 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Text to Image Synthesis
Dec 10, 2024Fine-grained text to image synthesis involves generating images from texts that belong to different categories. In contrast to general text to image synthesis, in fine-grained synthesis there is high similarity between images of different subclasses, and there may be linguistic discrepancy among texts describing the same image. Recent Generative Adversarial Networks (GAN), such as the Recurrent Affine Transformation (RAT) GAN model, are able to synthesize clear and realistic images from texts. However, GAN models ignore fine-grained level information. In this paper we propose an approach that incorporates an auxiliary classifier in the discriminator and a contrastive learning method to improve the accuracy of fine-grained details in images synthesized by RAT GAN. The auxiliary classifier helps the discriminator classify the class of images, and helps the generator synthesize more accurate fine-grained images. The contrastive learning method minimizes the similarity between images from different subclasses and maximizes the similarity between images from the same subclass. We evaluate on several state-of-the-art methods on the commonly used CUB-200-2011 bird dataset and Oxford-102 flower dataset, and demonstrated superior performance.
Low-Bit Quantization Favors Undertrained LLMs: Scaling Laws for Quantized LLMs with 100T Training Tokens
Nov 26, 2024



We reveal that low-bit quantization favors undertrained large language models (LLMs) by observing that models with larger sizes or fewer training tokens experience less quantization-induced degradation (QiD) when applying low-bit quantization, whereas smaller models with extensive training tokens suffer significant QiD. To gain deeper insights into this trend, we study over 1500 quantized LLM checkpoints of various sizes and at different training levels (undertrained or fully trained) in a controlled setting, deriving scaling laws for understanding the relationship between QiD and factors such as the number of training tokens, model size and bit width. With the derived scaling laws, we propose a novel perspective that we can use QiD to measure an LLM's training levels and determine the number of training tokens required for fully training LLMs of various sizes. Moreover, we use the scaling laws to predict the quantization performance of different-sized LLMs trained with 100 trillion tokens. Our projection shows that the low-bit quantization performance of future models, which are expected to be trained with over 100 trillion tokens, may NOT be desirable. This poses a potential challenge for low-bit quantization in the future and highlights the need for awareness of a model's training level when evaluating low-bit quantization research. To facilitate future research on this problem, we release all the 1500+ quantized checkpoints used in this work at https://huggingface.co/Xu-Ouyang.
Secure and Effective Data Appraisal for Machine Learning
Oct 05, 2023



Essential for an unfettered data market is the ability to discreetly select and evaluate training data before finalizing a transaction between the data owner and model owner. To safeguard the privacy of both data and model, this process involves scrutinizing the target model through Multi-Party Computation (MPC). While prior research has posited that the MPC-based evaluation of Transformer models is excessively resource-intensive, this paper introduces an innovative approach that renders data selection practical. The contributions of this study encompass three pivotal elements: (1) a groundbreaking pipeline for confidential data selection using MPC, (2) replicating intricate high-dimensional operations with simplified low-dimensional MLPs trained on a limited subset of pertinent data, and (3) implementing MPC in a concurrent, multi-phase manner. The proposed method is assessed across an array of Transformer models and NLP/CV benchmarks. In comparison to the direct MPC-based evaluation of the target model, our approach substantially reduces the time required, from thousands of hours to mere tens of hours, with only a nominal 0.20% dip in accuracy when training with the selected data.
