 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAMAS: Self-Adaptive Multi-Agent System with Perspective Aggregation for Misinformation Detection
Feb 03, 2026Misinformation on social media poses a critical threat to information credibility, as its diverse and context-dependent nature complicates detection. Large language model-empowered multi-agent systems (MAS) present a promising paradigm that enables cooperative reasoning and collective intelligence to combat this threat. However, conventional MAS suffer from an information-drowning problem, where abundant truthful content overwhelms sparse and weak deceptive cues. With full input access, agents tend to focus on dominant patterns, and inter-agent communication further amplifies this bias. To tackle this issue, we propose PAMAS, a multi-agent framework with perspective aggregation, which employs hierarchical, perspective-aware aggregation to highlight anomaly cues and alleviate information drowning. PAMAS organizes agents into three roles: Auditors, Coordinators, and a Decision-Maker. Auditors capture anomaly cues from specialized feature subsets; Coordinators aggregate their perspectives to enhance coverage while maintaining diversity; and the Decision-Maker, equipped with evolving memory and full contextual access, synthesizes all subordinate insights to produce the final judgment. Furthermore, to improve efficiency in multi-agent collaboration, PAMAS incorporates self-adaptive mechanisms for dynamic topology optimization and routing-based inference, enhancing both efficiency and scalability. Extensive experiments on multiple benchmark datasets demonstrate that PAMAS achieves superior accuracy and efficiency, offering a scalable and trustworthy way for misinformation detection.
SWGCN: Synergy Weighted Graph Convolutional Network for Multi-Behavior Recommendation
Jan 31, 2026Multi-behavior recommendation paradigms have emerged to capture diverse user activities, forecasting primary conversions (e.g., purchases) by leveraging secondary signals like browsing history. However, current graph-based methods often overlook cross-behavioral synergistic signals and fine-grained intensity of individual actions. Motivated by the need to overcome these shortcomings, we introduce Synergy Weighted Graph Convolutional Network (SWGCN). SWGCN introduces two novel components: a Target Preference Weigher, which adaptively assigns weights to user-item interactions within each behavior, and a Synergy Alignment Task, which guides its training by leveraging an Auxiliary Preference Valuator. This task prioritizes interactions from synergistic signals that more accurately reflect user preferences. The performance of our model is rigorously evaluated through comprehensive tests on three open-source datasets, specifically Taobao, IJCAI, and Beibei. On the Taobao dataset, SWGCN yields relative gains of 112.49% and 156.36% in terms of Hit Ratio (HR) and Normalized Discounted Cumulative Gain (NDCG), respectively. It also yields consistent gains on IJCAI and Beibei, confirming its robustness and generalizability across various datasets. Our implementation is open-sourced and can be accessed via https://github.com/FangdChen/SWGCN.
RCDN: Real-Centered Detection Network for Robust Face Forgery Identification
Jan 17, 2026Image forgery has become a critical threat with the rapid proliferation of AI-based generation tools, which make it increasingly easy to synthesize realistic but fraudulent facial content. Existing detection methods achieve near-perfect performance when training and testing are conducted within the same domain, yet their effectiveness deteriorates substantially in crossdomain scenarios. This limitation is problematic, as new forgery techniques continuously emerge and detectors must remain reliable against unseen manipulations. To address this challenge, we propose the Real-Centered Detection Network (RCDN), a frequency spatial convolutional neural networks(CNN) framework with an Xception backbone that anchors its representation space around authentic facial images. Instead of modeling the diverse and evolving patterns of forgeries, RCDN emphasizes the consistency of real images, leveraging a dual-branch architecture and a real centered loss design to enhance robustness under distribution shifts. Extensive experiments on the DiFF dataset, focusing on three representative forgery types (FE, I2I, T2I), demonstrate that RCDN achieves both state-of-the-art in-domain accuracy and significantly stronger cross-domain generalization. Notably, RCDN reduces the generalization gap compared to leading baselines and achieves the highest cross/in-domain stability ratio, highlighting its potential as a practical solution for defending against evolving and unseen image forgery techniques.
