 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelay Buffer Independent Communication over Pooled HBM for Efficient MoE Inference on Ascend
May 07, 2026Mixture-of-Experts (MoE) inference requires large-scale token exchange across devices, making dispatch and combine major bottlenecks in both prefill and decode. Beyond network transfer, routing-driven layout transformation, temporary relay, and output restoration can add substantial overhead. Existing MoE communication paths are often buffer-centric, using explicit inter-process relay and reordering buffers around collective transfer. This report presents a relay-buffer-free communication design for MoE inference acceleration on Ascend systems. The design reorganizes dispatch and combine around direct placement into destination expert windows and direct reading from remote expert windows. Built on globally pooled high-bandwidth memory and symmetric-memory allocation, it removes most intermediate relay and reordering buffers while retaining only lightweight control state, including counts, offsets, and synchronization metadata. We instantiate the design as two schedules for the main phases of MoE inference: a prefill schedule with richer planning state for throughput-oriented execution, and a compact decode schedule for latency-sensitive execution. Experiments on Ascend-based MoE workloads show reduced dispatch and combine latency in both settings. At the serving level, the implementation improves time to first token (TTFT), preserves competitive time per output token (TPOT), and enlarges the feasible scheduling space under practical latency constraints. These results indicate that, on platforms with globally addressable device memory, reducing intermediate buffering and output restoration around expert execution is an effective direction for accelerating MoE inference.
Tessera: Unlocking Heterogeneous GPUs through Kernel-Granularity Disaggregation
Apr 11, 2026Disaggregation maps parts of an AI workload to different types of GPUs, offering a path to utilize modern heterogeneous GPU clusters. However, existing solutions operate at a coarse granularity and are tightly coupled to specific model architectures, leaving much room for performance improvement. This paper presents Tessera, the first kernel disaggregation system to improve performance and cost efficiency on heterogeneous GPUs for large model inference. Our key insight is that kernels within a single application exhibit diverse resource demands, making them the most suitable granularity for aligning computation with hardware capabilities. Tessera integrates offline analysis with online adaptation by extracting precise inter-kernel dependencies from PTX to ensure correctness, overlapping communication with computation through a pipelined execution model, and employing workload-aware scheduling with lightweight runtime adaptation. Extensive evaluations across five heterogeneous GPUs and four model architectures, scaling up to 16 GPUs, show that Tessera improves serving throughput and cost efficiency by up to 2.3x and 1.6x, respectively, compared to existing disaggregation methods, while generalizing to model architectures where prior approaches do not apply. Surprisingly, a heterogeneous GPU pair under Tessera can even exceed the throughput of two homogeneous high-end GPUs at a lower cost.
Steer Model beyond Assistant: Controlling System Prompt Strength via Contrastive Decoding
Jan 10, 2026Large language models excel at complex instructions yet struggle to deviate from their helpful assistant persona, as post-training instills strong priors that resist conflicting instructions. We introduce system prompt strength, a training-free method that treats prompt adherence as a continuous control. By contrasting logits from target and default system prompts, we isolate and amplify the behavioral signal unique to the target persona by a scalar factor alpha. Across five diverse benchmarks spanning constraint satisfaction, behavioral control, pluralistic alignment, capability modulation, and stylistic control, our method yields substantial improvements: up to +8.5 strict accuracy on IFEval, +45pp refusal rate on OffTopicEval, and +13% steerability on Prompt-Steering. Our approach enables practitioners to modulate system prompt strength, providing dynamic control over model behavior without retraining.
Value of Information: A Framework for Human-Agent Communication
Jan 10, 2026Large Language Model (LLM) agents deployed for real-world tasks face a fundamental dilemma: user requests are underspecified, yet agents must decide whether to act on incomplete information or interrupt users for clarification. Existing approaches either rely on brittle confidence thresholds that require task-specific tuning, or fail to account for the varying stakes of different decisions. We introduce a decision-theoretic framework that resolves this trade-off through the Value of Information (VoI), enabling agents to dynamically weigh the expected utility gain from asking questions against the cognitive cost imposed on users. Our inference-time method requires no hyperparameter tuning and adapts seamlessly across contexts-from casual games to medical diagnosis. Experiments across four diverse domains (20 Questions, medical diagnosis, flight booking, and e-commerce) show that VoI consistently matches or exceeds the best manually-tuned baselines, achieving up to 1.36 utility points higher in high-cost settings. This work provides a parameter-free framework for adaptive agent communication that explicitly balances task risk, query ambiguity, and user effort.
