 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm Discovery With LLMs: Evolutionary Search Meets Reinforcement Learning
Apr 08, 2025Discovering efficient algorithms for solving complex problems has been an outstanding challenge in mathematics and computer science, requiring substantial human expertise over the years. Recent advancements in evolutionary search with large language models (LLMs) have shown promise in accelerating the discovery of algorithms across various domains, particularly in mathematics and optimization. However, existing approaches treat the LLM as a static generator, missing the opportunity to update the model with the signal obtained from evolutionary exploration. In this work, we propose to augment LLM-based evolutionary search by continuously refining the search operator - the LLM - through reinforcement learning (RL) fine-tuning. Our method leverages evolutionary search as an exploration strategy to discover improved algorithms, while RL optimizes the LLM policy based on these discoveries. Our experiments on three combinatorial optimization tasks - bin packing, traveling salesman, and the flatpack problem - show that combining RL and evolutionary search improves discovery efficiency of improved algorithms, showcasing the potential of RL-enhanced evolutionary strategies to assist computer scientists and mathematicians for more efficient algorithm design.
On Provable Length and Compositional Generalization
Feb 24, 2024Length generalization -- the ability to generalize to longer sequences than ones seen during training, and compositional generalization -- the ability to generalize to token combinations not seen during training, are crucial forms of out-of-distribution generalization in sequence-to-sequence models. In this work, we take the first steps towards provable length and compositional generalization for a range of architectures, including deep sets, transformers, state space models, and simple recurrent neural nets. Depending on the architecture, we prove different degrees of representation identification, e.g., a linear or a permutation relation with ground truth representation, is necessary for length and compositional generalization.
Symbolic Autoencoding for Self-Supervised Sequence Learning
Feb 16, 2024Traditional language models, adept at next-token prediction in text sequences, often struggle with transduction tasks between distinct symbolic systems, particularly when parallel data is scarce. Addressing this issue, we introduce \textit{symbolic autoencoding} ($\Sigma$AE), a self-supervised framework that harnesses the power of abundant unparallel data alongside limited parallel data. $\Sigma$AE connects two generative models via a discrete bottleneck layer and is optimized end-to-end by minimizing reconstruction loss (simultaneously with supervised loss for the parallel data), such that the sequence generated by the discrete bottleneck can be read out as the transduced input sequence. We also develop gradient-based methods allowing for efficient self-supervised sequence learning despite the discreteness of the bottleneck. Our results demonstrate that $\Sigma$AE significantly enhances performance on transduction tasks, even with minimal parallel data, offering a promising solution for weakly supervised learning scenarios.
Object-centric architectures enable efficient causal representation learning
Oct 29, 2023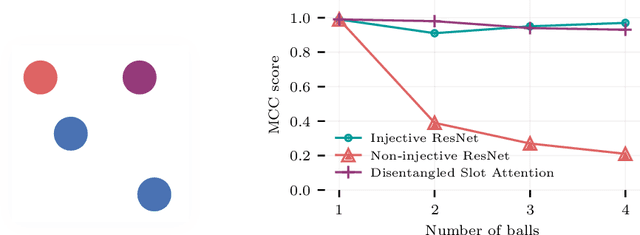
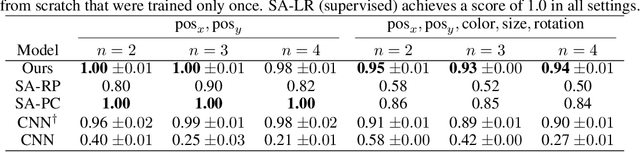


Causal representation learning has showed a variety of settings in which we can disentangle latent variables with identifiability guarantees (up to some reasonable equivalence class). Common to all of these approaches is the assumption that (1) the latent variables are represented as $d$-dimensional vectors, and (2) that the observations are the output of some injective generative function of these latent variables. While these assumptions appear benign, we show that when the observations are of multiple objects, the generative function is no longer injective and disentanglement fails in practice. We can address this failure by combining recent developments in object-centric learning and causal representation learning. By modifying the Slot Attention architecture arXiv:2006.15055, we develop an object-centric architecture that leverages weak supervision from sparse perturbations to disentangle each object's properties. This approach is more data-efficient in the sense that it requires significantly fewer perturbations than a comparable approach that encodes to a Euclidean space and we show that this approach successfully disentangles the properties of a set of objects in a series of simple image-based disentanglement experiments.
Multi-Domain Causal Representation Learning via Weak Distributional Invariances
Oct 09, 2023Causal representation learning has emerged as the center of action in causal machine learning research. In particular, multi-domain datasets present a natural opportunity for showcasing the advantages of causal representation learning over standard unsupervised representation learning. While recent works have taken crucial steps towards learning causal representations, they often lack applicability to multi-domain datasets due to over-simplifying assumptions about the data; e.g. each domain comes from a different single-node perfect intervention. In this work, we relax these assumptions and capitalize on the following observation: there often exists a subset of latents whose certain distributional properties (e.g., support, variance) remain stable across domains; this property holds when, for example, each domain comes from a multi-node imperfect intervention. Leveraging this observation, we show that autoencoders that incorporate such invariances can provably identify the stable set of latents from the rest across different settings.
Reusable Slotwise Mechanisms
Feb 21, 2023Agents that can understand and reason over the dynamics of objects can have a better capability to act robustly and generalize to novel scenarios. Such an ability, however, requires a suitable representation of the scene as well as an understanding of the mechanisms that govern the interactions of different subsets of objects. To address this problem, we propose RSM, or Reusable Slotwise Mechanisms, that jointly learns a slotwise representation of the scene and a modular architecture that dynamically chooses one mechanism among a set of reusable mechanisms to predict the next state of each slot. RSM crucially takes advantage of a \textit{Central Contextual Information (CCI)}, which lets each selected reusable mechanism access the rest of the slots through a bottleneck, effectively allowing for modeling higher order and complex interactions that might require a sparse subset of objects. We show how this model outperforms state-of-the-art methods in a variety of next-step prediction tasks ranging from grid-world environments to Atari 2600 games. Particularly, we challenge methods that model the dynamics with Graph Neural Networks (GNNs) on top of slotwise representations, and modular architectures that restrict the interactions to be only pairwise. Finally, we show that RSM is able to generalize to scenes with objects varying in number and shape, highlighting its out-of-distribution generalization capabilities. Our implementation is available online\footnote{\hyperlink{https://github.com/trangnnp/RSM}{github.com/trangnnp/RSM}}.