 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Insight in Reasoning Models
Jan 02, 2026Do reasoning models have "Aha!" moments? Prior work suggests that models like DeepSeek-R1-Zero undergo sudden mid-trace realizations that lead to accurate outputs, implying an intrinsic capacity for self-correction. Yet, it remains unclear whether such intrinsic shifts in reasoning strategy actually improve performance. Here, we study mid-reasoning shifts and instrument training runs to detect them. Our analysis spans 1M+ reasoning traces, hundreds of training checkpoints, three reasoning domains, and multiple decoding temperatures and model architectures. We find that reasoning shifts are rare, do not become more frequent with training, and seldom improve accuracy, indicating that they do not correspond to prior perceptions of model insight. However, their effect varies with model uncertainty. Building on this finding, we show that artificially triggering extrinsic shifts under high entropy reliably improves accuracy. Our results show that mid-reasoning shifts are symptoms of unstable inference behavior rather than an intrinsic mechanism for self-correction.
Redefining Research Crowdsourcing: Incorporating Human Feedback with LLM-Powered Digital Twins
May 29, 2025Crowd work platforms like Amazon Mechanical Turk and Prolific are vital for research, yet workers' growing use of generative AI tools poses challenges. Researchers face compromised data validity as AI responses replace authentic human behavior, while workers risk diminished roles as AI automates tasks. To address this, we propose a hybrid framework using digital twins, personalized AI models that emulate workers' behaviors and preferences while keeping humans in the loop. We evaluate our system with an experiment (n=88 crowd workers) and in-depth interviews with crowd workers (n=5) and social science researchers (n=4). Our results suggest that digital twins may enhance productivity and reduce decision fatigue while maintaining response quality. Both researchers and workers emphasized the importance of transparency, ethical data use, and worker agency. By automating repetitive tasks and preserving human engagement for nuanced ones, digital twins may help balance scalability with authenticity.
Economics of Sourcing Human Data
Feb 11, 2025Progress in AI has relied on human-generated data, from annotator marketplaces to the wider Internet. However, the widespread use of large language models now threatens the quality and integrity of human-generated data on these very platforms. We argue that this issue goes beyond the immediate challenge of filtering AI-generated content--it reveals deeper flaws in how data collection systems are designed. Existing systems often prioritize speed, scale, and efficiency at the cost of intrinsic human motivation, leading to declining engagement and data quality. We propose that rethinking data collection systems to align with contributors' intrinsic motivations--rather than relying solely on external incentives--can help sustain high-quality data sourcing at scale while maintaining contributor trust and long-term participation.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Can Language Models Recognize Convincing Arguments?
Mar 31, 2024



The remarkable and ever-increasing capabilities of Large Language Models (LLMs) have raised concerns about their potential misuse for creating personalized, convincing misinformation and propaganda. To gain insights into LLMs' persuasive capabilities without directly engaging in experimentation with humans, we propose studying their performance on the related task of detecting convincing arguments. We extend a dataset by Durmus & Cardie (2018) with debates, votes, and user traits and propose tasks measuring LLMs' ability to (1) distinguish between strong and weak arguments, (2) predict stances based on beliefs and demographic characteristics, and (3) determine the appeal of an argument to an individual based on their traits. We show that LLMs perform on par with humans in these tasks and that combining predictions from different LLMs yields significant performance gains, even surpassing human performance. The data and code released with this paper contribute to the crucial ongoing effort of continuously evaluating and monitoring the rapidly evolving capabilities and potential impact of LLMs.
Prevalence and prevention of large language model use in crowd work
Oct 24, 2023

We show that the use of large language models (LLMs) is prevalent among crowd workers, and that targeted mitigation strategies can significantly reduce, but not eliminate, LLM use. On a text summarization task where workers were not directed in any way regarding their LLM use, the estimated prevalence of LLM use was around 30%, but was reduced by about half by asking workers to not use LLMs and by raising the cost of using them, e.g., by disabling copy-pasting. Secondary analyses give further insight into LLM use and its prevention: LLM use yields high-quality but homogeneous responses, which may harm research concerned with human (rather than model) behavior and degrade future models trained with crowdsourced data. At the same time, preventing LLM use may be at odds with obtaining high-quality responses; e.g., when requesting workers not to use LLMs, summaries contained fewer keywords carrying essential information. Our estimates will likely change as LLMs increase in popularity or capabilities, and as norms around their usage change. Yet, understanding the co-evolution of LLM-based tools and users is key to maintaining the validity of research done using crowdsourcing, and we provide a critical baseline before widespread adoption ensues.