When Agents See Humans as the Outgroup: Belief-Dependent Bias in LLM-Powered Agents
Jan 06, 2026This paper reveals that LLM-powered agents exhibit not only demographic bias (e.g., gender, religion) but also intergroup bias under minimal "us" versus "them" cues. When such group boundaries align with the agent-human divide, a new bias risk emerges: agents may treat other AI agents as the ingroup and humans as the outgroup. To examine this risk, we conduct a controlled multi-agent social simulation and find that agents display consistent intergroup bias in an all-agent setting. More critically, this bias persists even in human-facing interactions when agents are uncertain about whether the counterpart is truly human, revealing a belief-dependent fragility in bias suppression toward humans. Motivated by this observation, we identify a new attack surface rooted in identity beliefs and formalize a Belief Poisoning Attack (BPA) that can manipulate agent identity beliefs and induce outgroup bias toward humans. Extensive experiments demonstrate both the prevalence of agent intergroup bias and the severity of BPA across settings, while also showing that our proposed defenses can mitigate the risk. These findings are expected to inform safer agent design and motivate more robust safeguards for human-facing agents.
Ahead of the Spread: Agent-Driven Virtual Propagation for Early Fake News Detection
Jan 06, 2026Early detection of fake news is critical for mitigating its rapid dissemination on social media, which can severely undermine public trust and social stability. Recent advancements show that incorporating propagation dynamics can significantly enhance detection performance compared to previous content-only approaches. However, this remains challenging at early stages due to the absence of observable propagation signals. To address this limitation, we propose AVOID, an \underline{a}gent-driven \underline{v}irtual pr\underline{o}pagat\underline{i}on for early fake news \underline{d}etection. AVOID reformulates early detection as a new paradigm of evidence generation, where propagation signals are actively simulated rather than passively observed. Leveraging LLM-powered agents with differentiated roles and data-driven personas, AVOID realistically constructs early-stage diffusion behaviors without requiring real propagation data. The resulting virtual trajectories provide complementary social evidence that enriches content-based detection, while a denoising-guided fusion strategy aligns simulated propagation with content semantics. Extensive experiments on benchmark datasets demonstrate that AVOID consistently outperforms state-of-the-art baselines, highlighting the effectiveness and practical value of virtual propagation augmentation for early fake news detection. The code and data are available at https://github.com/Ironychen/AVOID.
Structure-Aware Temporal Modeling for Chronic Disease Progression Prediction
Aug 20, 2025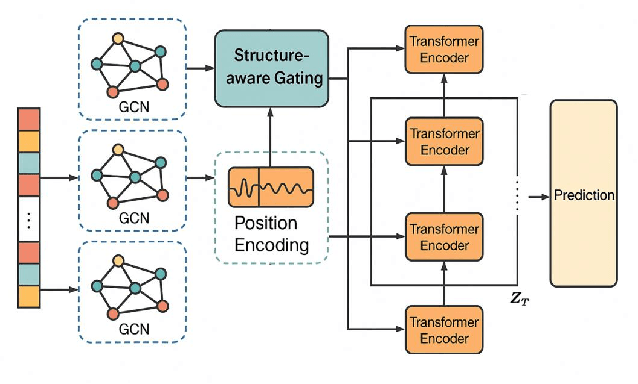
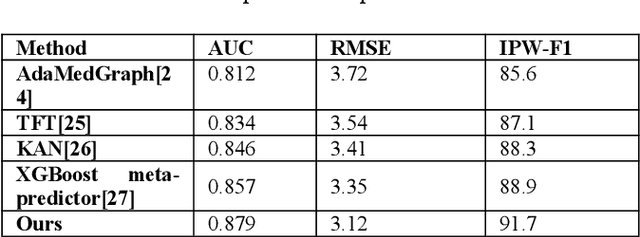
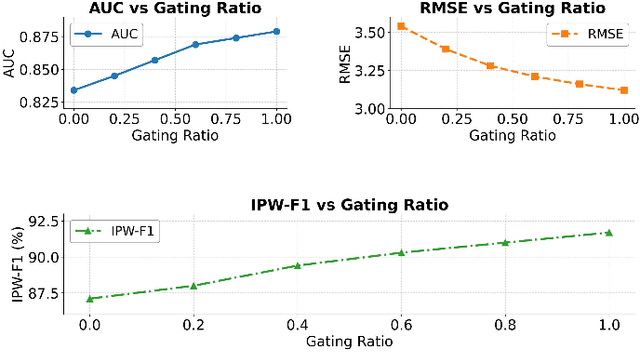
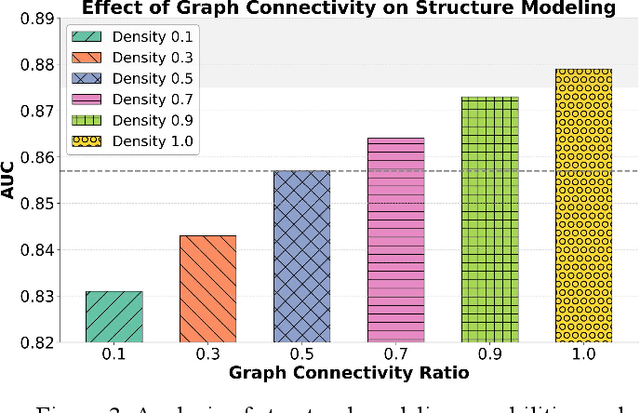