Efficient Model Finetuning for Text Classification via Data Filtering
Jul 28, 2022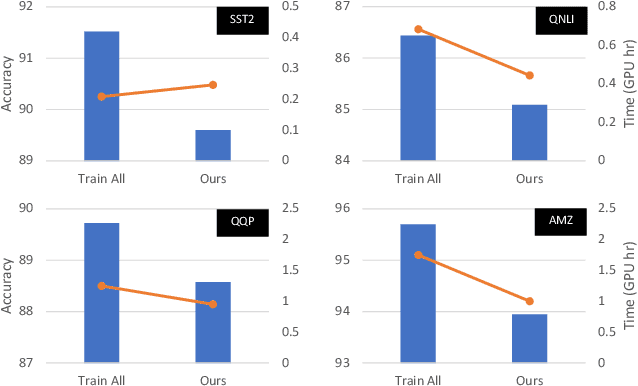
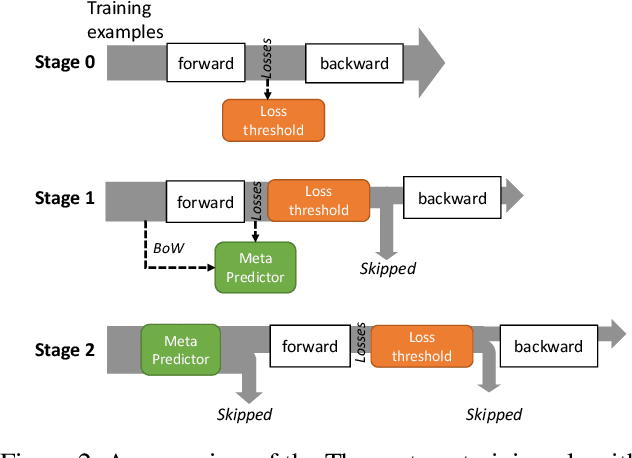

As model finetuning is central to the modern NLP, we set to maximize its efficiency. Motivated by training examples are often redundant, we design an algorithm that filters the examples in a streaming fashion. Our key techniques are two: (1) automatically determine a training loss threshold for skipping the backward propagation; and (2) maintain a meta predictor for further skipping the forward propagation. Incarnated as a three-stage process, on a diverse set of benchmarks our algorithm reduces the required training examples by up to 5$\times$ while only seeing minor degradation on average. Our method is effective even for as few as one training epoch, where each training example is encountered once. It is simple to implement and is compatible with the existing model finetuning optimizations such as layer freezing.
SuperTickets: Drawing Task-Agnostic Lottery Tickets from Supernets via Jointly Architecture Searching and Parameter Pruning
Jul 08, 2022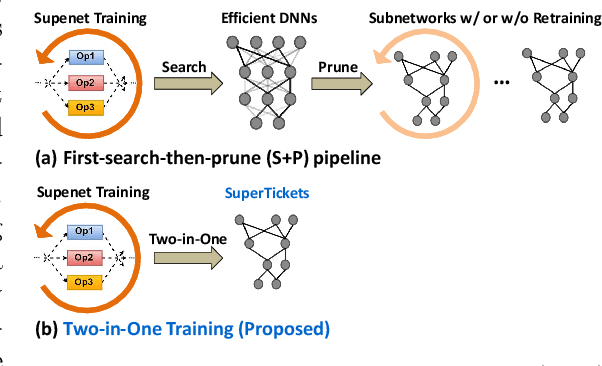

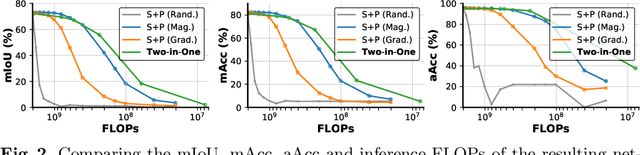

Neural architecture search (NAS) has demonstrated amazing success in searching for efficient deep neural networks (DNNs) from a given supernet. In parallel, the lottery ticket hypothesis has shown that DNNs contain small subnetworks that can be trained from scratch to achieve a comparable or higher accuracy than original DNNs. As such, it is currently a common practice to develop efficient DNNs via a pipeline of first search and then prune. Nevertheless, doing so often requires a search-train-prune-retrain process and thus prohibitive computational cost. In this paper, we discover for the first time that both efficient DNNs and their lottery subnetworks (i.e., lottery tickets) can be directly identified from a supernet, which we term as SuperTickets, via a two-in-one training scheme with jointly architecture searching and parameter pruning. Moreover, we develop a progressive and unified SuperTickets identification strategy that allows the connectivity of subnetworks to change during supernet training, achieving better accuracy and efficiency trade-offs than conventional sparse training. Finally, we evaluate whether such identified SuperTickets drawn from one task can transfer well to other tasks, validating their potential of handling multiple tasks simultaneously. Extensive experiments and ablation studies on three tasks and four benchmark datasets validate that our proposed SuperTickets achieve boosted accuracy and efficiency trade-offs than both typical NAS and pruning pipelines, regardless of having retraining or not. Codes and pretrained models are available at https://github.com/RICE-EIC/SuperTickets.