Stranger Danger! Cross-Community Interactions with Fringe Users Increase the Growth of Fringe Communities on Reddit
Oct 18, 2023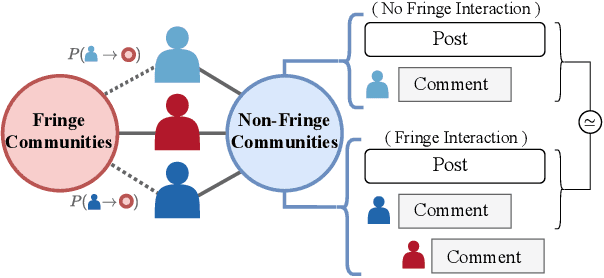
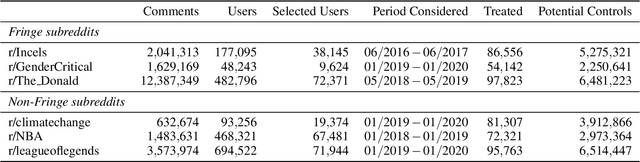
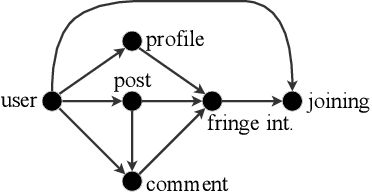
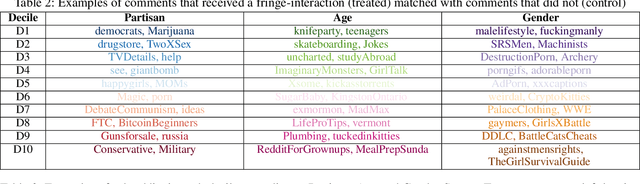
Fringe communities promoting conspiracy theories and extremist ideologies have thrived on mainstream platforms, raising questions about the mechanisms driving their growth. Here, we hypothesize and study a possible mechanism: new members may be recruited through fringe-interactions: the exchange of comments between members and non-members of fringe communities. We apply text-based causal inference techniques to study the impact of fringe-interactions on the growth of three prominent fringe communities on Reddit: r/Incel, r/GenderCritical, and r/The_Donald. Our results indicate that fringe-interactions attract new members to fringe communities. Users who receive these interactions are up to 4.2 percentage points (pp) more likely to join fringe communities than similar, matched users who do not. This effect is influenced by 1) the characteristics of communities where the interaction happens (e.g., left vs. right-leaning communities) and 2) the language used in the interactions. Interactions using toxic language have a 5pp higher chance of attracting newcomers to fringe communities than non-toxic interactions. We find no effect when repeating this analysis by replacing fringe (r/Incel, r/GenderCritical, and r/The_Donald) with non-fringe communities (r/climatechange, r/NBA, r/leagueoflegends), suggesting this growth mechanism is specific to fringe communities. Overall, our findings suggest that curtailing fringe-interactions may reduce the growth of fringe communities on mainstream platforms.
