 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinative Learning with Ordinal and Relational Priors for Volumetric Medical Image Segmentation
Nov 14, 2025Volumetric medical image segmentation presents unique challenges due to the inherent anatomical structure and limited availability of annotations. While recent methods have shown promise by contrasting spatial relationships between slices, they rely on hard binary thresholds to define positive and negative samples, thereby discarding valuable continuous information about anatomical similarity. Moreover, these methods overlook the global directional consistency of anatomical progression, resulting in distorted feature spaces that fail to capture the canonical anatomical manifold shared across patients. To address these limitations, we propose Coordinative Ordinal-Relational Anatomical Learning (CORAL) to capture both local and global structure in volumetric images. First, CORAL employs a contrastive ranking objective to leverage continuous anatomical similarity, ensuring relational feature distances between slices are proportional to their anatomical position differences. In addition, CORAL incorporates an ordinal objective to enforce global directional consistency, aligning the learned feature distribution with the canonical anatomical progression across patients. Learning these inter-slice relationships produces anatomically informed representations that benefit the downstream segmentation task. Through this coordinative learning framework, CORAL achieves state-of-the-art performance on benchmark datasets under limited-annotation settings while learning representations with meaningful anatomical structure. Code is available at https://github.com/haoyiwang25/CORAL.
AdaptFly: Prompt-Guided Adaptation of Foundation Models for Low-Altitude UAV Networks
Nov 13, 2025Low-altitude Unmanned Aerial Vehicle (UAV) networks rely on robust semantic segmentation as a foundational enabler for distributed sensing-communication-control co-design across heterogeneous agents within the network. However, segmentation foundation models deteriorate quickly under weather, lighting, and viewpoint drift. Resource-limited UAVs cannot run gradient-based test-time adaptation, while resource-massive UAVs adapt independently, wasting shared experience. To address these challenges, we propose AdaptFly, a prompt-guided test-time adaptation framework that adjusts segmentation models without weight updates. AdaptFly features two complementary adaptation modes. For resource-limited UAVs, it employs lightweight token-prompt retrieval from a shared global memory. For resource-massive UAVs, it uses gradient-free sparse visual prompt optimization via Covariance Matrix Adaptation Evolution Strategy. An activation-statistic detector triggers adaptation, while cross-UAV knowledge pool consolidates prompt knowledge and enables fleet-wide collaboration with negligible bandwidth overhead. Extensive experiments on UAVid and VDD benchmarks, along with real-world UAV deployments under diverse weather conditions, demonstrate that AdaptFly significantly improves segmentation accuracy and robustness over static models and state-of-the-art TTA baselines. The results highlight a practical path to resilient, communication-efficient perception in the emerging low-altitude economy.
Dual-Stream Global-Local Feature Collaborative Representation Network for Scene Classification of Mining Area
Jul 27, 2025Scene classification of mining areas provides accurate foundational data for geological environment monitoring and resource development planning. This study fuses multi-source data to construct a multi-modal mine land cover scene classification dataset. A significant challenge in mining area classification lies in the complex spatial layout and multi-scale characteristics. By extracting global and local features, it becomes possible to comprehensively reflect the spatial distribution, thereby enabling a more accurate capture of the holistic characteristics of mining scenes. We propose a dual-branch fusion model utilizing collaborative representation to decompose global features into a set of key semantic vectors. This model comprises three key components:(1) Multi-scale Global Transformer Branch: It leverages adjacent large-scale features to generate global channel attention features for small-scale features, effectively capturing the multi-scale feature relationships. (2) Local Enhancement Collaborative Representation Branch: It refines the attention weights by leveraging local features and reconstructed key semantic sets, ensuring that the local context and detailed characteristics of the mining area are effectively integrated. This enhances the model's sensitivity to fine-grained spatial variations. (3) Dual-Branch Deep Feature Fusion Module: It fuses the complementary features of the two branches to incorporate more scene information. This fusion strengthens the model's ability to distinguish and classify complex mining landscapes. Finally, this study employs multi-loss computation to ensure a balanced integration of the modules. The overall accuracy of this model is 83.63%, which outperforms other comparative models. Additionally, it achieves the best performance across all other evaluation metrics.
