 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on Adverse Drug Reaction Prediction Model Combining Knowledge Graph Embedding and Deep Learning
Jul 27, 2024
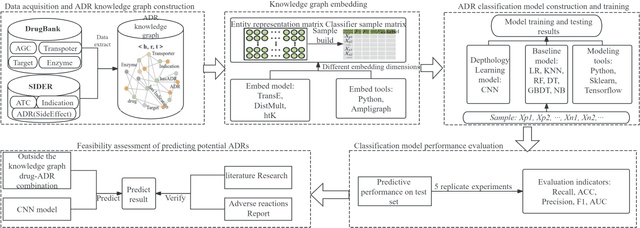
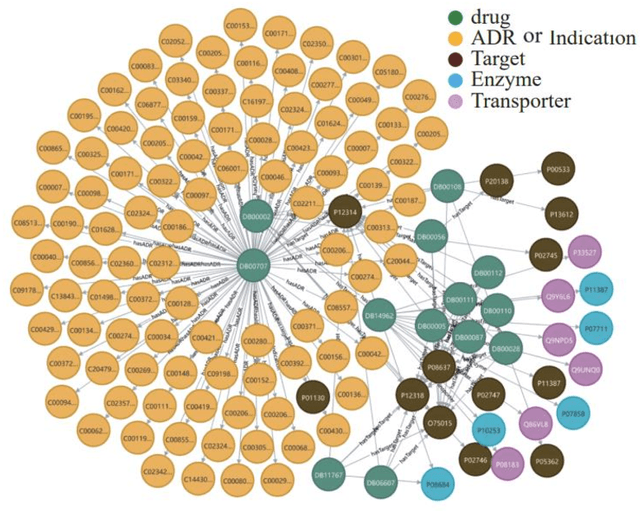

In clinical treatment, identifying potential adverse reactions of drugs can help assist doctors in making medication decisions. In response to the problems in previous studies that features are high-dimensional and sparse, independent prediction models need to be constructed for each adverse reaction of drugs, and the prediction accuracy is low, this paper develops an adverse drug reaction prediction model based on knowledge graph embedding and deep learning, which can predict experimental results. Unified prediction of adverse drug reactions covered. Knowledge graph embedding technology can fuse the associated information between drugs and alleviate the shortcomings of high-dimensional sparsity in feature matrices, and the efficient training capabilities of deep learning can improve the prediction accuracy of the model. This article builds an adverse drug reaction knowledge graph based on drug feature data; by analyzing the embedding effect of the knowledge graph under different embedding strategies, the best embedding strategy is selected to obtain sample vectors; and then a convolutional neural network model is constructed to predict adverse reactions. The results show that under the DistMult embedding model and 400-dimensional embedding strategy, the convolutional neural network model has the best prediction effect; the average accuracy, F_1 score, recall rate and area under the curve of repeated experiments are better than the methods reported in the literature. The obtained prediction model has good prediction accuracy and stability, and can provide an effective reference for later safe medication guidance.
Breast Cancer Image Classification Method Based on Deep Transfer Learning
Apr 14, 2024



To address the issues of limited samples, time-consuming feature design, and low accuracy in detection and classification of breast cancer pathological images, a breast cancer image classification model algorithm combining deep learning and transfer learning is proposed. This algorithm is based on the DenseNet structure of deep neural networks, and constructs a network model by introducing attention mechanisms, and trains the enhanced dataset using multi-level transfer learning. Experimental results demonstrate that the algorithm achieves an efficiency of over 84.0\% in the test set, with a significantly improved classification accuracy compared to previous models, making it applicable to medical breast cancer detection tasks.
RITFIS: Robust input testing framework for LLMs-based intelligent software
Feb 21, 2024The dependence of Natural Language Processing (NLP) intelligent software on Large Language Models (LLMs) is increasingly prominent, underscoring the necessity for robustness testing. Current testing methods focus solely on the robustness of LLM-based software to prompts. Given the complexity and diversity of real-world inputs, studying the robustness of LLMbased software in handling comprehensive inputs (including prompts and examples) is crucial for a thorough understanding of its performance. To this end, this paper introduces RITFIS, a Robust Input Testing Framework for LLM-based Intelligent Software. To our knowledge, RITFIS is the first framework designed to assess the robustness of LLM-based intelligent software against natural language inputs. This framework, based on given threat models and prompts, primarily defines the testing process as a combinatorial optimization problem. Successful test cases are determined by a goal function, creating a transformation space for the original examples through perturbation means, and employing a series of search methods to filter cases that meet both the testing objectives and language constraints. RITFIS, with its modular design, offers a comprehensive method for evaluating the robustness of LLMbased intelligent software. RITFIS adapts 17 automated testing methods, originally designed for Deep Neural Network (DNN)-based intelligent software, to the LLM-based software testing scenario. It demonstrates the effectiveness of RITFIS in evaluating LLM-based intelligent software through empirical validation. However, existing methods generally have limitations, especially when dealing with lengthy texts and structurally complex threat models. Therefore, we conducted a comprehensive analysis based on five metrics and provided insightful testing method optimization strategies, benefiting both researchers and everyday users.
LEAP: Efficient and Automated Test Method for NLP Software
Aug 22, 2023The widespread adoption of DNNs in NLP software has highlighted the need for robustness. Researchers proposed various automatic testing techniques for adversarial test cases. However, existing methods suffer from two limitations: weak error-discovering capabilities, with success rates ranging from 0% to 24.6% for BERT-based NLP software, and time inefficiency, taking 177.8s to 205.28s per test case, making them challenging for time-constrained scenarios. To address these issues, this paper proposes LEAP, an automated test method that uses LEvy flight-based Adaptive Particle swarm optimization integrated with textual features to generate adversarial test cases. Specifically, we adopt Levy flight for population initialization to increase the diversity of generated test cases. We also design an inertial weight adaptive update operator to improve the efficiency of LEAP's global optimization of high-dimensional text examples and a mutation operator based on the greedy strategy to reduce the search time. We conducted a series of experiments to validate LEAP's ability to test NLP software and found that the average success rate of LEAP in generating adversarial test cases is 79.1%, which is 6.1% higher than the next best approach (PSOattack). While ensuring high success rates, LEAP significantly reduces time overhead by up to 147.6s compared to other heuristic-based methods. Additionally, the experimental results demonstrate that LEAP can generate more transferable test cases and significantly enhance the robustness of DNN-based systems.