 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Adaboost Algorithm for Web Advertisement Click Prediction Based on Long Short-Term Memory Networks
Aug 08, 2024
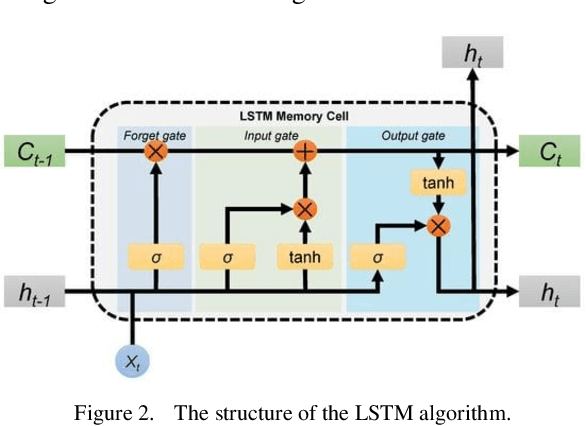
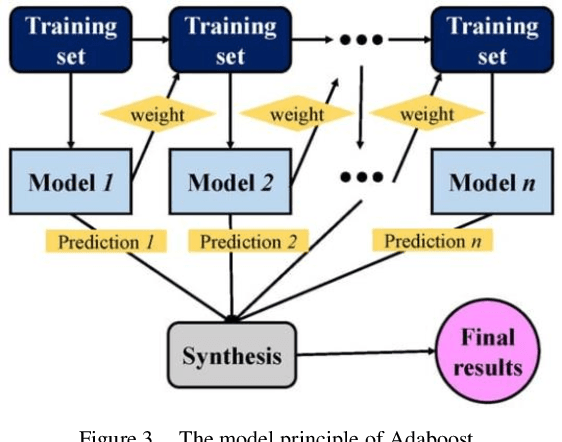
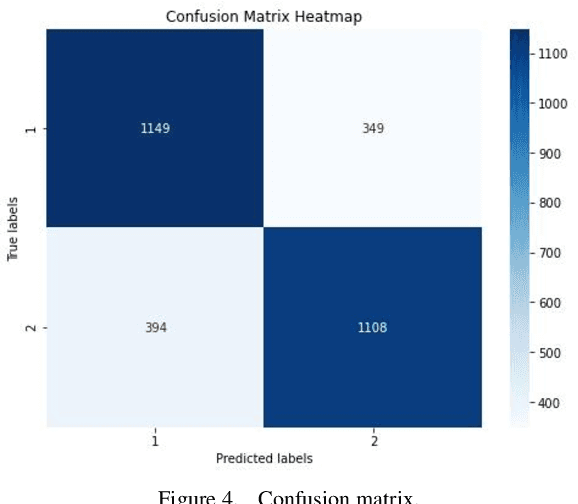
This paper explores an improved Adaboost algorithm based on Long Short-Term Memory Networks (LSTMs), which aims to improve the prediction accuracy of user clicks on web page advertisements. By comparing it with several common machine learning algorithms, the paper analyses the advantages of the new model in ad click prediction. It is shown that the improved algorithm proposed in this paper performs well in user ad click prediction with an accuracy of 92%, which is an improvement of 13.6% compared to the highest of 78.4% among the other three base models. This significant improvement indicates that the algorithm is more capable of capturing user behavioural characteristics and time series patterns. In addition, this paper evaluates the model's performance on other performance metrics, including accuracy, recall, and F1 score. The results show that the improved Adaboost algorithm based on LSTM is significantly ahead of the traditional model in all these metrics, which further validates its effectiveness and superiority. Especially when facing complex and dynamically changing user behaviours, the model is able to better adapt and make accurate predictions. In order to ensure the practicality and reliability of the model, this study also focuses on the accuracy difference between the training set and the test set. After validation, the accuracy of the proposed model on these two datasets only differs by 1.7%, which is a small difference indicating that the model has good generalisation ability and can be effectively applied to real-world scenarios.
