 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Model Finetuning for Text Classification via Data Filtering
Jul 28, 2022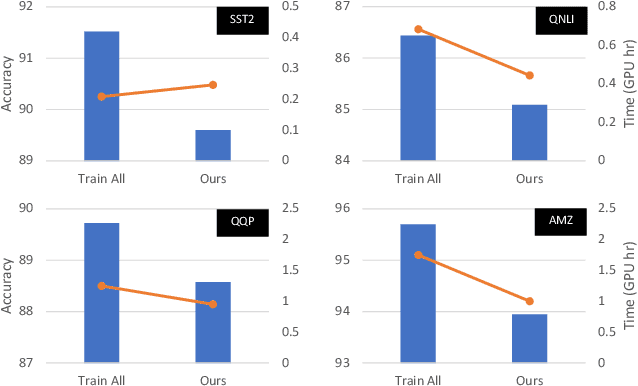
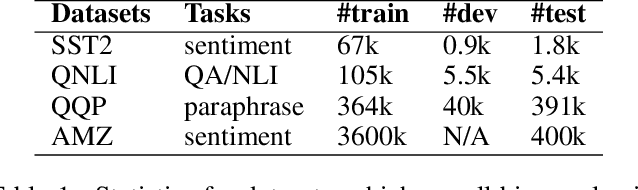
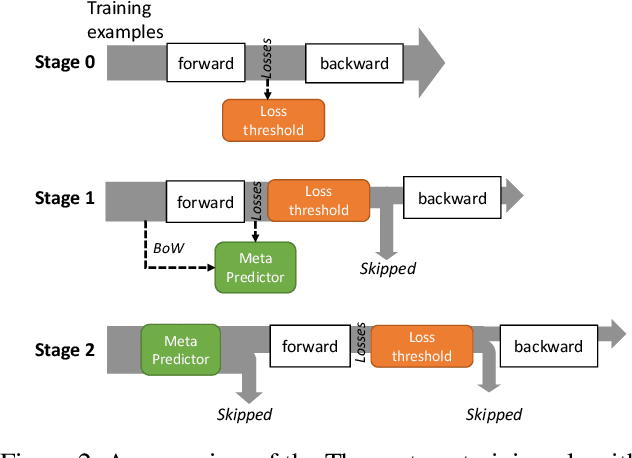

As model finetuning is central to the modern NLP, we set to maximize its efficiency. Motivated by training examples are often redundant, we design an algorithm that filters the examples in a streaming fashion. Our key techniques are two: (1) automatically determine a training loss threshold for skipping the backward propagation; and (2) maintain a meta predictor for further skipping the forward propagation. Incarnated as a three-stage process, on a diverse set of benchmarks our algorithm reduces the required training examples by up to 5$\times$ while only seeing minor degradation on average. Our method is effective even for as few as one training epoch, where each training example is encountered once. It is simple to implement and is compatible with the existing model finetuning optimizations such as layer freezing.