Lil: Less is Less When Applying Post-Training Sparse-Attention Algorithms in Long-Decode Stage
Jan 06, 2026Large language models (LLMs) demonstrate strong capabilities across a wide range of complex tasks and are increasingly deployed at scale, placing significant demands on inference efficiency. Prior work typically decomposes inference into prefill and decode stages, with the decode stage dominating total latency. To reduce time and memory complexity in the decode stage, a line of work introduces sparse-attention algorithms. In this paper, we show, both empirically and theoretically, that sparse attention can paradoxically increase end-to-end complexity: information loss often induces significantly longer sequences, a phenomenon we term ``Less is Less'' (Lil). To mitigate the Lil problem, we propose an early-stopping algorithm that detects the threshold where information loss exceeds information gain during sparse decoding. Our early-stopping algorithm reduces token consumption by up to 90% with a marginal accuracy degradation of less than 2% across reasoning-intensive benchmarks.
Decoupling the Effect of Chain-of-Thought Reasoning: A Human Label Variation Perspective
Jan 06, 2026Reasoning-tuned LLMs utilizing long Chain-of-Thought (CoT) excel at single-answer tasks, yet their ability to model Human Label Variation--which requires capturing probabilistic ambiguity rather than resolving it--remains underexplored. We investigate this through systematic disentanglement experiments on distribution-based tasks, employing Cross-CoT experiments to isolate the effect of reasoning text from intrinsic model priors. We observe a distinct "decoupled mechanism": while CoT improves distributional alignment, final accuracy is dictated by CoT content (99% variance contribution), whereas distributional ranking is governed by model priors (over 80%). Step-wise analysis further shows that while CoT's influence on accuracy grows monotonically during the reasoning process, distributional structure is largely determined by LLM's intrinsic priors. These findings suggest that long CoT serves as a decisive LLM decision-maker for the top option but fails to function as a granular distribution calibrator for ambiguous tasks.
Confidence Estimation for LLMs in Multi-turn Interactions
Jan 05, 2026While confidence estimation is a promising direction for mitigating hallucinations in Large Language Models (LLMs), current research dominantly focuses on single-turn settings. The dynamics of model confidence in multi-turn conversations, where context accumulates and ambiguity is progressively resolved, remain largely unexplored. Reliable confidence estimation in multi-turn settings is critical for many downstream applications, such as autonomous agents and human-in-the-loop systems. This work presents the first systematic study of confidence estimation in multi-turn interactions, establishing a formal evaluation framework grounded in two key desiderata: per-turn calibration and monotonicity of confidence as more information becomes available. To facilitate this, we introduce novel metrics, including a length-normalized Expected Calibration Error (InfoECE), and a new "Hinter-Guesser" paradigm for generating controlled evaluation datasets. Our experiments reveal that widely-used confidence techniques struggle with calibration and monotonicity in multi-turn dialogues. We propose P(Sufficient), a logit-based probe that achieves comparatively better performance, although the task remains far from solved. Our work provides a foundational methodology for developing more reliable and trustworthy conversational agents.
Scaling Low-Resource MT via Synthetic Data Generation with LLMs
May 20, 2025



We investigate the potential of LLM-generated synthetic data for improving low-resource machine translation (MT). Focusing on seven diverse target languages, we construct a document-level synthetic corpus from English Europarl, and extend it via pivoting to 147 additional language pairs. Automatic and human evaluation confirm its high overall quality. We study its practical application by (i) identifying effective training regimes, (ii) comparing our data with the HPLT dataset, and (iii) testing its utility beyond English-centric MT. Finally, we introduce SynOPUS, a public repository for synthetic parallel datasets. Our findings show that LLM-generated synthetic data, even when noisy, can substantially improve MT performance for low-resource languages.
