 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Serving of LLM Applications with Probabilistic Demand Modeling
Jun 17, 2025Applications based on Large Language Models (LLMs) contains a series of tasks to address real-world problems with boosted capability, which have dynamic demand volumes on diverse backends. Existing serving systems treat the resource demands of LLM applications as a blackbox, compromising end-to-end efficiency due to improper queuing order and backend warm up latency. We find that the resource demands of LLM applications can be modeled in a general and accurate manner with Probabilistic Demand Graph (PDGraph). We then propose Hermes, which leverages PDGraph for efficient serving of LLM applications. Confronting probabilistic demand description, Hermes applies the Gittins policy to determine the scheduling order that can minimize the average application completion time. It also uses the PDGraph model to help prewarm cold backends at proper moments. Experiments with diverse LLM applications confirm that Hermes can effectively improve the application serving efficiency, reducing the average completion time by over 70% and the P95 completion time by over 80%.
EPIC: Efficient Position-Independent Context Caching for Serving Large Language Models
Oct 20, 2024Large Language Models (LLMs) are critical for a wide range of applications, but serving them efficiently becomes increasingly challenging as inputs become more complex. Context caching improves serving performance by exploiting inter-request dependency and reusing key-value (KV) cache across requests, thus improving time-to-first-token (TTFT). However, existing prefix-based context caching requires exact token prefix matches, limiting cache reuse in few-shot learning, multi-document QA, or retrieval-augmented generation, where prefixes may vary. In this paper, we present EPIC, an LLM serving system that introduces position-independent context caching (PIC), enabling modular KV cache reuse regardless of token chunk position (or prefix). EPIC features two key designs: AttnLink, which leverages static attention sparsity to minimize recomputation for accuracy recovery, and KVSplit, a customizable chunking method that preserves semantic coherence. Our experiments demonstrate that Epic delivers up to 8x improvements in TTFT and 7x throughput over existing systems, with negligible or no accuracy loss. By addressing the limitations of traditional caching approaches, Epic enables more scalable and efficient LLM inference.
The CAP Principle for LLM Serving
May 18, 2024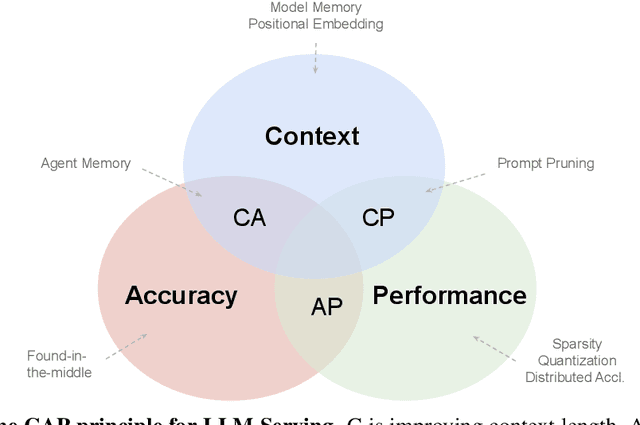

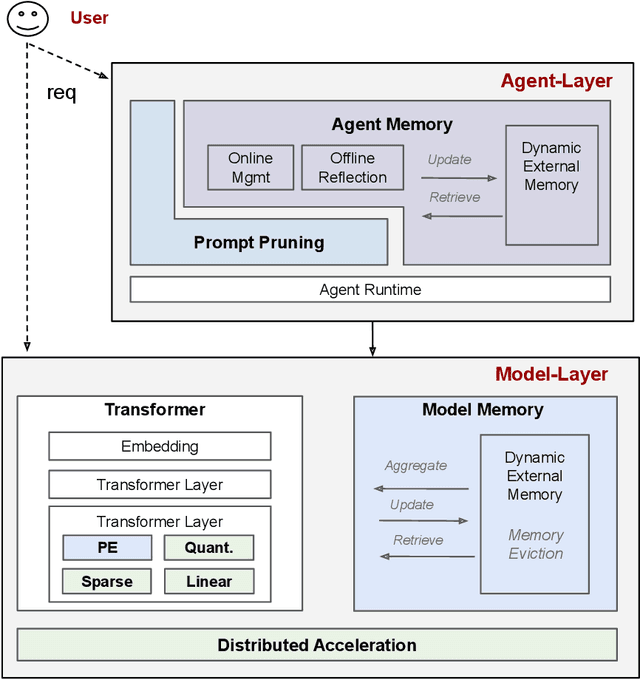
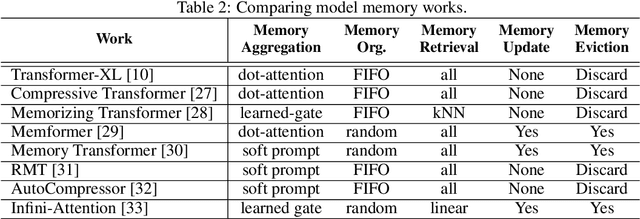
We survey the large language model (LLM) serving area to understand the intricate dynamics between cost-efficiency and accuracy, which is magnified by the growing need for longer contextual understanding when deploying models at a massive scale. Our findings reveal that works in this space optimize along three distinct but conflicting goals: improving serving context length (C), improving serving accuracy (A), and improving serving performance (P). Drawing inspiration from the CAP theorem in databases, we propose a CAP principle for LLM serving, which suggests that any optimization can improve at most two of these three goals simultaneously. Our survey categorizes existing works within this framework. We find the definition and continuity of user-perceived measurement metrics are crucial in determining whether a goal has been met, akin to prior CAP databases in the wild. We recognize the CAP principle for LLM serving as a guiding principle, rather than a formal theorem, to inform designers of the inherent and dynamic trade-offs in serving models. As serving accuracy and performance have been extensively studied, this survey focuses on works that extend serving context length and address the resulting challenges.