Regression prediction algorithm for energy consumption regression in cloud computing based on horned lizard algorithm optimised convolutional neural network-bidirectional gated recurrent unit
Jul 26, 2024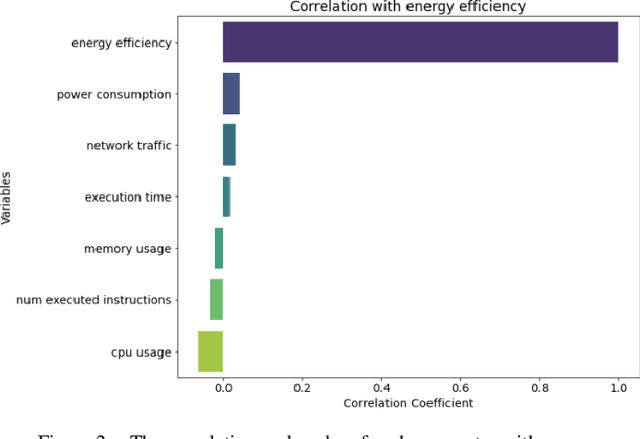
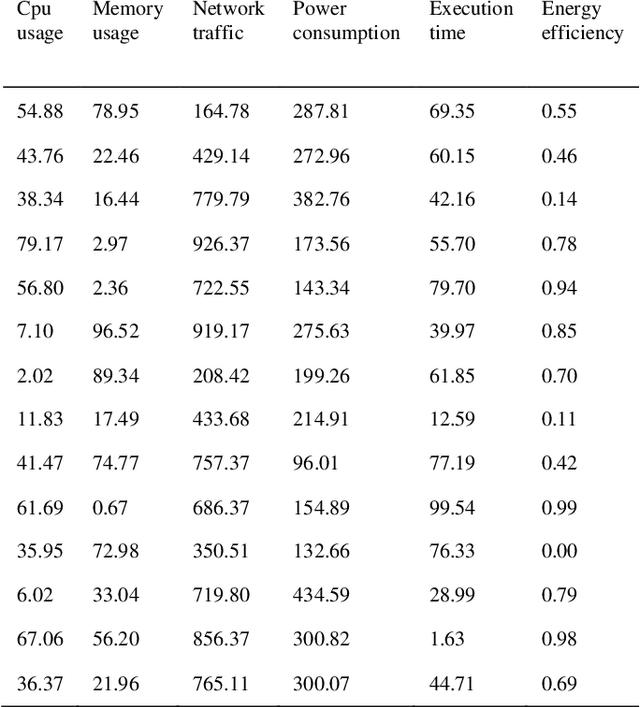
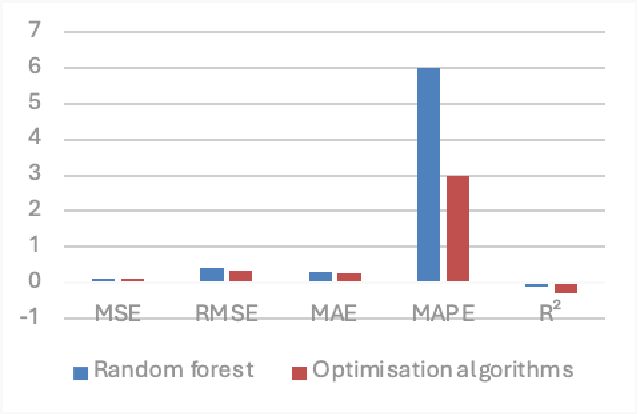
For this paper, a prediction study of cloud computing energy consumption was conducted by optimising the data regression algorithm based on the horned lizard optimisation algorithm for Convolutional Neural Networks-Bi-Directional Gated Recurrent Units. Firstly, through Spearman correlation analysis of CPU, usage, memory usage, network traffic, power consumption, number of instructions executed, execution time and energy efficiency, we found that power consumption has the highest degree of positive correlation with energy efficiency, while CPU usage has the highest degree of negative correlation with energy efficiency. In our experiments, we introduced a random forest model and an optimisation model based on the horned lizard optimisation algorithm for testing, and the results show that the optimisation algorithm has better prediction results compared to the random forest model. Specifically, the mean square error (MSE) of the optimisation algorithm is 0.01 smaller than that of the random forest model, and the mean absolute error (MAE) is 0.01 smaller than that of the random forest.3 The results of the combined metrics show that the optimisation algorithm performs more accurately and reliably in predicting energy efficiency. This research result provides new ideas and methods to improve the energy efficiency of cloud computing systems. This research not only expands the scope of application in the field of cloud computing, but also provides a strong support for improving the energy use efficiency of the system.
