 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaMi: Geometry-Agnostic Material Identification via Cross-Modal Subtractive Disentanglement
May 29, 2026Non-contact material identification enables adaptive interaction for embodied intelligence yet faces challenges from geometry-induced variations (e.g., orientation, shape, distance) and single-modality ambiguities. In this paper, we present GaMi, a multimodal material identification system integrating mmWave and acoustic sensing to robustly operate under unconstrained geometric conditions. By leveraging the insight of shared geometric consistency between co-located bimodal sensors, GaMi employs an intra-sample cross-modal subtractive disentanglement framework. By semantically aligning modalities and subtracting the shared geometric context, it isolates intrinsic material features. Furthermore, GaMi incorporates inter-sample contrastive learning to correct the residual interference caused by cross-modal misalignment. Additionally, a pairing-based adaptation strategy between two modalities enables few-shot generalization across devices. Extensive evaluations on 20 materials show that GaMi achieves 95.2% accuracy, outperforming single-modality baselines across unseen geometric conditions.
The CAP Principle for LLM Serving
May 18, 2024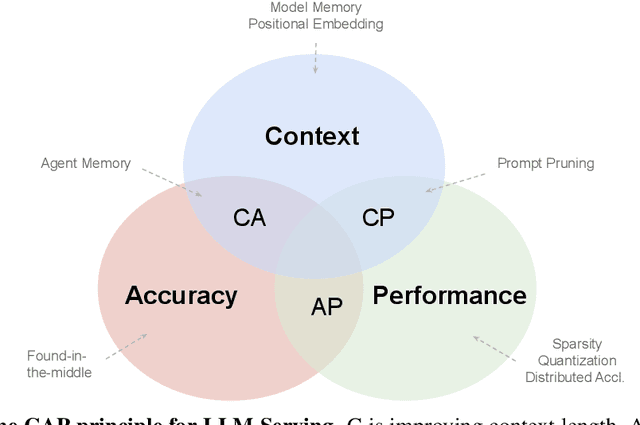

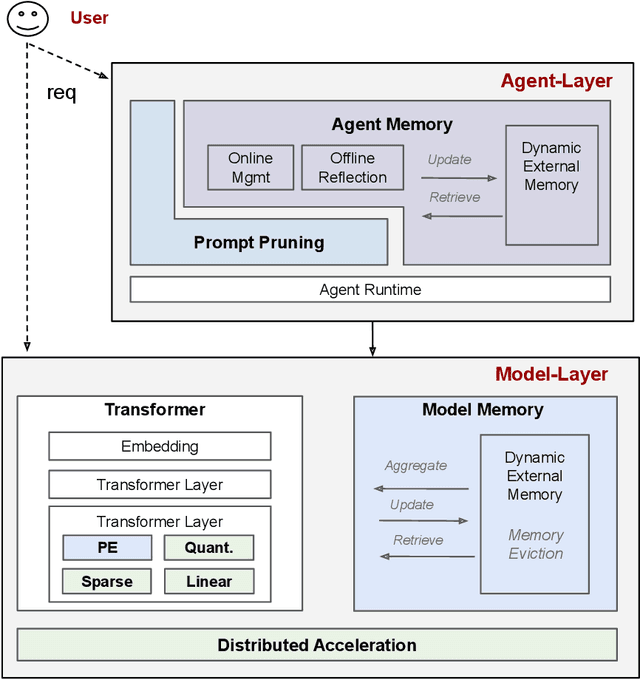
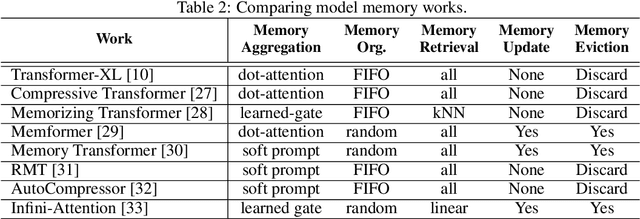
We survey the large language model (LLM) serving area to understand the intricate dynamics between cost-efficiency and accuracy, which is magnified by the growing need for longer contextual understanding when deploying models at a massive scale. Our findings reveal that works in this space optimize along three distinct but conflicting goals: improving serving context length (C), improving serving accuracy (A), and improving serving performance (P). Drawing inspiration from the CAP theorem in databases, we propose a CAP principle for LLM serving, which suggests that any optimization can improve at most two of these three goals simultaneously. Our survey categorizes existing works within this framework. We find the definition and continuity of user-perceived measurement metrics are crucial in determining whether a goal has been met, akin to prior CAP databases in the wild. We recognize the CAP principle for LLM serving as a guiding principle, rather than a formal theorem, to inform designers of the inherent and dynamic trade-offs in serving models. As serving accuracy and performance have been extensively studied, this survey focuses on works that extend serving context length and address the resulting challenges.
EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models
Aug 28, 2023
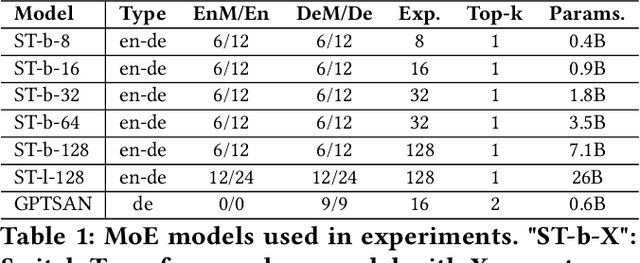
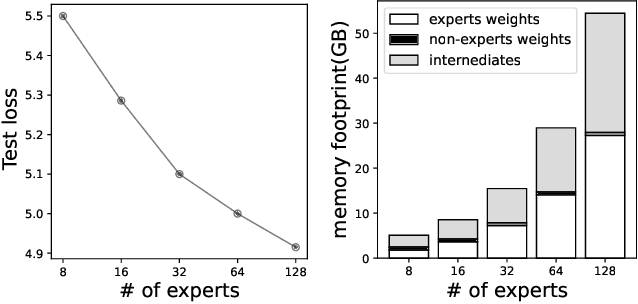