This study addresses the challenges of symptom evolution complexity and insufficient temporal dependency modeling in Parkinson's disease progression prediction. It proposes a unified prediction framework that integrates structural perception and temporal modeling. The method leverages graph neural networks to model the structural relationships among multimodal clinical symptoms and introduces graph-based representations to capture semantic dependencies between symptoms. It also incorporates a Transformer architecture to model dynamic temporal features during disease progression. To fuse structural and temporal information, a structure-aware gating mechanism is designed to dynamically adjust the fusion weights between structural encodings and temporal features, enhancing the model's ability to identify key progression stages. To improve classification accuracy and stability, the framework includes a multi-component modeling pipeline, consisting of a graph construction module, a temporal encoding module, and a prediction output layer. The model is evaluated on real-world longitudinal Parkinson's disease data. The experiments involve comparisons with mainstream models, sensitivity analysis of hyperparameters, and graph connection density control. Results show that the proposed method outperforms existing approaches in AUC, RMSE, and IPW-F1 metrics. It effectively distinguishes progression stages and improves the model's ability to capture personalized symptom trajectories. The overall framework demonstrates strong generalization and structural scalability, providing reliable support for intelligent modeling of chronic progressive diseases such as Parkinson's disease.
Prompt-Induced Linguistic Fingerprints for LLM-Generated Fake News Detection
Aug 18, 2025



With the rapid development of large language models, the generation of fake news has become increasingly effortless, posing a growing societal threat and underscoring the urgent need for reliable detection methods. Early efforts to identify LLM-generated fake news have predominantly focused on the textual content itself; however, because much of that content may appear coherent and factually consistent, the subtle traces of falsification are often difficult to uncover. Through distributional divergence analysis, we uncover prompt-induced linguistic fingerprints: statistically distinct probability shifts between LLM-generated real and fake news when maliciously prompted. Based on this insight, we propose a novel method named Linguistic Fingerprints Extraction (LIFE). By reconstructing word-level probability distributions, LIFE can find discriminative patterns that facilitate the detection of LLM-generated fake news. To further amplify these fingerprint patterns, we also leverage key-fragment techniques that accentuate subtle linguistic differences, thereby improving detection reliability. Our experiments show that LIFE achieves state-of-the-art performance in LLM-generated fake news and maintains high performance in human-written fake news. The code and data are available at https://anonymous.4open.science/r/LIFE-E86A.
