 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEET: A Million-Scale Dataset for Fine-Grained Geospatial Scene Classification with Zoom-Free Remote Sensing Imagery
Mar 14, 2025Accurate fine-grained geospatial scene classification using remote sensing imagery is essential for a wide range of applications. However, existing approaches often rely on manually zooming remote sensing images at different scales to create typical scene samples. This approach fails to adequately support the fixed-resolution image interpretation requirements in real-world scenarios. To address this limitation, we introduce the Million-scale finE-grained geospatial scEne classification dataseT (MEET), which contains over 1.03 million zoom-free remote sensing scene samples, manually annotated into 80 fine-grained categories. In MEET, each scene sample follows a scene-inscene layout, where the central scene serves as the reference, and auxiliary scenes provide crucial spatial context for finegrained classification. Moreover, to tackle the emerging challenge of scene-in-scene classification, we present the Context-Aware Transformer (CAT), a model specifically designed for this task, which adaptively fuses spatial context to accurately classify the scene samples. CAT adaptively fuses spatial context to accurately classify the scene samples by learning attentional features that capture the relationships between the center and auxiliary scenes. Based on MEET, we establish a comprehensive benchmark for fine-grained geospatial scene classification, evaluating CAT against 11 competitive baselines. The results demonstrate that CAT significantly outperforms these baselines, achieving a 1.88% higher balanced accuracy (BA) with the Swin-Large backbone, and a notable 7.87% improvement with the Swin-Huge backbone. Further experiments validate the effectiveness of each module in CAT and show the practical applicability of CAT in the urban functional zone mapping. The source code and dataset will be publicly available at https://jerrywyn.github.io/project/MEET.html.
Towards Privacy-preserved Pre-training of Remote Sensing Foundation Models with Federated Mutual-guidance Learning
Mar 14, 2025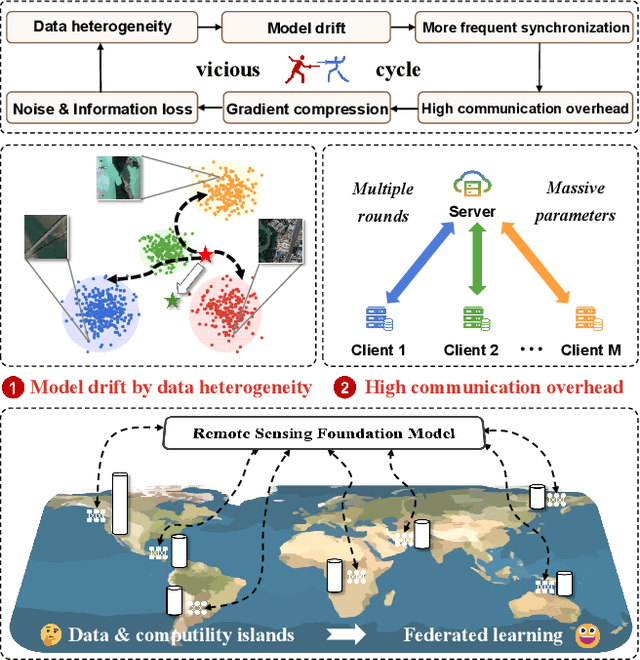
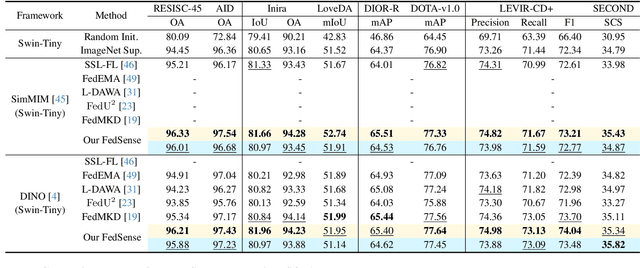
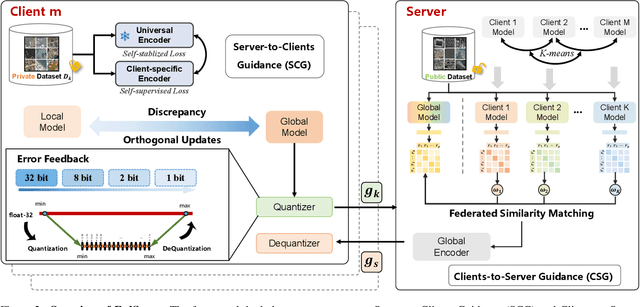
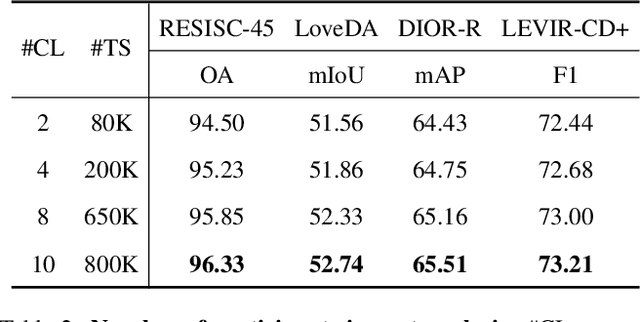
Traditional Remote Sensing Foundation models (RSFMs) are pre-trained with a data-centralized paradigm, through self-supervision on large-scale curated remote sensing data. For each institution, however, pre-training RSFMs with limited data in a standalone manner may lead to suboptimal performance, while aggregating remote sensing data from multiple institutions for centralized pre-training raises privacy concerns. Seeking for collaboration is a promising solution to resolve this dilemma, where