 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRA_2: Overcoming Bottlenecks in AI Research Agents
Mar 27, 2026Existing research has identified three structural performance bottlenecks in AI research agents: (1) synchronous single-GPU execution constrains sample throughput, limiting the benefit of search; (2) a generalization gap where validation-based selection causes performance to degrade over extended search horizons; and (3) the limited capability of fixed, single-turn LLM operators imposes a ceiling on search performance. We introduce AIRA$_2$, which addresses these bottlenecks through three architectural choices: an asynchronous multi-GPU worker pool that increases experiment throughput linearly; a Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal; and ReAct agents that dynamically scope their actions and debug interactively. On MLE-bench-30, AIRA$_2$ achieves a mean Percentile Rank of 71.8% at 24 hours - surpassing the previous best of 69.9% - and steadily improves to 76.0% at 72 hours. Ablation studies reveal that each component is necessary and that the "overfitting" reported in prior work was driven by evaluation noise rather than true data memorization.
AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
Interactive Evaluation of Large Language Models for Multi-Requirement Software Engineering Tasks
Aug 26, 2025Standard single-turn, static benchmarks fall short in evaluating the nuanced capabilities of Large Language Models (LLMs) on complex tasks such as software engineering. In this work, we propose a novel interactive evaluation framework that assesses LLMs on multi-requirement programming tasks through structured, feedback-driven dialogue. Each task is modeled as a requirement dependency graph, and an ``interviewer'' LLM, aware of the ground-truth solution, provides minimal, targeted hints to an ``interviewee'' model to help correct errors and fulfill target constraints. This dynamic protocol enables fine-grained diagnostic insights into model behavior, uncovering strengths and systematic weaknesses that static benchmarks fail to measure. We build on DevAI, a benchmark of 55 curated programming tasks, by adding ground-truth solutions and evaluating the relevance and utility of interviewer hints through expert annotation. Our results highlight the importance of dynamic evaluation in advancing the development of collaborative code-generating agents.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
The Era of Semantic Decoding
Mar 21, 2024


Recent work demonstrated great promise in the idea of orchestrating collaborations between LLMs, human input, and various tools to address the inherent limitations of LLMs. We propose a novel perspective called semantic decoding, which frames these collaborative processes as optimization procedures in semantic space. Specifically, we conceptualize LLMs as semantic processors that manipulate meaningful pieces of information that we call semantic tokens (known thoughts). LLMs are among a large pool of other semantic processors, including humans and tools, such as search engines or code executors. Collectively, semantic processors engage in dynamic exchanges of semantic tokens to progressively construct high-utility outputs. We refer to these orchestrated interactions among semantic processors, optimizing and searching in semantic space, as semantic decoding algorithms. This concept draws a direct parallel to the well-studied problem of syntactic decoding, which involves crafting algorithms to best exploit auto-regressive language models for extracting high-utility sequences of syntactic tokens. By focusing on the semantic level and disregarding syntactic details, we gain a fresh perspective on the engineering of AI systems, enabling us to imagine systems with much greater complexity and capabilities. In this position paper, we formalize the transition from syntactic to semantic tokens as well as the analogy between syntactic and semantic decoding. Subsequently, we explore the possibilities of optimizing within the space of semantic tokens via semantic decoding algorithms. We conclude with a list of research opportunities and questions arising from this fresh perspective. The semantic decoding perspective offers a powerful abstraction for search and optimization directly in the space of meaningful concepts, with semantic tokens as the fundamental units of a new type of computation.
Symbolic Autoencoding for Self-Supervised Sequence Learning
Feb 16, 2024Traditional language models, adept at next-token prediction in text sequences, often struggle with transduction tasks between distinct symbolic systems, particularly when parallel data is scarce. Addressing this issue, we introduce \textit{symbolic autoencoding} ($\Sigma$AE), a self-supervised framework that harnesses the power of abundant unparallel data alongside limited parallel data. $\Sigma$AE connects two generative models via a discrete bottleneck layer and is optimized end-to-end by minimizing reconstruction loss (simultaneously with supervised loss for the parallel data), such that the sequence generated by the discrete bottleneck can be read out as the transduced input sequence. We also develop gradient-based methods allowing for efficient self-supervised sequence learning despite the discreteness of the bottleneck. Our results demonstrate that $\Sigma$AE significantly enhances performance on transduction tasks, even with minimal parallel data, offering a promising solution for weakly supervised learning scenarios.
Sketch-Guided Constrained Decoding for Boosting Blackbox Large Language Models without Logit Access
Jan 18, 2024



Constrained decoding, a technique for enforcing constraints on language model outputs, offers a way to control text generation without retraining or architectural modifications. Its application is, however, typically restricted to models that give users access to next-token distributions (usually via softmax logits), which poses a limitation with blackbox large language models (LLMs). This paper introduces sketch-guided constrained decoding (SGCD), a novel approach to constrained decoding for blackbox LLMs, which operates without access to the logits of the blackbox LLM. SGCD utilizes a locally hosted auxiliary model to refine the output of an unconstrained blackbox LLM, effectively treating this initial output as a "sketch" for further elaboration. This approach is complementary to traditional logit-based techniques and enables the application of constrained decoding in settings where full model transparency is unavailable. We demonstrate the efficacy of SGCD through experiments in closed information extraction and constituency parsing, showing how it enhances the utility and flexibility of blackbox LLMs for complex NLP tasks.
Evaluating Language Model Agency through Negotiations
Jan 09, 2024