Real-Time Pill Identification for the Visually Impaired Using Deep Learning
May 08, 2024The prevalence of mobile technology offers unique opportunities for addressing healthcare challenges, especially for individuals with visual impairments. This paper explores the development and implementation of a deep learning-based mobile application designed to assist blind and visually impaired individuals in real-time pill identification. Utilizing the YOLO framework, the application aims to accurately recognize and differentiate between various pill types through real-time image processing on mobile devices. The system incorporates Text-to- Speech (TTS) to provide immediate auditory feedback, enhancing usability and independence for visually impaired users. Our study evaluates the application's effectiveness in terms of detection accuracy and user experience, highlighting its potential to improve medication management and safety among the visually impaired community. Keywords-Deep Learning; YOLO Framework; Mobile Application; Visual Impairment; Pill Identification; Healthcare
Drawing Robust Scratch Tickets: Subnetworks with Inborn Robustness Are Found within Randomly Initialized Networks
Nov 06, 2021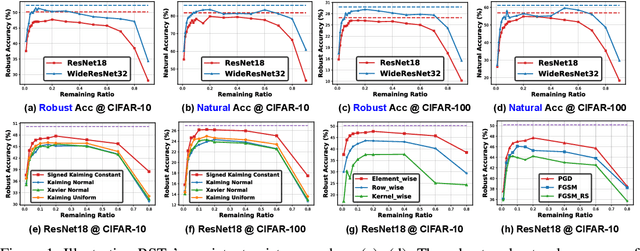
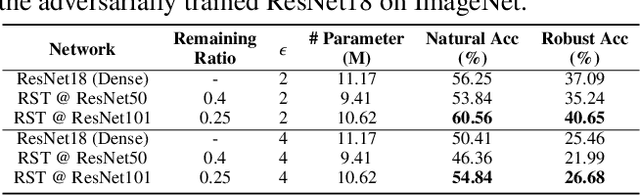
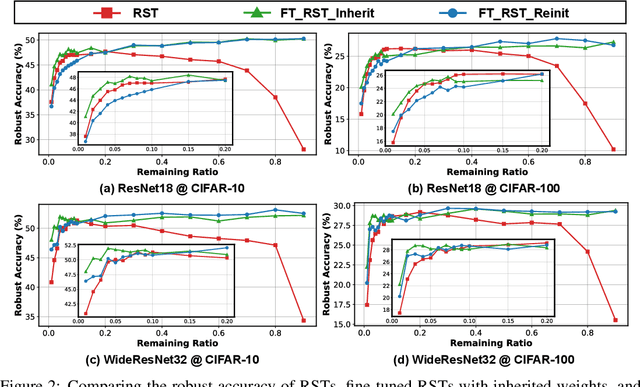
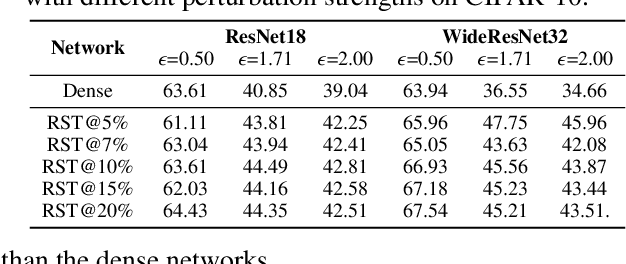
Deep Neural Networks (DNNs) are known to be vulnerable to adversarial attacks, i.e., an imperceptible perturbation to the input can mislead DNNs trained on clean images into making erroneous predictions. To tackle this, adversarial training is currently the most effective defense method, by augmenting the training set with adversarial samples generated on the fly. Interestingly, we discover for the first time that there exist subnetworks with inborn robustness, matching or surpassing the robust accuracy of the adversarially trained networks with comparable model sizes, within randomly initialized networks without any model training, indicating that adversarial training on model weights is not indispensable towards adversarial robustness. We name such subnetworks Robust Scratch Tickets (RSTs), which are also by nature efficient. Distinct from the popular lottery ticket hypothesis, neither the original dense networks nor the identified RSTs need to be trained. To validate and understand this fascinating finding, we further conduct extensive experiments to study the existence and properties of RSTs under different models, datasets, sparsity patterns, and attacks, drawing insights regarding the relationship between