multiple institutions can collaboratively train RSFMs without sharing private data. In this paper, we propose a novel privacy-preserved pre-training framework (FedSense), which enables multiple institutions to collaboratively train RSFMs without sharing private data. However, it is a non-trivial task hindered by a vicious cycle, which results from model drift by remote sensing data heterogeneity and high communication overhead. To break this vicious cycle, we introduce Federated Mutual-guidance Learning. Specifically, we propose a Server-to-Clients Guidance (SCG) mechanism to guide clients updates towards global-flatness optimal solutions. Additionally, we propose a Clients-to-Server Guidance (CSG) mechanism to inject local knowledge into the server by low-bit communication. Extensive experiments on four downstream tasks demonstrate the effectiveness of our FedSense in both full-precision and communication-reduced scenarios, showcasing remarkable communication efficiency and performance gains.
Research on Adverse Drug Reaction Prediction Model Combining Knowledge Graph Embedding and Deep Learning
Jul 27, 2024
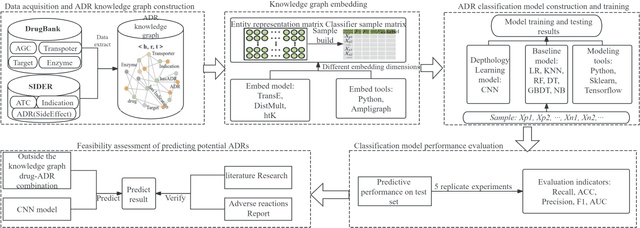
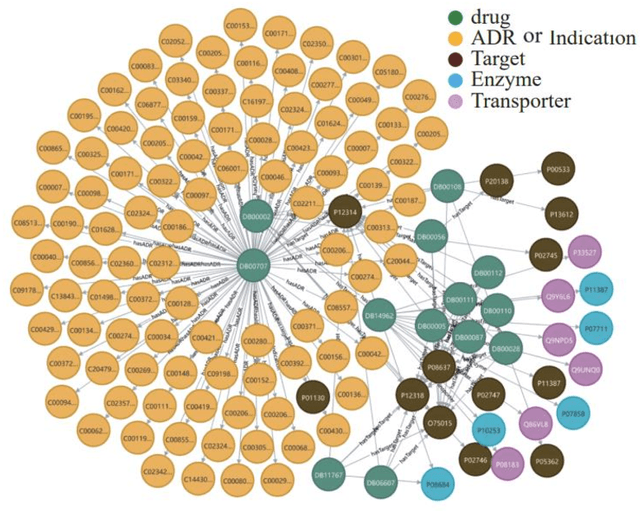

In clinical treatment, identifying potential adverse reactions of drugs can help assist doctors in making medication decisions. In response to the problems in previous studies that features are high-dimensional and sparse, independent prediction models need to be constructed for each adverse reaction of drugs, and the prediction accuracy is low, this paper develops an adverse drug reaction prediction model based on knowledge graph embedding and deep learning, which can predict experimental results. Unified prediction of adverse drug reactions covered. Knowledge graph embedding technology can fuse the associated information between drugs and alleviate the shortcomings of high-dimensional sparsity in feature matrices, and the efficient training capabilities of deep learning can improve the prediction accuracy of the model. This article builds an adverse drug reaction knowledge graph based on drug feature data; by analyzing the embedding effect of the knowledge graph under different embedding strategies, the best embedding strategy is selected to obtain sample vectors; and then a convolutional neural network model is constructed to predict adverse reactions. The results show that under the DistMult embedding model and 400-dimensional embedding strategy, the convolutional neural network model has the best prediction effect; the average accuracy, F_1 score, recall rate and area under the curve of repeated experiments are better than the methods reported in the literature. The obtained prediction model has good prediction accuracy and stability, and can provide an effective reference for later safe medication guidance.
