantic IDs for Recommendation in Meituan
Feb 04, 2026Semantic IDs serve as a key component in generative recommendation systems. They not only incorporate open-world knowledge from large language models (LLMs) but also compress the semantic space to reduce generation difficulty. However, existing methods suffer from two major limitations: (1) the lack of contextual awareness in generation tasks leads to a gap between the Semantic ID codebook space and the generation space, resulting in suboptimal recommendations; and (2) suboptimal quantization methods exacerbate semantic loss in LLMs. To address these issues, we propose Dual-Flow Orthogonal Semantic IDs (DOS) method. Specifically, DOS employs a user-item dual flow-framework that leverages collaborative signals to align the Semantic ID codebook space with the generation space. Furthermore, we introduce an orthogonal residual quantization scheme that rotates the semantic space to an appropriate orientation, thereby maximizing semantic preservation. Extensive offline experiments and online A/B testing demonstrate the effectiveness of DOS. The proposed method has been successfully deployed in Meituan's mobile application, serving hundreds of millions of users.
You Only Evaluate Once: A Tree-based Rerank Method at Meituan
Aug 20, 2025

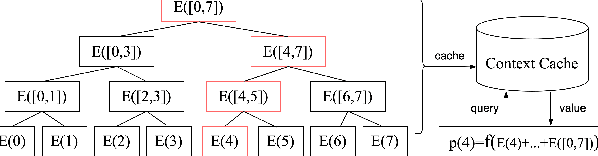

Reranking plays a crucial role in modern recommender systems by capturing the mutual influences within the list. Due to the inherent challenges of combinatorial search spaces, most methods adopt a two-stage search paradigm: a simple General Search Unit (GSU) efficiently reduces the candidate space, and an Exact Search Unit (ESU) effectively selects the optimal sequence. These methods essentially involve making trade-offs between effectiveness and efficiency, while suffering from a severe \textbf{inconsistency problem}, that is, the GSU often misses high-value lists from ESU. To address this problem, we propose YOLOR, a one-stage reranking method that removes the GSU while retaining only the ESU. Specifically, YOLOR includes: (1) a Tree-based Context Extraction Module (TCEM) that hierarchically aggregates multi-scale contextual features to achieve "list-level effectiveness", and (2) a Context Cache Module (CCM) that enables efficient feature reuse across candidate permutations to achieve "permutation-level efficiency". Extensive experiments across public and industry datasets validate YOLOR's performance, and we have successfully deployed YOLOR on the Meituan food delivery platform.
Task-Specific Zero-shot Quantization-Aware Training for Object Detection
Jul 22, 2025Quantization is a key technique to reduce network size and computational complexity by representing the network parameters with a lower precision. Traditional quantization methods rely on access to original training data, which is often restricted due to privacy concerns or security challenges. Zero-shot Quantization (ZSQ) addresses this by using synthetic data generated from pre-trained models, eliminating the need for real training data. Recently, ZSQ has been extended to object detection. However, existing methods use unlabeled task-agnostic synthetic images that lack the specific information required for object detection, leading to suboptimal performance. In this paper, we propose a novel task-specific ZSQ framework for object detection networks, which consists of two main stages. First, we introduce a bounding box and category sampling strategy to synthesize a task-specific calibration set from the pre-trained network, reconstructing object locations, sizes, and category distributions without any prior knowledge. Second, we integrate task-specific training into the knowledge distillation process to restore the performance of quantized detection networks. Extensive experiments conducted on the MS-COCO and Pascal VOC datasets demonstrate the efficiency and state-of-the-art performance of our method. Our code is publicly available at: https://github.com/DFQ-Dojo/dfq-toolkit .
MLE-Dojo: Interactive Environments for Empowering LLM Agents in Machine Learning Engineering
May 12, 2025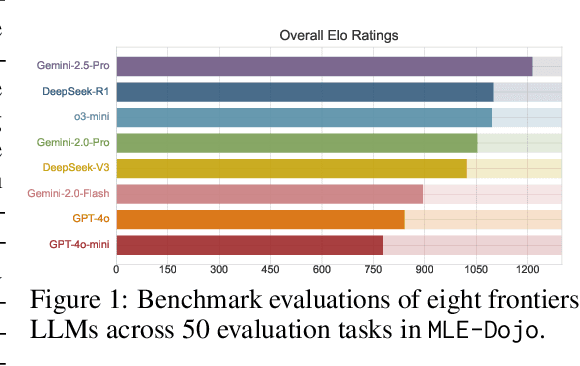