Drawing Robust Scratch Tickets: Subnetworks with Inborn Robustness Are Found within Randomly Initialized Networks
Nov 06, 2021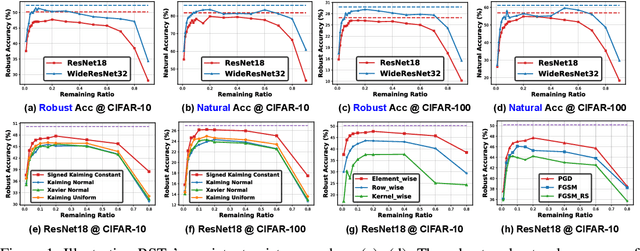
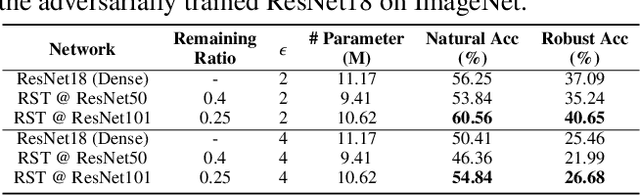
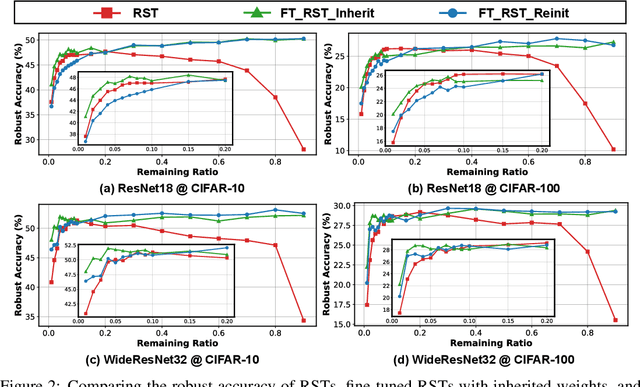
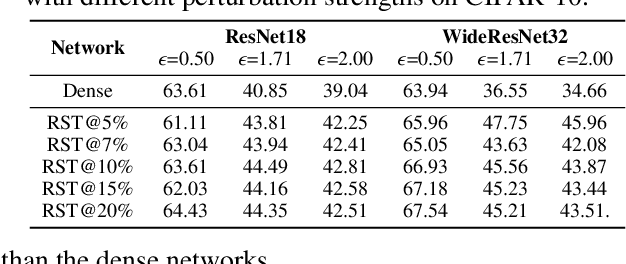
Deep Neural Networks (DNNs) are known to be vulnerable to adversarial attacks, i.e., an imperceptible perturbation to the input can mislead DNNs trained on clean images into making erroneous predictions. To tackle this, adversarial training is currently the most effective defense method, by augmenting the training set with adversarial samples generated on the fly. Interestingly, we discover for the first time that there exist subnetworks with inborn robustness, matching or surpassing the robust accuracy of the adversarially trained networks with comparable model sizes, within randomly initialized networks without any model training, indicating that adversarial training on model weights is not indispensable towards adversarial robustness. We name such subnetworks Robust Scratch Tickets (RSTs), which are also by nature efficient. Distinct from the popular lottery ticket hypothesis, neither the original dense networks nor the identified RSTs need to be trained. To validate and understand this fascinating finding, we further conduct extensive experiments to study the existence and properties of RSTs under different models, datasets, sparsity patterns, and attacks, drawing insights regarding the relationship between DNNs' robustness and their initialization/overparameterization. Furthermore, we identify the poor adversarial transferability between RSTs of different sparsity ratios drawn from the same randomly initialized dense network, and propose a Random RST Switch (R2S) technique, which randomly switches between different RSTs, as a novel defense method built on top of RSTs. We believe our findings about RSTs have opened up a new perspective to study model robustness and extend the lottery ticket hypothesis.