SkySenseGPT: A Fine-Grained Instruction Tuning Dataset and Model for Remote Sensing Vision-Language Understanding
Jun 14, 2024Remote Sensing Large Multi-Modal Models (RSLMMs) are developing rapidly and showcase significant capabilities in remote sensing imagery (RSI) comprehension. However, due to the limitations of existing datasets, RSLMMs have shortcomings in understanding the rich semantic relations among objects in complex remote sensing scenes. To unlock RSLMMs' complex comprehension ability, we propose a large-scale instruction tuning dataset FIT-RS, containing 1,800,851 instruction samples. FIT-RS covers common interpretation tasks and innovatively introduces several complex comprehension tasks of escalating difficulty, ranging from relation reasoning to image-level scene graph generation. Based on FIT-RS, we build the FIT-RSFG benchmark. Furthermore, we establish a new benchmark to evaluate the fine-grained relation comprehension capabilities of LMMs, named FIT-RSRC. Based on combined instruction data, we propose SkySenseGPT, which achieves outstanding performance on both public datasets and FIT-RSFG, surpassing existing RSLMMs. We hope the FIT-RS dataset can enhance the relation comprehension capability of RSLMMs and provide a large-scale fine-grained data source for the remote sensing community. The dataset will be available at https://github.com/Luo-Z13/SkySenseGPT
Scene Graph Generation in Large-Size VHR Satellite Imagery: A Large-Scale Dataset and A Context-Aware Approach
Jun 13, 2024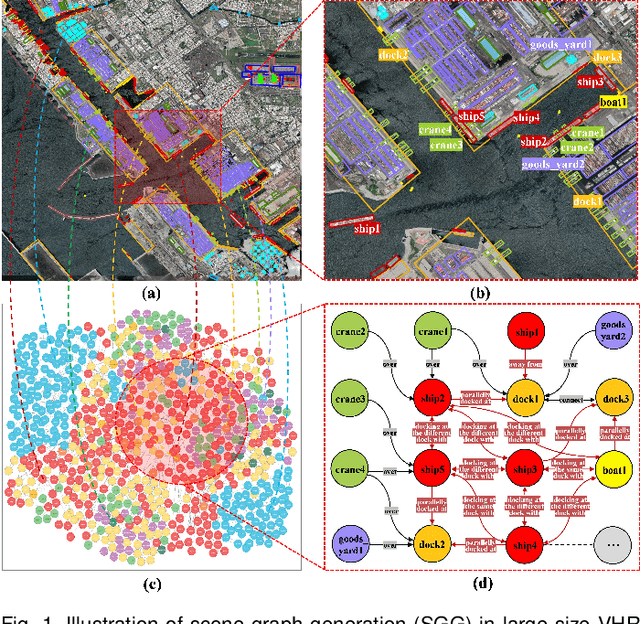
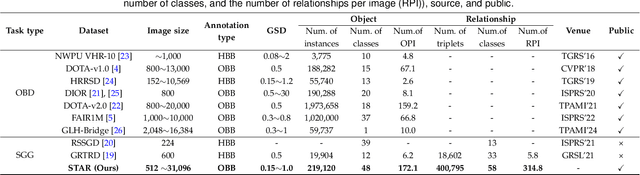
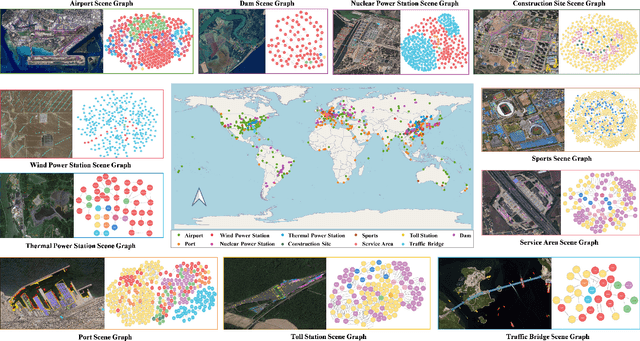
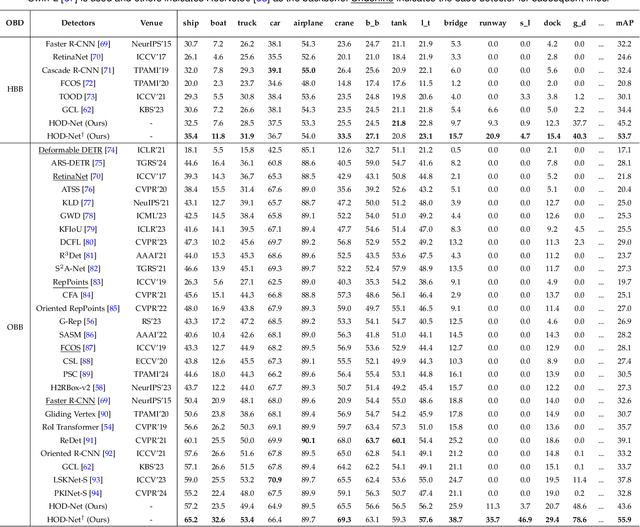
Scene graph generation (SGG) in satellite imagery (SAI) benefits promoting intelligent understanding of geospatial scenarios from perception to cognition. In SAI, objects exhibit great variations in scales and aspect ratios, and there exist rich relationships between objects (even between spatially disjoint objects), which makes it necessary to holistically conduct SGG in large-size very-high-resolution (VHR) SAI. However, the lack of SGG datasets with large-size VHR SAI has constrained the advancement of SGG in SAI. Due to the complexity of large-size VHR SAI, mining triplets <subject, relationship, object> in large-size VHR SAI heavily relies on long-range contextual reasoning. Consequently, SGG models designed for small-size natural imagery are not directly applicable to large-size VHR SAI. To address the scarcity of datasets, this paper constructs a large-scale dataset for SGG in large-size VHR SAI with image sizes ranging from 512 x 768 to 27,860 x 31,096 pixels, named RSG, encompassing over 210,000 objects and more than 400,000 triplets. To realize SGG in large-size VHR SAI, we propose a context-aware cascade cognition (CAC) framework to understand SAI at three levels: object detection (OBD), pair pruning and relationship prediction. As a fundamental prerequisite for SGG in large-size SAI, a holistic multi-class object detection network (HOD-Net) that can flexibly integrate multi-scale contexts is proposed. With the consideration that there exist a huge amount of object pairs in large-size SAI but only a minority of object pairs contain meaningful relationships, we design a pair proposal generation (PPG) network via adversarial reconstruction to select high-value pairs. Furthermore, a relationship prediction network with context-aware messaging (RPCM) is proposed to predict the relationship types of these pairs.