Feature Complementation Architecture for Visual Place Recognition
Jun 14, 2025Visual place recognition (VPR) plays a crucial role in robotic localization and navigation. The key challenge lies in constructing feature representations that are robust to environmental changes. Existing methods typically adopt convolutional neural networks (CNNs) or vision Transformers (ViTs) as feature extractors. However, these architectures excel in different aspects -- CNNs are effective at capturing local details. At the same time, ViTs are better suited for modeling global context, making it difficult to leverage the strengths of both. To address this issue, we propose a local-global feature complementation network (LGCN) for VPR which integrates a parallel CNN-ViT hybrid architecture with a dynamic feature fusion module (DFM). The DFM performs dynamic feature fusion through joint modeling of spatial and channel-wise dependencies. Furthermore, to enhance the expressiveness and adaptability of the ViT branch for VPR tasks, we introduce lightweight frequency-to-spatial fusion adapters into the frozen ViT backbone. These adapters enable task-specific adaptation with controlled parameter overhead. Extensive experiments on multiple VPR benchmark datasets demonstrate that the proposed LGCN consistently outperforms existing approaches in terms of localization accuracy and robustness, validating its effectiveness and generalizability.
From Age Estimation to Age-Invariant Face Recognition: Generalized Age Feature Extraction Using Order-Enhanced Contrastive Learning
Jan 03, 2025



Generalized age feature extraction is crucial for age-related facial analysis tasks, such as age estimation and age-invariant face recognition (AIFR). Despite the recent successes of models in homogeneous-dataset experiments, their performance drops significantly in cross-dataset evaluations. Most of these models fail to extract generalized age features as they only attempt to map extracted features with training age labels directly without explicitly modeling the natural progression of aging. In this paper, we propose Order-Enhanced Contrastive Learning (OrdCon), which aims to extract generalized age features to minimize the domain gap across different datasets and scenarios. OrdCon aligns the direction vector of two features with either the natural aging direction or its reverse to effectively model the aging process. The method also leverages metric learning which is incorporated with a novel soft proxy matching loss to ensure that features are positioned around the center of each age cluster with minimum intra-class variance. We demonstrate that our proposed method achieves comparable results to state-of-the-art methods on various benchmark datasets in homogeneous-dataset evaluations for both age estimation and AIFR. In cross-dataset experiments, our method reduces the mean absolute error by about 1.38 in average for age estimation task and boosts the average accuracy for AIFR by 1.87%.
EEG Signal Denoising Using pix2pix GAN: Enhancing Neurological Data Analysis
Nov 20, 2024Electroencephalography (EEG) is essential in neuroscience and clinical practice, yet it suffers from physiological artifacts, particularly electromyography (EMG), which distort signals. We propose a deep learning model using pix2pixGAN to remove such noise and generate reliable EEG signals. Leveraging the EEGdenoiseNet dataset, we created synthetic datasets with controlled EMG noise levels for model training and testing across a signal-to-noise ratio (SNR) from -7 to 2. Our evaluation metrics included RRMSE and Pearson's CC, assessing both time and frequency domains, and compared our model with others. The pix2pixGAN model excelled, especially under high noise conditions, showing significant improvements in lower RRMSE and higher CC values. This demonstrates the model's superior accuracy and stability in purifying EEG signals, offering a robust solution for EEG analysis challenges and advancing clinical and neuroscience applications.
EPIC: Efficient Position-Independent Context Caching for Serving Large Language Models
Oct 20, 2024Large Language Models (LLMs) are critical for a wide range of applications, but serving them efficiently becomes increasingly challenging as inputs become more complex. Context caching improves serving performance by exploiting inter-request dependency and reusing key-value (KV) cache across requests, thus improving time-to-first-token (TTFT). However, existing prefix-based context caching requires exact token prefix matches, limiting cache reuse in few-shot learning, multi-document QA, or retrieval-augmented generation, where prefixes may vary. In this paper, we present EPIC, an LLM serving system that introduces position-independent context caching (PIC), enabling modular KV cache reuse regardless of token chunk position (or prefix). EPIC features two key designs: AttnLink, which leverages static attention sparsity to minimize recomputation for accuracy recovery, and KVSplit, a customizable chunking method that preserves semantic coherence. Our experiments demonstrate that Epic delivers up to 8x improvements in TTFT and 7x throughput over existing systems, with negligible or no accuracy loss. By addressing the limitations of traditional caching approaches, Epic enables more scalable and efficient LLM inference.