ACTI at EVALITA 2023: Overview of the Conspiracy Theory Identification Task
Jul 12, 2023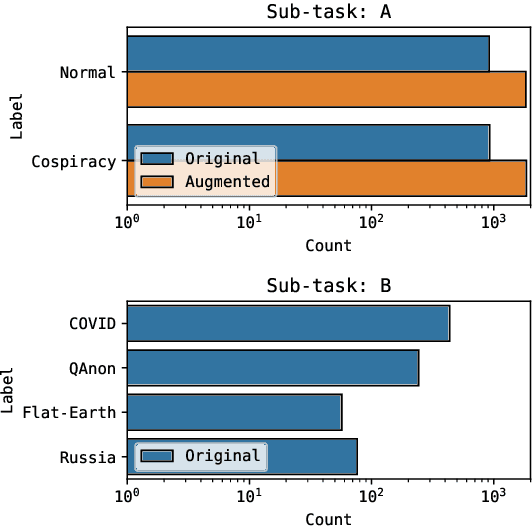
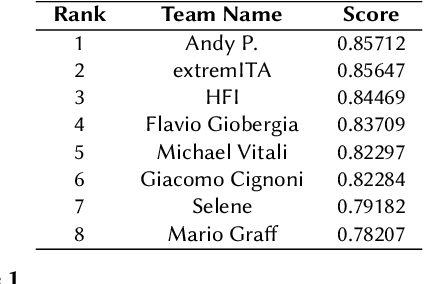
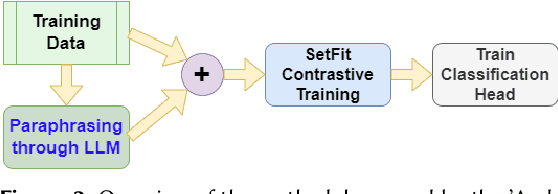
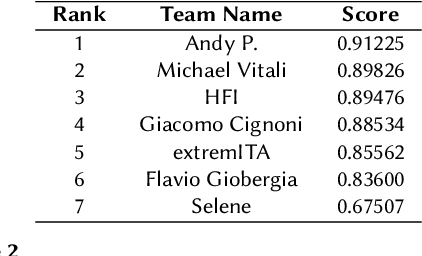
Conspiracy Theory Identication task is a new shared task proposed for the first time at the Evalita 2023. The ACTI challenge, based exclusively on comments published on conspiratorial channels of telegram, is divided into two subtasks: (i) Conspiratorial Content Classification: identifying conspiratorial content and (ii) Conspiratorial Category Classification about specific conspiracy theory classification. A total of fifteen teams participated in the task for a total of 81 submissions. We illustrate the best performing approaches were based on the utilization of large language models. We finally draw conclusions about the utilization of these models for counteracting the spreading of misinformation in online platforms.
Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks
Jun 13, 2023



Large language models (LLMs) are remarkable data annotators. They can be used to generate high-fidelity supervised training data, as well as survey and experimental data. With the widespread adoption of LLMs, human gold--standard annotations are key to understanding the capabilities of LLMs and the validity of their results. However, crowdsourcing, an important, inexpensive way to obtain human annotations, may itself be impacted by LLMs, as crowd workers have financial incentives to use LLMs to increase their productivity and income. To investigate this concern, we conducted a case study on the prevalence of LLM usage by crowd workers. We reran an abstract summarization task from the literature on Amazon Mechanical Turk and, through a combination of keystroke detection and synthetic text classification, estimate that 33-46% of crowd workers used LLMs when completing the task. Although generalization to other, less LLM-friendly tasks is unclear, our results call for platforms, researchers, and crowd workers to find new ways to ensure that human data remain human, perhaps using the methodology proposed here as a stepping stone. Code/data: https://github.com/epfl-dlab/GPTurk
Generating Faithful Synthetic Data with Large Language Models: A Case Study in Computational Social Science
May 24, 2023Large Language Models (LLMs) have democratized synthetic data generation, which in turn has the potential to simplify and broaden a wide gamut of NLP tasks. Here, we tackle a pervasive problem in synthetic data generation: its generative distribution often differs from the distribution of real-world data researchers care about (in other words, it is unfaithful). In a case study on sarcasm detection, we study three strategies to increase the faithfulness of synthetic data: grounding, filtering, and taxonomy-based generation. We evaluate these strategies using the performance of classifiers trained with generated synthetic data on real-world data. While all three strategies improve the performance of classifiers, we find that grounding works best for the task at hand. As synthetic data generation plays an ever-increasing role in NLP research, we expect this work to be a stepping stone in improving its utility. We conclude this paper with some recommendations on how to generate high(er)-fidelity synthetic data for specific tasks.