Real-Time Pill Identification for the Visually Impaired Using Deep Learning
May 08, 2024The prevalence of mobile technology offers unique opportunities for addressing healthcare challenges, especially for individuals with visual impairments. This paper explores the development and implementation of a deep learning-based mobile application designed to assist blind and visually impaired individuals in real-time pill identification. Utilizing the YOLO framework, the application aims to accurately recognize and differentiate between various pill types through real-time image processing on mobile devices. The system incorporates Text-to- Speech (TTS) to provide immediate auditory feedback, enhancing usability and independence for visually impaired users. Our study evaluates the application's effectiveness in terms of detection accuracy and user experience, highlighting its potential to improve medication management and safety among the visually impaired community. Keywords-Deep Learning; YOLO Framework; Mobile Application; Visual Impairment; Pill Identification; Healthcare
U2++ MoE: Scaling 4.7x parameters with minimal impact on RTF
Apr 25, 2024



Scale has opened new frontiers in natural language processing, but at a high cost. In response, by learning to only activate a subset of parameters in training and inference, Mixture-of-Experts (MoE) have been proposed as an energy efficient path to even larger and more capable language models and this shift towards a new generation of foundation models is gaining momentum, particularly within the field of Automatic Speech Recognition (ASR). Recent works that incorporating MoE into ASR models have complex designs such as routing frames via supplementary embedding network, improving multilingual ability for the experts, and utilizing dedicated auxiliary losses for either expert load balancing or specific language handling. We found that delicate designs are not necessary, while an embarrassingly simple substitution of MoE layers for all Feed-Forward Network (FFN) layers is competent for the ASR task. To be more specific, we benchmark our proposed model on a large scale inner-source dataset (160k hours), the results show that we can scale our baseline Conformer (Dense-225M) to its MoE counterparts (MoE-1B) and achieve Dense-1B level Word Error Rate (WER) while maintaining a Dense-225M level Real Time Factor (RTF). Furthermore, by applying Unified 2-pass framework with bidirectional attention decoders (U2++), we achieve the streaming and non-streaming decoding modes in a single MoE based model, which we call U2++ MoE. We hope that our study can facilitate the research on scaling speech foundation models without sacrificing deployment efficiency.