Semi-supervised Domain Adaptation for Semantic Segmentation
Oct 20, 2021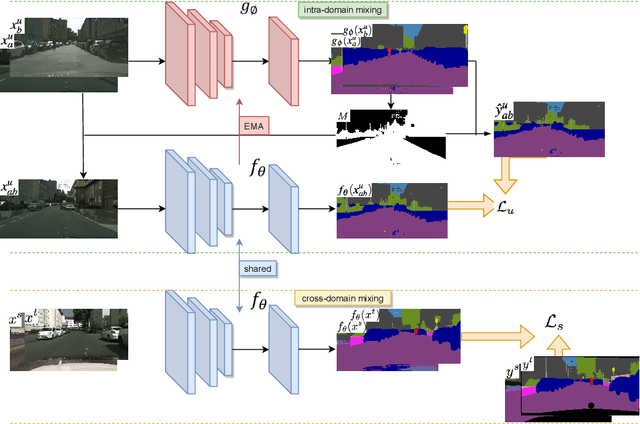
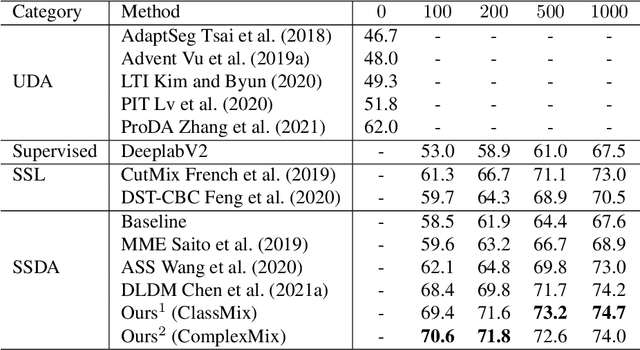

Deep learning approaches for semantic segmentation rely primarily on supervised learning approaches and require substantial efforts in producing pixel-level annotations. Further, such approaches may perform poorly when applied to unseen image domains. To cope with these limitations, both unsupervised domain adaptation (UDA) with full source supervision but without target supervision and semi-supervised learning (SSL) with partial supervision have been proposed. While such methods are effective at aligning different feature distributions, there is still a need to efficiently exploit unlabeled data to address the performance gap with respect to fully-supervised methods. In this paper we address semi-supervised domain adaptation (SSDA) for semantic segmentation, where a large amount of labeled source data as well as a small amount of labeled target data are available. We propose a novel and effective two-step semi-supervised dual-domain adaptation (SSDDA) approach to address both cross- and intra-domain gaps in semantic segmentation. The proposed framework is comprised of two mixing modules. First, we conduct a cross-domain adaptation via an image-level mixing strategy, which learns to align the distribution shift of features between the source data and target data. Second, intra-domain adaptation is achieved using a separate student-teacher network which is built to generate category-level data augmentation by mixing unlabeled target data in a way that respects predicted object boundaries. We demonstrate that the proposed approach outperforms state-of-the-art methods on two common synthetic-to-real semantic segmentation benchmarks. An extensive ablation study is provided to further validate the effectiveness of our approach.