Large Language Models (LLMs) such as GPTs and LLaMa have ushered in a revolution in machine intelligence, owing to their exceptional capabilities in a wide range of machine learning tasks. However, the transition of LLMs from data centers to edge devices presents a set of challenges and opportunities. While this shift can enhance privacy and availability, it is hampered by the enormous parameter sizes of these models, leading to impractical runtime costs. In light of these considerations, we introduce EdgeMoE, the first on-device inference engine tailored for mixture-of-expert (MoE) LLMs, a popular variant of sparse LLMs that exhibit nearly constant computational complexity as their parameter size scales. EdgeMoE achieves both memory and computational efficiency by strategically partitioning the model across the storage hierarchy. Specifically, non-expert weights are stored in the device's memory, while expert weights are kept in external storage and are fetched into memory only when they are activated. This design is underpinned by a crucial insight that expert weights, though voluminous, are infrequently accessed due to sparse activation patterns. To further mitigate the overhead associated with expert I/O swapping, EdgeMoE incorporates two innovative techniques: (1) Expert-wise bitwidth adaptation: This method reduces the size of expert weights with an acceptable level of accuracy loss. (2) Expert management: It predicts the experts that will be activated in advance and preloads them into the compute-I/O pipeline, thus further optimizing the process. In empirical evaluations conducted on well-established MoE LLMs and various edge devices, EdgeMoE demonstrates substantial memory savings and performance improvements when compared to competitive baseline solutions.
Efficient NLP Inference at the Edge via Elastic Pipelining
Jul 12, 2022
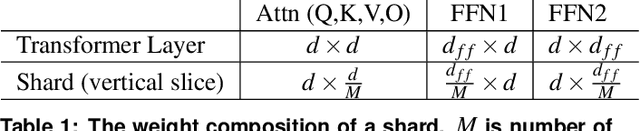
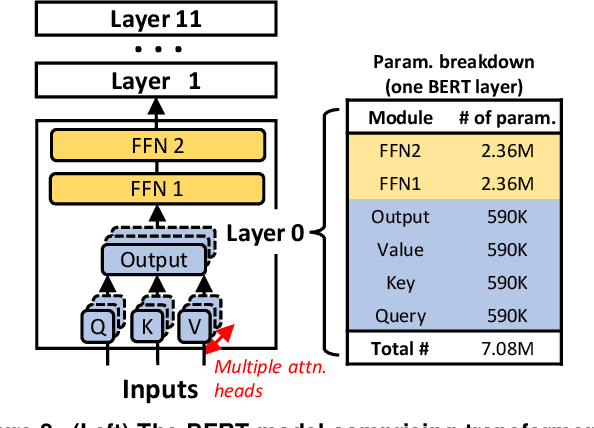

Natural Language Processing (NLP) inference is seeing increasing adoption by mobile applications, where on-device inference is desirable for crucially preserving user data privacy and avoiding network roundtrips. Yet, the unprecedented size of an NLP model stresses both latency and memory, the two key resources of a mobile device. To meet a target latency, holding the whole model in memory launches execution as soon as possible but increases one app's memory footprints by several times, limiting its benefits to only a few inferences before being recycled by mobile memory management. On the other hand, loading the model from storage on demand incurs a few seconds long IO, far exceeding the delay range satisfying to a user; pipelining layerwise model loading and execution does not hide IO either, due to the large skewness between IO and computation delays. To this end, we propose WRX. Built on the key idea of maximizing IO/compute resource utilization on the most important parts of a model, WRX reconciles the latency/memory tension via two novel techniques. First, model sharding. WRX manages model parameters as independently tunable shards and profiles their importance to accuracy. Second, elastic pipeline planning with a preload buffer. WRX instantiates an IO/computation pipeline and uses a small buffer for preload shards to bootstrap execution without stalling in early stages; it judiciously selects, tunes, and assembles shards per their importance for resource-elastic execution, which maximizes inference accuracy. Atop two commodity SoCs, we build WRX and evaluate it against a wide range of NLP tasks, under a practical range of target latencies, and on both CPU and GPU. We demonstrate that, WRX delivers high accuracies with 1--2 orders of magnitude lower memory, outperforming competitive baselines.