Bridging Data Islands: Geographic Heterogeneity-Aware Federated Learning for Collaborative Remote Sensing Semantic Segmentation
Apr 14, 2024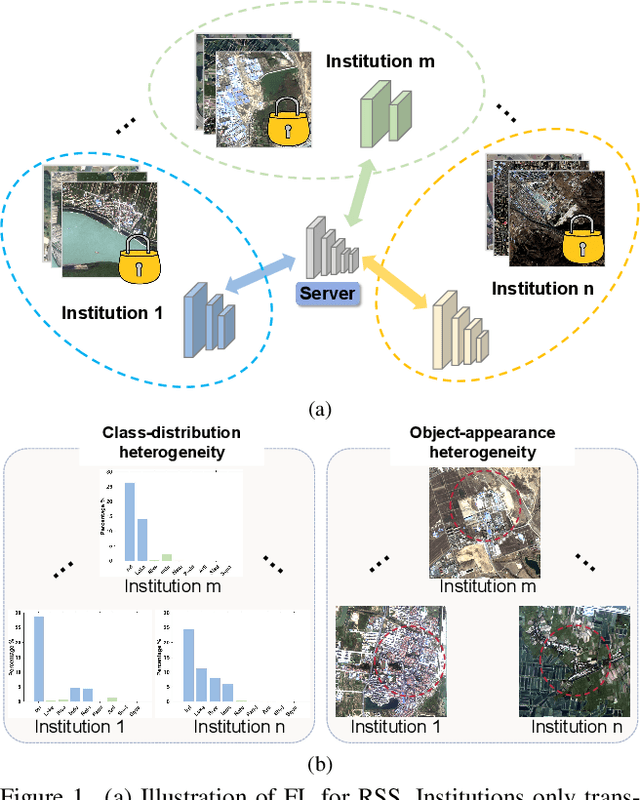

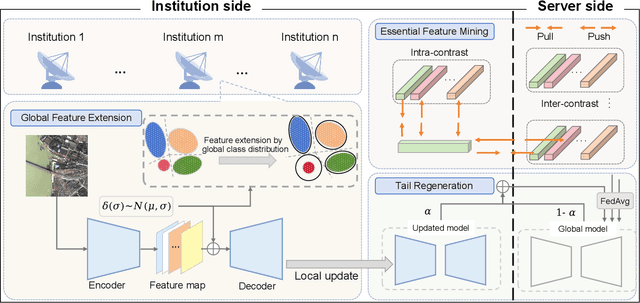

Remote sensing semantic segmentation (RSS) is an essential task in Earth Observation missions. Due to data privacy concerns, high-quality remote sensing images with annotations cannot be well shared among institutions, making it difficult to fully utilize RSS data to train a generalized model. Federated Learning (FL), a privacy-preserving collaborative learning technology, is a potential solution. However, the current research on how to effectively apply FL in RSS is still scarce and requires further investigation. Remote sensing images in various institutions often exhibit strong geographical heterogeneity. More specifically, it is reflected in terms of class-distribution heterogeneity and object-appearance heterogeneity. Unfortunately, most existing FL studies show inadequate focus on geographical heterogeneity, thus leading to performance degradation in the global model. Considering the aforementioned issues, we propose a novel Geographic Heterogeneity-Aware Federated Learning (GeoFed) framework to address privacy-preserving RSS. Through Global Feature Extension and Tail Regeneration modules, class-distribution heterogeneity is alleviated. Additionally, we design an Essential Feature Mining strategy to alleviate object-appearance heterogeneity by constructing essential features. Extensive experiments on three datasets (i.e., FBP, CASID, Inria) show that our GeoFed consistently outperforms the current state-of-the-art methods. The code will be available publicly.
