 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm Discovery With LLMs: Evolutionary Search Meets Reinforcement Learning
Apr 08, 2025Discovering efficient algorithms for solving complex problems has been an outstanding challenge in mathematics and computer science, requiring substantial human expertise over the years. Recent advancements in evolutionary search with large language models (LLMs) have shown promise in accelerating the discovery of algorithms across various domains, particularly in mathematics and optimization. However, existing approaches treat the LLM as a static generator, missing the opportunity to update the model with the signal obtained from evolutionary exploration. In this work, we propose to augment LLM-based evolutionary search by continuously refining the search operator - the LLM - through reinforcement learning (RL) fine-tuning. Our method leverages evolutionary search as an exploration strategy to discover improved algorithms, while RL optimizes the LLM policy based on these discoveries. Our experiments on three combinatorial optimization tasks - bin packing, traveling salesman, and the flatpack problem - show that combining RL and evolutionary search improves discovery efficiency of improved algorithms, showcasing the potential of RL-enhanced evolutionary strategies to assist computer scientists and mathematicians for more efficient algorithm design.
The Role of Deep Learning Regularizations on Actors in Offline RL
Sep 11, 2024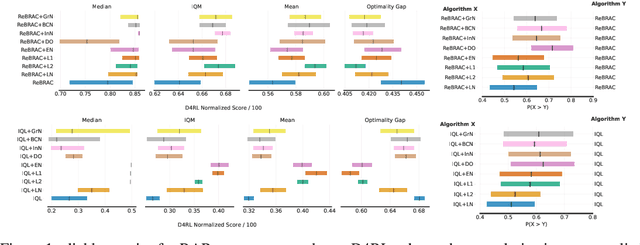

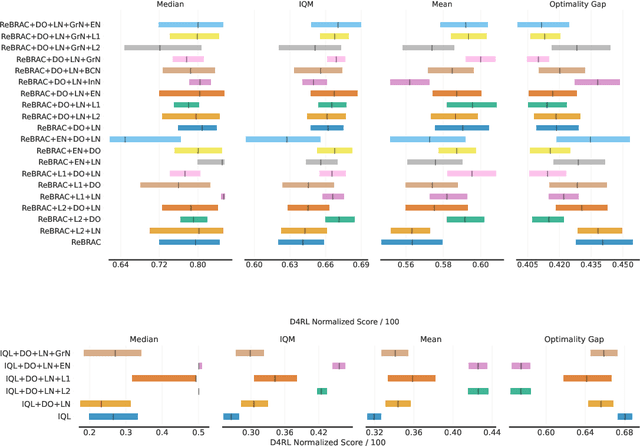

Deep learning regularization techniques, such as \emph{dropout}, \emph{layer normalization}, or \emph{weight decay}, are widely adopted in the construction of modern artificial neural networks, often resulting in more robust training processes and improved generalization capabilities. However, in the domain of \emph{Reinforcement Learning} (RL), the application of these techniques has been limited, usually applied to value function estimators \citep{hiraoka2021dropout, smith2022walk}, and may result in detrimental effects. This issue is even more pronounced in offline RL settings, which bear greater similarity to supervised learning but have received less attention. Recent work in continuous offline RL has demonstrated that while we can build sufficiently powerful critic networks, the generalization of actor networks remains a bottleneck. In this study, we empirically show that applying standard regularization techniques to actor networks in offline RL actor-critic algorithms yields improvements of 6\% on average across two algorithms and three different continuous D4RL domains.