DNNs' robustness and their initialization/overparameterization. Furthermore, we identify the poor adversarial transferability between RSTs of different sparsity ratios drawn from the same randomly initialized dense network, and propose a Random RST Switch (R2S) technique, which randomly switches between different RSTs, as a novel defense method built on top of RSTs. We believe our findings about RSTs have opened up a new perspective to study model robustness and extend the lottery ticket hypothesis.
2-in-1 Accelerator: Enabling Random Precision Switch for Winning Both Adversarial Robustness and Efficiency
Sep 21, 2021
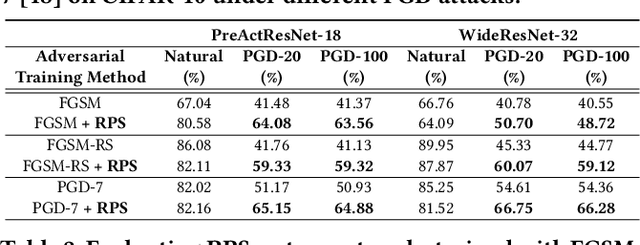

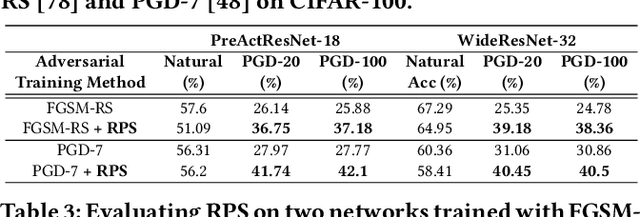
The recent breakthroughs of deep neural networks (DNNs) and the advent of billions of Internet of Things (IoT) devices have excited an explosive demand for intelligent IoT devices equipped with domain-specific DNN accelerators. However, the deployment of DNN accelerator enabled intelligent functionality into real-world IoT devices still remains particularly challenging. First, powerful DNNs often come at prohibitive complexities, whereas IoT devices often suffer from stringent resource constraints. Second, while DNNs are vulnerable to adversarial attacks especially on IoT devices exposed to complex real-world environments, many IoT applications require strict security. Existing DNN accelerators mostly tackle only one of the two aforementioned challenges (i.e., efficiency or adversarial robustness) while neglecting or even sacrificing the other. To this end, we propose a 2-in-1 Accelerator, an integrated algorithm-accelerator co-design framework aiming at winning both the adversarial robustness and efficiency of DNN accelerators. Specifically, we first propose a Random Precision Switch (RPS) algorithm that can effectively defend DNNs against adversarial attacks by enabling random DNN quantization as an in-situ model switch. Furthermore, we propose a new precision-scalable accelerator featuring (1) a new precision-scalable MAC unit architecture which spatially tiles the temporal MAC units to boost both the achievable efficiency and flexibility and (2) a systematically optimized dataflow that is searched by our generic accelerator optimizer. Extensive experiments and ablation studies validate that our 2-in-1 Accelerator can not only aggressively boost both the adversarial robustness and efficiency of DNN accelerators under various attacks, but also naturally support instantaneous robustness-efficiency trade-offs adapting to varied resources without the necessity of DNN retraining.
