 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Mixture-of-Experts LLM Inference with Apple Silicon NPUs
Apr 20, 2026Apple Neural Engine (ANE) is a dedicated neural processing unit (NPU) present in every Apple Silicon chip. Mixture-of-Experts (MoE) LLMs improve inference efficiency via sparse activation but are challenging for NPUs in three ways: expert routing is unpredictable and introduces dynamic tensor shapes that conflict with the shape-specific constraints of NPUs; several irregular operators, e.g., top-k, scatter/gather, etc., are not NPU-friendly; and launching many small expert kernels incurs substantial dispatch and synchronization overhead. NPUs are designed to offload AI compute from CPU and GPU; our goal is to enable such offloading for MoE inference, particularly during prefill, where long-context workloads consume substantial system resources. This paper presents NPUMoE, a runtime inference engine that accelerates MoE execution on Apple Silicon by offloading dense, static computation to NPU, while preserving a CPU/GPU fallback path for dynamic operations. NPUMoE uses offline calibration to estimate expert capacity and popularity that drives three key techniques: (1) Static tiers for expert capacity to address dynamic expert routing (2) Grouped expert execution to mitigate NPU concurrency limits (3) Load-aware expert compute graph residency to reduce CPU-NPU synchronization overhead. Experiments on Apple M-series devices using three representative MoE LLMs and four long-context workloads show that NPUMoE consistently outperforms baselines, reducing latency by 1.32x-5.55x, improving energy efficiency by 1.81x-7.37x, and reducing CPU-cycle usage by 1.78x-5.54x through effective NPU offloading.
Efficient Whisper on Streaming Speech
Dec 15, 2024



Speech foundation models, exemplified by OpenAI's Whisper, have emerged as leaders in speech understanding thanks to their exceptional accuracy and adaptability. However, their usage largely focuses on processing pre-recorded audio, with the efficient handling of streaming speech still in its infancy. Several core challenges underlie this limitation: (1) These models are trained for long, fixed-length audio inputs (typically 30 seconds). (2) Encoding such inputs involves processing up to 1,500 tokens through numerous transformer layers. (3) Generating outputs requires an irregular and computationally heavy beam search. Consequently, streaming speech processing on edge devices with constrained resources is more demanding than many other AI tasks, including text generation. To address these challenges, we introduce Whisper-T, an innovative framework combining both model and system-level optimizations: (1) Hush words, short learnable audio segments appended to inputs, prevent over-processing and reduce hallucinations in the model. (2) Beam pruning aligns streaming audio buffers over time, leveraging intermediate decoding results to significantly speed up the process. (3) CPU/GPU pipelining dynamically distributes resources between encoding and decoding stages, optimizing performance by adapting to variations in audio input, model characteristics, and hardware. We evaluate Whisper-T on ARM-based platforms with 4-12 CPU cores and 10-30 GPU cores, demonstrating latency reductions of 1.6x-4.7x, achieving per-word delays as low as 0.5 seconds with minimal accuracy loss. Additionally, on a MacBook Air, Whisper-T maintains approximately 1-second latency per word while consuming just 7 Watts of total system power.
Lightweight Protection for Privacy in Offloaded Speech Understanding
Jan 22, 2024Speech is a common input method for mobile embedded devices, but cloud-based speech recognition systems pose privacy risks. Disentanglement-based encoders, designed to safeguard user privacy by filtering sensitive information from speech signals, unfortunately require substantial memory and computational resources, which limits their use in less powerful devices. To overcome this, we introduce a novel system, XXX, optimized for such devices. XXX is built on the insight that speech understanding primarily relies on understanding the entire utterance's long-term dependencies, while privacy concerns are often linked to short-term details. Therefore, XXX focuses on selectively masking these short-term elements, preserving the quality of long-term speech understanding. The core of XXX is an innovative differential mask generator, grounded in interpretable learning, which fine-tunes the masking process. We tested XXX on the STM32H7 microcontroller, assessing its performance in various potential attack scenarios. The results show that XXX maintains speech understanding accuracy and privacy at levels comparable to existing encoders, but with a significant improvement in efficiency, achieving up to 53.3$\times$ faster processing and a 134.1$\times$ smaller memory footprint.