Cross-Age Contrastive Learning for Age-Invariant Face Recognition
Jan 02, 2024



Cross-age facial images are typically challenging and expensive to collect, making noise-free age-oriented datasets relatively small compared to widely-used large-scale facial datasets. Additionally, in real scenarios, images of the same subject at different ages are usually hard or even impossible to obtain. Both of these factors lead to a lack of supervised data, which limits the versatility of supervised methods for age-invariant face recognition, a critical task in applications such as security and biometrics. To address this issue, we propose a novel semi-supervised learning approach named Cross-Age Contrastive Learning (CACon). Thanks to the identity-preserving power of recent face synthesis models, CACon introduces a new contrastive learning method that leverages an additional synthesized sample from the input image. We also propose a new loss function in association with CACon to perform contrastive learning on a triplet of samples. We demonstrate that our method not only achieves state-of-the-art performance in homogeneous-dataset experiments on several age-invariant face recognition benchmarks but also outperforms other methods by a large margin in cross-dataset experiments.
PLM-GNN: A Webpage Classification Method based on Joint Pre-trained Language Model and Graph Neural Network
May 09, 2023



The number of web pages is growing at an exponential rate, accumulating massive amounts of data on the web. It is one of the key processes to classify webpages in web information mining. Some classical methods are based on manually building features of web pages and training classifiers based on machine learning or deep learning. However, building features manually requires specific domain knowledge and usually takes a long time to validate the validity of features. Considering webpages generated by the combination of text and HTML Document Object Model(DOM) trees, we propose a representation and classification method based on a pre-trained language model and graph neural network, named PLM-GNN. It is based on the joint encoding of text and HTML DOM trees in the web pages. It performs well on the KI-04 and SWDE datasets and on practical dataset AHS for the project of scholar's homepage crawling.
Improving Face-Based Age Estimation with Attention-Based Dynamic Patch Fusion
Dec 19, 2021


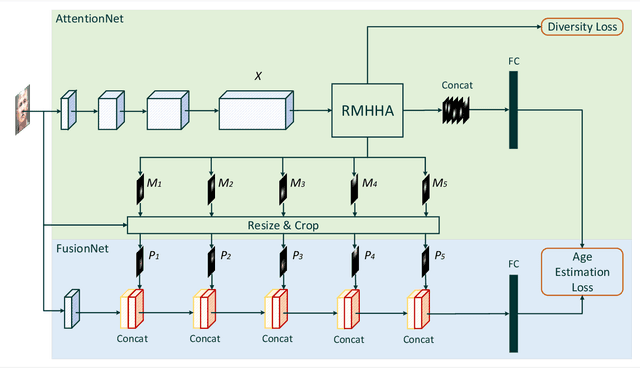
With the increasing popularity of convolutional neural networks (CNNs), recent works on face-based age estimation employ these networks as the backbone. However, state-of-the-art CNN-based methods treat each facial region equally, thus entirely ignoring the importance of some facial patches that may contain rich age-specific information. In this paper, we propose a face-based age estimation framework, called Attention-based Dynamic Patch Fusion (ADPF). In ADPF, two separate CNNs are implemented, namely the AttentionNet and the FusionNet. The AttentionNet dynamically locates and ranks age-specific patches by employing a novel Ranking-guided Multi-Head Hybrid Attention (RMHHA) mechanism. The FusionNet uses the discovered patches along with the facial image to predict the age of the subject. Since the proposed RMHHA mechanism ranks the discovered patches based on their importance, the length of the learning path of each patch in the FusionNet is proportional to the amount of information it carries (the longer, the more important). ADPF also introduces a novel diversity loss to guide the training of the AttentionNet and reduce the overlap among patches so that the diverse and important patches are discovered. Through extensive experiments, we show that our proposed framework outperforms state-of-the-art methods on several age estimation benchmark datasets.