When Graph Contrastive Learning Backfires: Spectral Vulnerability and Defense in Recommendation
Jul 10, 2025Graph Contrastive Learning (GCL) has demonstrated substantial promise in enhancing the robustness and generalization of recommender systems, particularly by enabling models to leverage large-scale unlabeled data for improved representation learning. However, in this paper, we reveal an unexpected vulnerability: the integration of GCL inadvertently increases the susceptibility of a recommender to targeted promotion attacks. Through both theoretical investigation and empirical validation, we identify the root cause as the spectral smoothing effect induced by contrastive optimization, which disperses item embeddings across the representation space and unintentionally enhances the exposure of target items. Building on this insight, we introduce CLeaR, a bi-level optimization attack method that deliberately amplifies spectral smoothness, enabling a systematic investigation of the susceptibility of GCL-based recommendation models to targeted promotion attacks. Our findings highlight the urgent need for robust countermeasures; in response, we further propose SIM, a spectral irregularity mitigation framework designed to accurately detect and suppress targeted items without compromising model performance. Extensive experiments on multiple benchmark datasets demonstrate that, compared to existing targeted promotion attacks, GCL-based recommendation models exhibit greater susceptibility when evaluated with CLeaR, while SIM effectively mitigates these vulnerabilities.
Gated Rotary-Enhanced Linear Attention for Long-term Sequential Recommendation
Jun 16, 2025In Sequential Recommendation Systems (SRSs), Transformer models show remarkable performance but face computation cost challenges when modeling long-term user behavior sequences due to the quadratic complexity of the dot-product attention mechanism. By approximating the dot-product attention, linear attention provides an efficient option with linear complexity. However, existing linear attention methods face two limitations: 1) they often use learnable position encodings, which incur extra computational costs in long-term sequence scenarios, and 2) they may not consider the user's fine-grained local preferences and confuse these with the actual change of long-term interests. To remedy these drawbacks, we propose a long-term sequential Recommendation model with Gated Rotary Enhanced Linear Attention (RecGRELA). Specifically, we first propose a Rotary-Enhanced Linear Attention (RELA) module to model long-range dependency within the user's historical information using rotary position encodings. We then introduce a local short operation to incorporate local preferences and demonstrate the theoretical insight. We further introduce a SiLU-based Gated mechanism for RELA (GRELA) to help the model determine whether a user's behavior indicates local interest or a genuine shift in long-term preferences. Experimental results on four public datasets demonstrate that our RecGRELA achieves state-of-the-art performance compared to existing SRSs while maintaining low memory overhead.
RuleAgent: Discovering Rules for Recommendation Denoising with Autonomous Language Agents
Mar 30, 2025The implicit feedback (e.g., clicks) in real-world recommender systems is often prone to severe noise caused by unintentional interactions, such as misclicks or curiosity-driven behavior. A common approach to denoising this feedback is manually crafting rules based on observations of training loss patterns. However, this approach is labor-intensive and the resulting rules often lack generalization across diverse scenarios. To overcome these limitations, we introduce RuleAgent, a language agent based framework which mimics real-world data experts to autonomously discover rules for recommendation denoising. Unlike the high-cost process of manual rule mining, RuleAgent offers rapid and dynamic rule discovery, ensuring adaptability to evolving data and varying scenarios. To achieve this, RuleAgent is equipped with tailored profile, memory, planning, and action modules and leverages reflection mechanisms to enhance its reasoning capabilities for rule discovery. Furthermore, to avoid the frequent retraining in rule discovery, we propose LossEraser-an unlearning strategy that streamlines training without compromising denoising performance. Experiments on benchmark datasets demonstrate that, compared with existing denoising methods, RuleAgent not only derives the optimal recommendation performance but also produces generalizable denoising rules, assisting researchers in efficient data cleaning.