Efficient Deep Speech Understanding at the Edge
Dec 04, 2023
In contemporary speech understanding (SU), a sophisticated pipeline is employed, encompassing the ingestion of streaming voice input. The pipeline executes beam search iteratively, invoking a deep neural network to generate tentative outputs (referred to as hypotheses) in an autoregressive manner. Periodically, the pipeline assesses attention and Connectionist Temporal Classification (CTC) scores. This paper aims to enhance SU performance on edge devices with limited resources. Adopting a hybrid strategy, our approach focuses on accelerating on-device execution and offloading inputs surpassing the device's capacity. While this approach is established, we tackle SU's distinctive challenges through innovative techniques: (1) Late Contextualization: This involves the parallel execution of a model's attentive encoder during input ingestion. (2) Pilot Inference: Addressing temporal load imbalances in the SU pipeline, this technique aims to mitigate them effectively. (3) Autoregression Offramps: Decisions regarding offloading are made solely based on hypotheses, presenting a novel approach. These techniques are designed to seamlessly integrate with existing speech models, pipelines, and frameworks, offering flexibility for independent or combined application. Collectively, they form a hybrid solution for edge SU. Our prototype, named XYZ, has undergone testing on Arm platforms featuring 6 to 8 cores, demonstrating state-of-the-art accuracy. Notably, it achieves a 2x reduction in end-to-end latency and a corresponding 2x decrease in offloading requirements.
Leveraging cache to enable SLU on tiny devices
Nov 30, 2023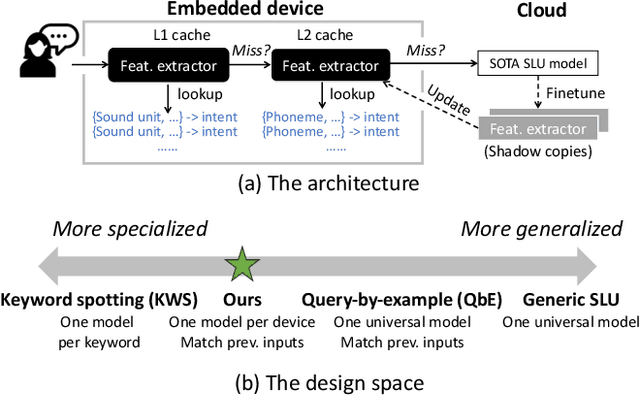
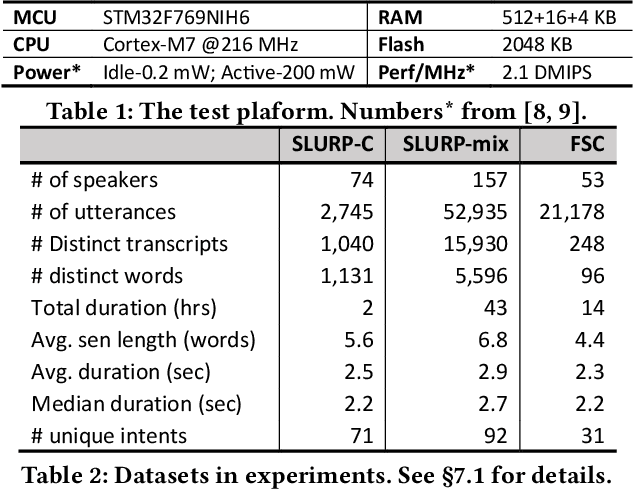
This paper addresses spoken language understanding (SLU) on microcontroller-like embedded devices, integrating on-device execution with cloud offloading in a novel fashion. We exploit temporal locality in a device's speech inputs and accordingly reuse recent SLU inferences. Our idea is simple: let the device match new inputs against cached results, and only offload unmatched inputs to the cloud for full inference. Realization of this idea, however, is non-trivial: the device needs to compare acoustic features in a robust, low-cost way. To this end, we present XYZ, a speech cache for tiny devices. It matches speech inputs at two levels of representations: first by clustered sequences of raw sound units, then as sequences of phonemes. Working in tandem, the two representations offer complementary cost/accuracy tradeoffs. To further boost accuracy, our cache is learning: with the mismatched and then offloaded inputs, it continuously finetunes the device's feature extractors (with the assistance of the cloud). We implement XYZ on an off-the-shelf STM32 microcontroller. The resultant implementation has a small memory footprint of 2MB. Evaluated on challenging speech benchmarks, our system resolves 45%--90% of inputs on device, reducing the average latency by up to 80% compared to offloading to popular cloud speech services. Our benefit is pronounced even in adversarial settings -- noisy environments, cold cache, or one device shared by a number of users.