HW-NAS-Bench:Hardware-Aware Neural Architecture Search Benchmark
Mar 19, 2021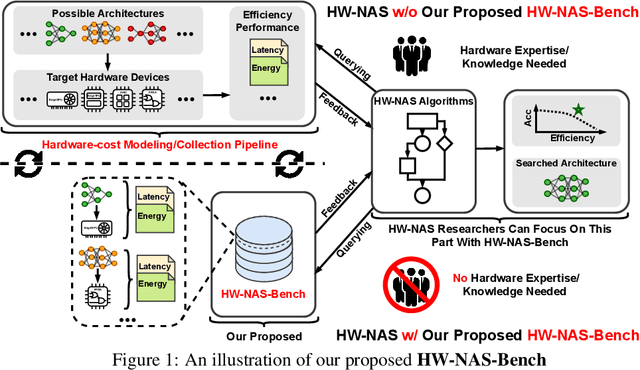
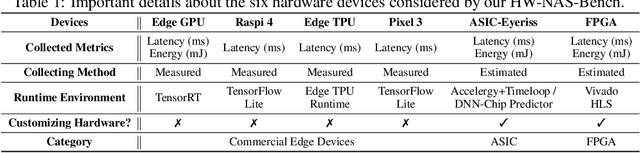
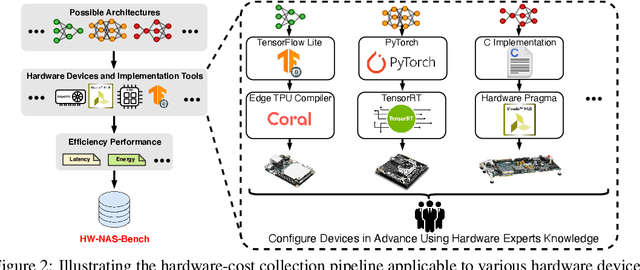

HardWare-aware Neural Architecture Search (HW-NAS) has recently gained tremendous attention by automating the design of DNNs deployed in more resource-constrained daily life devices. Despite its promising performance, developing optimal HW-NAS solutions can be prohibitively challenging as it requires cross-disciplinary knowledge in the algorithm, micro-architecture, and device-specific compilation. First, to determine the hardware-cost to be incorporated into the NAS process, existing works mostly adopt either pre-collected hardware-cost look-up tables or device-specific hardware-cost models. Both of them limit the development of HW-NAS innovations and impose a barrier-to-entry to non-hardware experts. Second, similar to generic NAS, it can be notoriously difficult to benchmark HW-NAS algorithms due to their significant required computational resources and the differences in adopted search spaces, hyperparameters, and hardware devices. To this end, we develop HW-NAS-Bench, the first public dataset for HW-NAS research which aims to democratize HW-NAS research to non-hardware experts and make HW-NAS research more reproducible and accessible. To design HW-NAS-Bench, we carefully collected the measured/estimated hardware performance of all the networks in the search spaces of both NAS-Bench-201 and FBNet, on six hardware devices that fall into three categories (i.e., commercial edge devices, FPGA, and ASIC). Furthermore, we provide a comprehensive analysis of the collected measurements in HW-NAS-Bench to provide insights for HW-NAS research. Finally, we demonstrate exemplary user cases to (1) show that HW-NAS-Bench allows non-hardware experts to perform HW-NAS by simply querying it and (2) verify that dedicated device-specific HW-NAS can indeed lead to optimal accuracy-cost trade-offs. The codes and all collected data are available at https://github.com/RICE-EIC/HW-NAS-Bench.