"BNN - BN = ?": Training Binary Neural Networks without Batch Normalization
Apr 16, 2021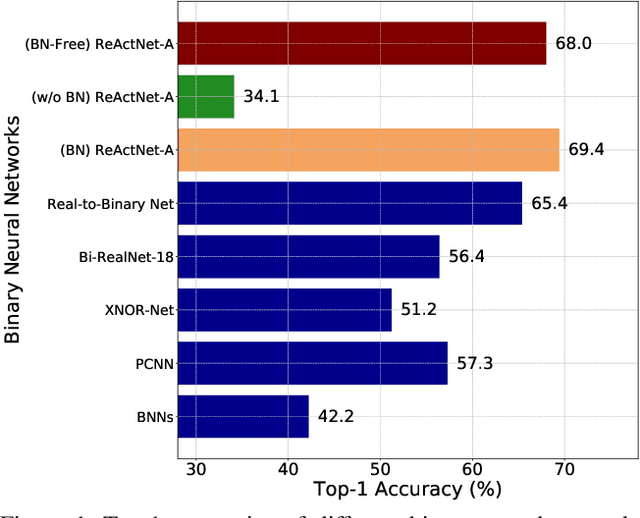

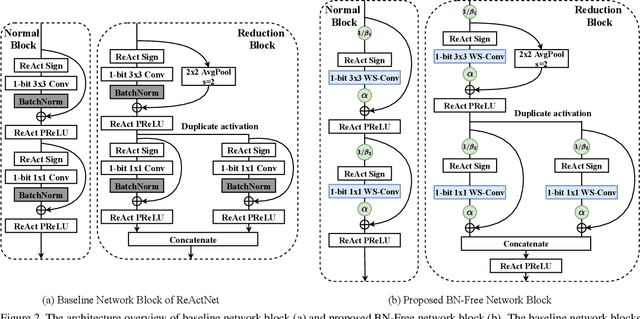

Batch normalization (BN) is a key facilitator and considered essential for state-of-the-art binary neural networks (BNN). However, the BN layer is costly to calculate and is typically implemented with non-binary parameters, leaving a hurdle for the efficient implementation of BNN training. It also introduces undesirable dependence between samples within each batch. Inspired by the latest advance on Batch Normalization Free (BN-Free) training, we extend their framework to training BNNs, and for the first time demonstrate that BNs can be completed removed from BNN training and inference regimes. By plugging in and customizing techniques including adaptive gradient clipping, scale weight standardization, and specialized bottleneck block, a BN-free BNN is capable of maintaining competitive accuracy compared to its BN-based counterpart. Extensive experiments validate the effectiveness of our proposal across diverse BNN backbones and datasets. For example, after removing BNs from the state-of-the-art ReActNets, it can still be trained with our proposed methodology to achieve 92.08%, 68.34%, and 68.0% accuracy on CIFAR-10, CIFAR-100, and ImageNet respectively, with marginal performance drop (0.23%~0.44% on CIFAR and 1.40% on ImageNet). Codes and pre-trained models are available at: https://github.com/VITA-Group/BNN_NoBN.
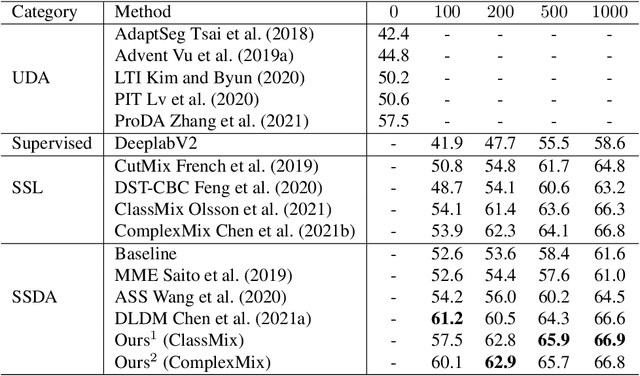
Mask-based Data Augmentation for Semi-supervised Semantic Segmentation
Jan 25, 2021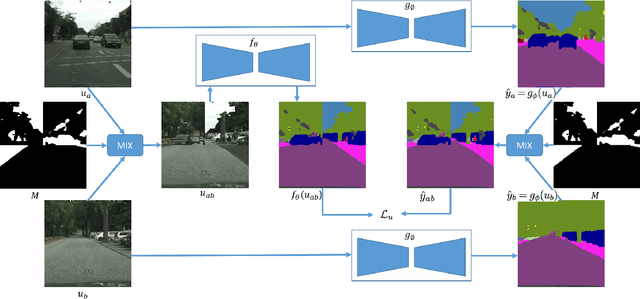
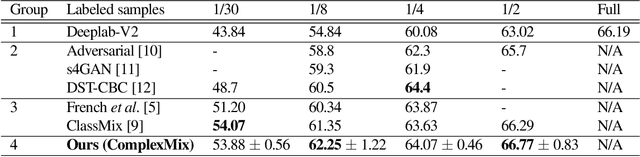
Semantic segmentation using convolutional neural networks (CNN) is a crucial component in image analysis. Training a CNN to perform semantic segmentation requires a large amount of labeled data, where the production of such labeled data is both costly and labor intensive. Semi-supervised learning algorithms address this issue by utilizing unlabeled data and so reduce the amount of labeled data needed for training. In particular, data augmentation techniques such as CutMix and ClassMix generate additional training data from existing