iNews: A Multimodal Dataset for Modeling Personalized Affective Responses to News
Mar 05, 2025



Current approaches to emotion detection often overlook the inherent subjectivity of affective experiences, instead relying on aggregated labels that mask individual variations in emotional responses. We introduce iNews, a novel large-scale dataset explicitly capturing subjective affective responses to news headlines. Our dataset comprises annotations from 291 demographically diverse UK participants across 2,899 multimodal Facebook news posts from major UK outlets, with an average of 5.18 annotators per sample. For each post, annotators provide multifaceted labels including valence, arousal, dominance, discrete emotions, content relevance judgments, sharing likelihood, and modality importance ratings (text, image, or both). Furthermore, we collect comprehensive annotator persona information covering demographics, personality, media trust, and consumption patterns, which explain 15.2% of annotation variance - higher than existing NLP datasets. Incorporating this information yields a 7% accuracy gain in zero-shot prediction and remains beneficial even with 32-shot. iNews will enhance research in LLM personalization, subjectivity, affective computing, and individual-level behavior simulation.
When Personalization Meets Reality: A Multi-Faceted Analysis of Personalized Preference Learning
Feb 26, 2025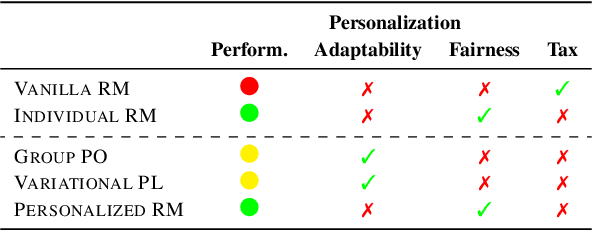
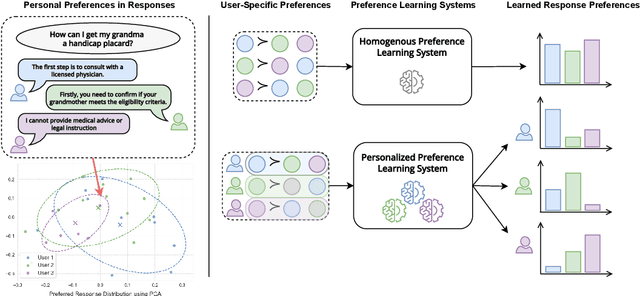

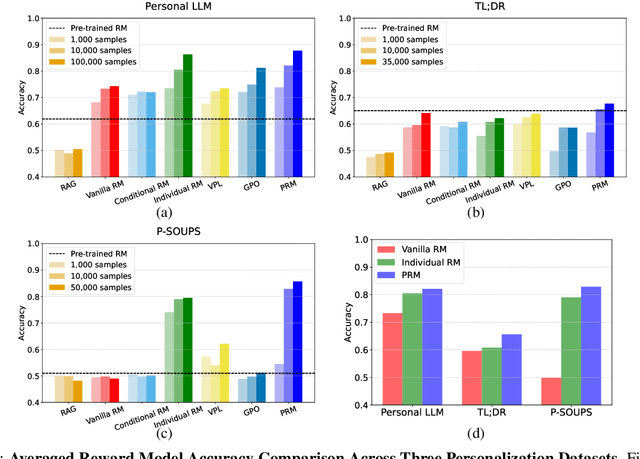
While Reinforcement Learning from Human Feedback (RLHF) is widely used to align Large Language Models (LLMs) with human preferences, it typically assumes homogeneous preferences across users, overlooking diverse human values and minority viewpoints. Although personalized preference learning addresses this by tailoring separate preferences for individual users, the field lacks standardized methods to assess its effectiveness. We present a multi-faceted evaluation framework that measures not only performance but also fairness, unintended effects, and adaptability across varying levels of preference divergence. Through extensive experiments comparing eight personalization methods across three preference datasets, we demonstrate that performance differences between methods could reach 36% when users strongly disagree, and personalization can introduce up to 20% safety misalignment. These findings highlight the critical need for holistic evaluation approaches to advance the development of more effective and inclusive preference learning systems.