Secure and Effective Data Appraisal for Machine Learning
Oct 05, 2023



Essential for an unfettered data market is the ability to discreetly select and evaluate training data before finalizing a transaction between the data owner and model owner. To safeguard the privacy of both data and model, this process involves scrutinizing the target model through Multi-Party Computation (MPC). While prior research has posited that the MPC-based evaluation of Transformer models is excessively resource-intensive, this paper introduces an innovative approach that renders data selection practical. The contributions of this study encompass three pivotal elements: (1) a groundbreaking pipeline for confidential data selection using MPC, (2) replicating intricate high-dimensional operations with simplified low-dimensional MLPs trained on a limited subset of pertinent data, and (3) implementing MPC in a concurrent, multi-phase manner. The proposed method is assessed across an array of Transformer models and NLP/CV benchmarks. In comparison to the direct MPC-based evaluation of the target model, our approach substantially reduces the time required, from thousands of hours to mere tens of hours, with only a nominal 0.20% dip in accuracy when training with the selected data.
Federated NLP in Few-shot Scenarios
Dec 12, 2022Natural language processing (NLP) sees rich mobile applications. To support various language understanding tasks, a foundation NLP model is often fine-tuned in a federated, privacy-preserving setting (FL). This process currently relies on at least hundreds of thousands of labeled training samples from mobile clients; yet mobile users often lack willingness or knowledge to label their data. Such an inadequacy of data labels is known as a few-shot scenario; it becomes the key blocker for mobile NLP applications. For the first time, this work investigates federated NLP in the few-shot scenario (FedFSL). By retrofitting algorithmic advances of pseudo labeling and prompt learning, we first establish a training pipeline that delivers competitive accuracy when only 0.05% (fewer than 100) of the training data is labeled and the remaining is unlabeled. To instantiate the workflow, we further present a system FFNLP, addressing the high execution cost with novel designs. (1) Curriculum pacing, which injects pseudo labels to the training workflow at a rate commensurate to the learning progress; (2) Representational diversity, a mechanism for selecting the most learnable data, only for which pseudo labels will be generated; (3) Co-planning of a model's training depth and layer capacity. Together, these designs reduce the training delay, client energy, and network traffic by up to 46.0$\times$, 41.2$\times$ and 3000.0$\times$, respectively. Through algorithm/system co-design, FFNLP demonstrates that FL can apply to challenging settings where most training samples are unlabeled.
AUG-FedPrompt: Practical Few-shot Federated NLP with Data-augmented Prompts
Dec 01, 2022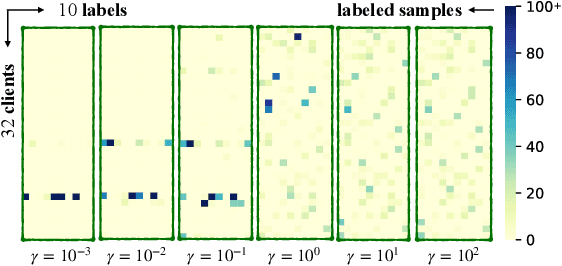

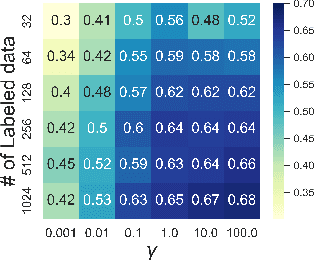

Transformer-based pre-trained models have become the de-facto solution for NLP tasks. Fine-tuning such pre-trained models for downstream tasks often requires tremendous amount of data that is both private and labeled. However, in reality: 1) such private data cannot be collected and is distributed across mobile devices, and 2) well-curated labeled data is scarce. To tackle those issues, we first define a data generator for federated few-shot learning tasks, which encompasses the quantity and distribution of scarce labeled data in a realistic setting. Then we propose AUG-FedPrompt, a prompt-based federated learning algorithm that carefully annotates abundant unlabeled data for data augmentation. AUG-FedPrompt can perform on par with full-set fine-tuning with very few initial labeled data.