labeled data. In this paper we propose a new approach for data augmentation, termed ComplexMix, which incorporates aspects of CutMix and ClassMix with improved performance. The proposed approach has the ability to control the complexity of the augmented data while attempting to be semantically-correct and address the tradeoff between complexity and correctness. The proposed ComplexMix approach is evaluated on a standard dataset for semantic segmentation and compared to other state-of-the-art techniques. Experimental results show that our method yields improvement over state-of-the-art methods on standard datasets for semantic image segmentation.
Domain Adaptation on Semantic Segmentation for Aerial Images
Dec 11, 2020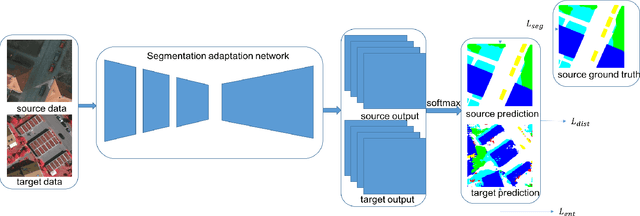
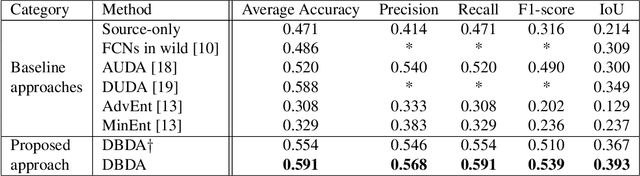

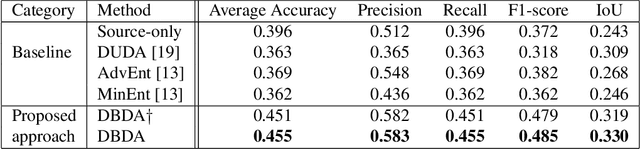
Semantic segmentation has achieved significant advances in recent years. While deep neural networks perform semantic segmentation well, their success rely on pixel level supervision which is expensive and time-consuming. Further, training using data from one domain may not generalize well to data from a new domain due to a domain gap between data distributions in the different domains. This domain gap is particularly evident in aerial images where visual appearance depends on the type of environment imaged, season, weather, and time of day when the environment is imaged. Subsequently, this distribution gap leads to severe accuracy loss when using a pretrained segmentation model to analyze new data with different characteristics. In this paper, we propose a novel unsupervised domain adaptation framework to address domain shift in the context of aerial semantic image segmentation. To this end, we solve the problem of domain shift by learn the soft label distribution difference between the source and target domains. Further, we also apply entropy minimization on the target domain to produce high-confident prediction rather than using high-confident prediction by pseudo-labeling. We demonstrate the effectiveness of our domain adaptation framework using the challenge image segmentation dataset of ISPRS, and show improvement over state-of-the-art methods in terms of various metrics.