Leveraging Deep Learning and Xception Architecture for High-Accuracy MRI Classification in Alzheimer Diagnosis
Mar 24, 2024
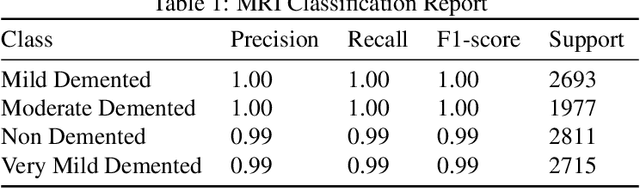
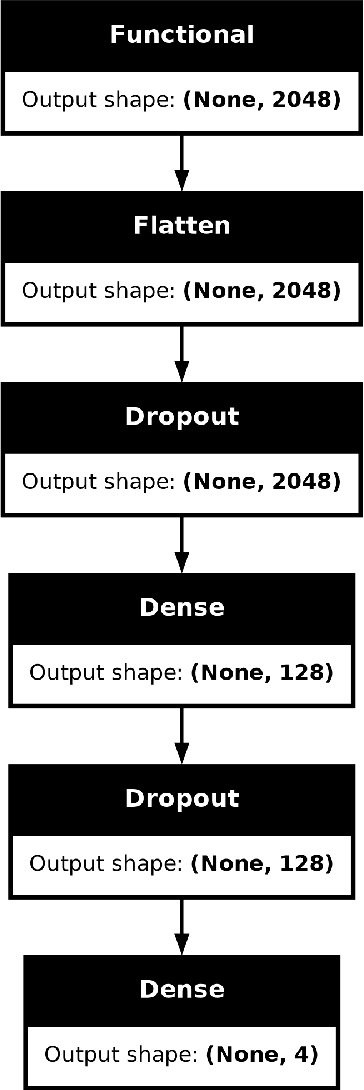
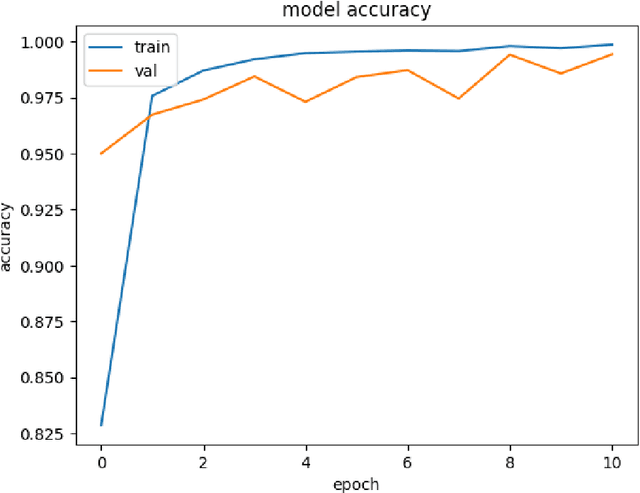
Exploring the application of deep learning technologies in the field of medical diagnostics, Magnetic Resonance Imaging (MRI) provides a unique perspective for observing and diagnosing complex neurodegenerative diseases such as Alzheimer Disease (AD). With advancements in deep learning, particularly in Convolutional Neural Networks (CNNs) and the Xception network architecture, we are now able to analyze and classify vast amounts of MRI data with unprecedented accuracy. The progress of this technology not only enhances our understanding of brain structural changes but also opens up new avenues for monitoring disease progression through non-invasive means and potentially allows for precise diagnosis in the early stages of the disease. This study aims to classify MRI images using deep learning models to identify different stages of Alzheimer Disease through a series of innovative data processing and model construction steps. Our experimental results show that the deep learning framework based on the Xception model achieved a 99.6% accuracy rate in the multi-class MRI image classification task, demonstrating its potential application value in assistive diagnosis. Future research will focus on expanding the dataset, improving model interpretability, and clinical validation to further promote the application of deep learning technology in the medical field, with the hope of bringing earlier diagnosis and more personalized treatment plans to Alzheimer Disease patients.
Utilizing the LightGBM Algorithm for Operator User Credit Assessment Research
Mar 21, 2024



Mobile Internet user credit assessment is an important way for communication operators to establish decisions and formulate measures, and it is also a guarantee for operators to obtain expected benefits. However, credit evaluation methods have long been monopolized by financial industries such as banks and credit. As supporters and providers of platform network technology and network resources, communication operators are also builders and maintainers of communication networks. Internet data improves the user's credit evaluation strategy. This paper uses the massive data provided by communication operators to carry out research on the operator's user credit evaluation model based on the fusion LightGBM algorithm. First, for the massive data related to user evaluation provided by operators, key features are extracted by data preprocessing and feature engineering methods, and a multi-dimensional feature set with statistical significance is constructed; then, linear regression, decision tree, LightGBM, and other machine learning algorithms build multiple basic models to find the best basic model; finally, integrates Averaging, Voting, Blending, Stacking and other integrated algorithms to refine multiple fusion models, and finally establish the most suitable fusion model for operator user evaluation.