We introduce MLE-Dojo, a Gym-style framework for systematically reinforcement learning, evaluating, and improving autonomous large language model (LLM) agents in iterative machine learning engineering (MLE) workflows. Unlike existing benchmarks that primarily rely on static datasets or single-attempt evaluations, MLE-Dojo provides an interactive environment enabling agents to iteratively experiment, debug, and refine solutions through structured feedback loops. Built upon 200+ real-world Kaggle challenges, MLE-Dojo covers diverse, open-ended MLE tasks carefully curated to reflect realistic engineering scenarios such as data processing, architecture search, hyperparameter tuning, and code debugging. Its fully executable environment supports comprehensive agent training via both supervised fine-tuning and reinforcement learning, facilitating iterative experimentation, realistic data sampling, and real-time outcome verification. Extensive evaluations of eight frontier LLMs reveal that while current models achieve meaningful iterative improvements, they still exhibit significant limitations in autonomously generating long-horizon solutions and efficiently resolving complex errors. Furthermore, MLE-Dojo's flexible and extensible architecture seamlessly integrates diverse data sources, tools, and evaluation protocols, uniquely enabling model-based agent tuning and promoting interoperability, scalability, and reproducibility. We open-source our framework and benchmarks to foster community-driven innovation towards next-generation MLE agents.
MASH: Masked Anchored SpHerical Distances for 3D Shape Representation and Generation
Apr 12, 2025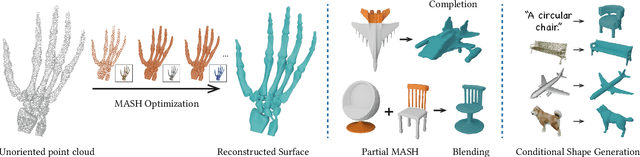
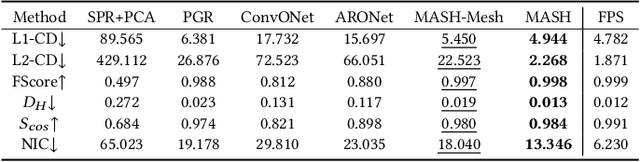
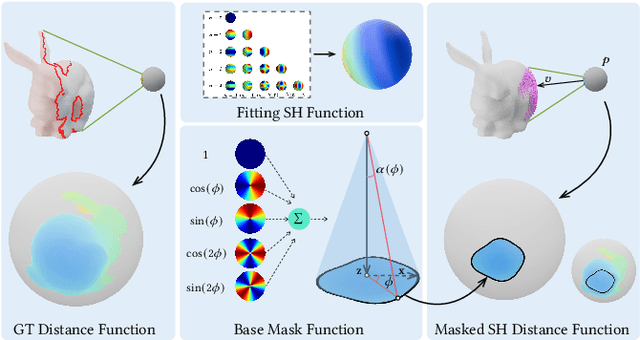

We introduce Masked Anchored SpHerical Distances (MASH), a novel multi-view and parametrized representation of 3D shapes. Inspired by multi-view geometry and motivated by the importance of perceptual shape understanding for learning 3D shapes, MASH represents a 3D shape as a collection of observable local surface patches, each defined by a spherical distance function emanating from an anchor point. We further leverage the compactness of spherical harmonics to encode the MASH functions, combined with a generalized view cone with a parameterized base that masks the spatial extent of the spherical function to attain locality. We develop a differentiable optimization algorithm capable of converting any point cloud into a MASH representation accurately approximating ground-truth surfaces with arbitrary geometry and topology. Extensive experiments demonstrate that MASH is versatile for multiple applications including surface reconstruction, shape generation, completion, and blending, achieving superior performance thanks to its unique representation encompassing both implicit and explicit features.
Matryoshka: Learning to Drive Black-Box LLMs with LLMs
Oct 28, 2024Despite the impressive generative abilities of black-box large language models (LLMs), their inherent opacity hinders further advancements in capabilities such as reasoning, planning, and personalization. Existing works aim to enhance LLM capabilities via domain-specific adaptation or in-context learning, which require additional training on accessible model parameters, an infeasible option for black-box LLMs. To address this challenge, we introduce Matryoshika, a lightweight white-box LLM controller that guides a large-scale black-box LLM generator by decomposing complex tasks into a series of intermediate outputs. Specifically, we consider the black-box LLM as an environment, with Matryoshika serving as a policy to provide intermediate guidance through prompts for driving the black-box LLM. Matryoshika is trained to pivot the outputs of the black-box LLM aligning with preferences during iterative interaction, which enables controllable multi-turn generation and self-improvement in optimizing intermediate guidance. Empirical evaluations on three diverse tasks demonstrate that Matryoshika effectively enhances the capabilities of black-box LLMs in complex, long-horizon tasks, including reasoning, planning, and personalization. By leveraging this pioneering controller-generator framework to mitigate dependence on model parameters, Matryoshika provides a transparent and practical solution for improving black-box LLMs through controllable multi-turn generation using white-box LLMs.
PruningBench: A Comprehensive Benchmark of Structural Pruning
Jun 18, 2024



Structural pruning has emerged as a promising approach for producing more efficient models. Nevertheless, the community suffers from a lack of standardized benchmarks and metrics, leaving the progress in this area not fully comprehended. To fill this gap, we present the first comprehensive benchmark, termed \textit{PruningBench}, for structural pruning. PruningBench showcases the following three characteristics: 1) PruningBench employs a unified and consistent framework for evaluating the effectiveness of diverse structural pruning techniques; 2) PruningBench systematically evaluates 16 existing pruning methods, encompassing a wide array of models (e.g., CNNs and ViTs) and tasks (e.g., classification and detection); 3) PruningBench provides easily implementable interfaces to facilitate the implementation of future pruning methods, and enables the subsequent researchers to incorporate their work into our leaderboards. We provide an online pruning platform http://pruning.vipazoo.cn for customizing pruning tasks and reproducing all results in this paper. Codes will be made publicly available.