Companies, organizations, and governments increasingly exploit Language Models' (LM) remarkable capability to display agent-like behavior. As LMs are adopted to perform tasks with growing autonomy, there exists an urgent need for reliable and scalable evaluation benchmarks. Current, predominantly static LM benchmarks are ill-suited to evaluate such dynamic applications. Thus, we propose jointly evaluating LM performance and alignment through the lenses of negotiation games. We argue that this common task better reflects real-world deployment conditions while offering insights into LMs' decision-making processes. Crucially, negotiation games allow us to study multi-turn, and cross-model interactions, modulate complexity, and side-step accidental data leakage in evaluation. We report results for six publicly accessible LMs from several major providers on a variety of negotiation games, evaluating both self-play and cross-play performance. Noteworthy findings include: (i) open-source models are currently unable to complete these tasks; (ii) cooperative bargaining games prove challenging; and (iii) the most powerful models do not always "win".
A Glitch in the Matrix? Locating and Detecting Language Model Grounding with Fakepedia
Dec 04, 2023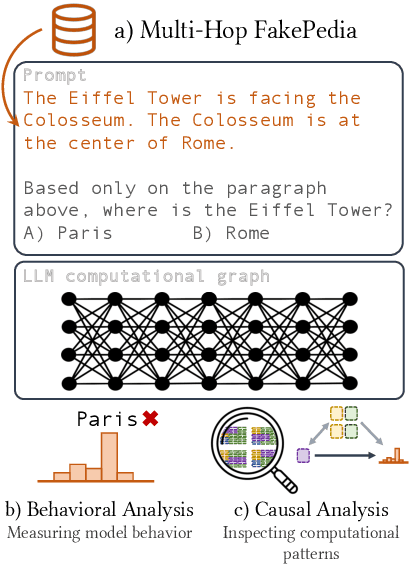
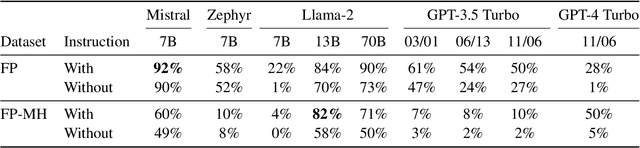
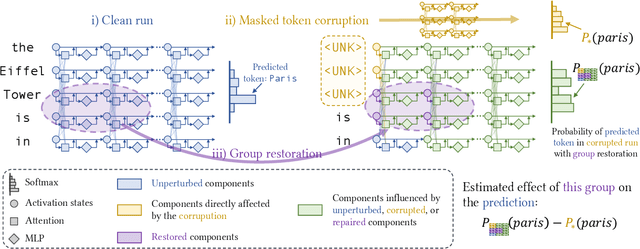
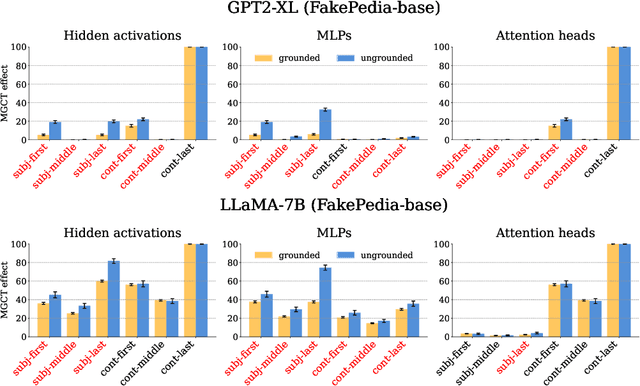
Large language models (LLMs) have demonstrated impressive capabilities in storing and recalling factual knowledge, but also in adapting to novel in-context information. Yet, the mechanisms underlying their in-context grounding remain unknown, especially in situations where in-context information contradicts factual knowledge embedded in the parameters. This is critical for retrieval-augmented generation methods, which enrich the context with up-to-date information, hoping that grounding can rectify the outdated parametric knowledge. In this study, we introduce Fakepedia, a counterfactual dataset designed to evaluate grounding abilities when the parametric knowledge clashes with the in-context information. We benchmark various LLMs with Fakepedia and discover that GPT-4-turbo has a strong preference for its parametric knowledge. Mistral-7B, on the contrary, is the model that most robustly chooses the grounded answer. Then, we conduct causal mediation analysis on LLM components when answering Fakepedia queries. We demonstrate that inspection of the computational graph alone can predict LLM grounding with 92.8% accuracy, especially because few MLPs in the Transformer can predict non-grounded behavior. Our results, together with existing findings about factual recall mechanisms, provide a coherent narrative of how grounding and factual recall mechanisms interact within LLMs.