Efficient Model Finetuning for Text Classification via Data Filtering
Jul 28, 2022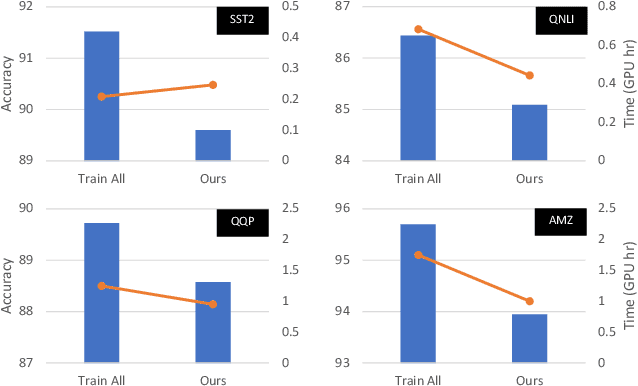
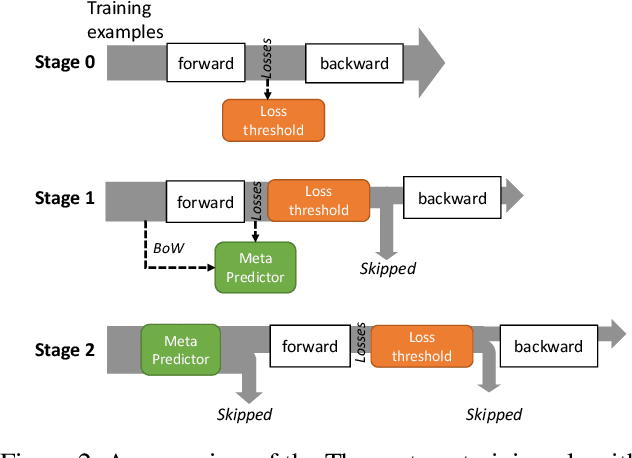

As model finetuning is central to the modern NLP, we set to maximize its efficiency. Motivated by training examples are often redundant, we design an algorithm that filters the examples in a streaming fashion. Our key techniques are two: (1) automatically determine a training loss threshold for skipping the backward propagation; and (2) maintain a meta predictor for further skipping the forward propagation. Incarnated as a three-stage process, on a diverse set of benchmarks our algorithm reduces the required training examples by up to 5$\times$ while only seeing minor degradation on average. Our method is effective even for as few as one training epoch, where each training example is encountered once. It is simple to implement and is compatible with the existing model finetuning optimizations such as layer freezing.
Efficient NLP Inference at the Edge via Elastic Pipelining
Jul 12, 2022
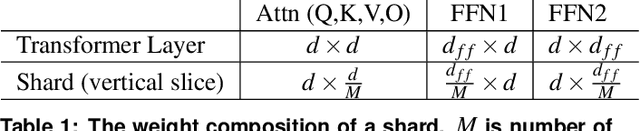
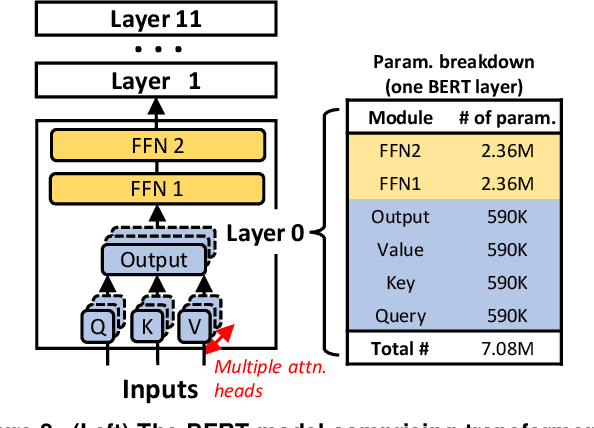

Natural Language Processing (NLP) inference is seeing increasing adoption by mobile applications, where on-device inference is desirable for crucially preserving user data privacy and avoiding network roundtrips. Yet, the unprecedented size of an NLP model stresses both latency and memory, the two key resources of a mobile device. To meet a target latency, holding the whole model in memory launches execution as soon as possible but increases one app's memory footprints by several times, limiting its benefits to only a few inferences before being recycled by mobile memory management. On the other hand, loading the model from storage on demand incurs a few seconds long IO, far exceeding the delay range satisfying to a user; pipelining layerwise model loading and execution does not hide IO either, due to the large skewness between IO and computation delays. To this end, we propose WRX. Built on the key idea of maximizing IO/compute resource utilization on the most important parts of a model, WRX reconciles the latency/memory tension via two novel techniques. First, model sharding. WRX manages model parameters as independently tunable shards and profiles their importance to accuracy. Second, elastic pipeline planning with a preload buffer. WRX instantiates an IO/computation pipeline and uses a small buffer for preload shards to bootstrap execution without stalling in early stages; it judiciously selects, tunes, and assembles shards per their importance for resource-elastic execution, which maximizes inference accuracy. Atop two commodity SoCs, we build WRX and evaluate it against a wide range of NLP tasks, under a practical range of target latencies, and on both CPU and GPU. We demonstrate that, WRX delivers high accuracies with 1--2 orders of magnitude lower memory, outperforming competitive baselines.