 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Real-World Dexterous Policy Fine-Tuning via Action-Chunked Critics and Normalizing Flows
Feb 10, 2026Real-world fine-tuning of dexterous manipulation policies remains challenging due to limited real-world interaction budgets and highly multimodal action distributions. Diffusion-based policies, while expressive, do not permit conservative likelihood-based updates during fine-tuning because action probabilities are intractable. In contrast, conventional Gaussian policies collapse under multimodality, particularly when actions are executed in chunks, and standard per-step critics fail to align with chunked execution, leading to poor credit assignment. We present SOFT-FLOW, a sample-efficient off-policy fine-tuning framework with normalizing flow (NF) to address these challenges. The normalizing flow policy yields exact likelihoods for multimodal action chunks, allowing conservative, stable policy updates through likelihood regularization and thereby improving sample efficiency. An action-chunked critic evaluates entire action sequences, aligning value estimation with the policy's temporal structure and improving long-horizon credit assignment. To our knowledge, this is the first demonstration of a likelihood-based, multimodal generative policy combined with chunk-level value learning on real robotic hardware. We evaluate SOFT-FLOW on two challenging dexterous manipulation tasks in the real world: cutting tape with scissors retrieved from a case, and in-hand cube rotation with a palm-down grasp -- both of which require precise, dexterous control over long horizons. On these tasks, SOFT-FLOW achieves stable, sample-efficient adaptation where standard methods struggle.
Vision-Language Models Unlock Task-Centric Latent Actions
Jan 30, 2026Latent Action Models (LAMs) have rapidly gained traction as an important component in the pre-training pipelines of leading Vision-Language-Action models. However, they fail when observations contain action-correlated distractors, often encoding noise instead of meaningful latent actions. Humans, on the other hand, can effortlessly distinguish task-relevant motions from irrelevant details in any video given only a brief task description. In this work, we propose to utilize the common-sense reasoning abilities of Vision-Language Models (VLMs) to provide promptable representations, effectively separating controllable changes from the noise in unsupervised way. We use these representations as targets during LAM training and benchmark a wide variety of popular VLMs, revealing substantial variation in the quality of promptable representations as well as their robustness to different prompts and hyperparameters. Interestingly, we find that more recent VLMs may perform worse than older ones. Finally, we show that simply asking VLMs to ignore distractors can substantially improve latent action quality, yielding up to a six-fold increase in downstream success rates on Distracting MetaWorld.
NinA: Normalizing Flows in Action. Training VLA Models with Normalizing Flows
Aug 23, 2025



Recent advances in Vision-Language-Action (VLA) models have established a two-component architecture, where a pre-trained Vision-Language Model (VLM) encodes visual observations and task descriptions, and an action decoder maps these representations to continuous actions. Diffusion models have been widely adopted as action decoders due to their ability to model complex, multimodal action distributions. However, they require multiple iterative denoising steps at inference time or downstream techniques to speed up sampling, limiting their practicality in real-world settings where high-frequency control is crucial. In this work, we present NinA (Normalizing Flows in Action), a fast and expressive alter- native to diffusion-based decoders for VLAs. NinA replaces the diffusion action decoder with a Normalizing Flow (NF) that enables one-shot sampling through an invertible transformation, significantly reducing inference time. We integrate NinA into the FLOWER VLA architecture and fine-tune on the LIBERO benchmark. Our experiments show that NinA matches the performance of its diffusion-based counterpart under the same training regime, while achieving substantially faster inference. These results suggest that NinA offers a promising path toward efficient, high-frequency VLA control without compromising performance.
cadrille: Multi-modal CAD Reconstruction with Online Reinforcement Learning
May 28, 2025Computer-Aided Design (CAD) plays a central role in engineering and manufacturing, making it possible to create precise and editable 3D models. Using a variety of sensor or user-provided data as inputs for CAD reconstruction can democratize access to design applications. However, existing methods typically focus on a single input modality, such as point clouds, images, or text, which limits their generalizability and robustness. Leveraging recent advances in vision-language models (VLM), we propose a multi-modal CAD reconstruction model that simultaneously processes all three input modalities. Inspired by large language model (LLM) training paradigms, we adopt a two-stage pipeline: supervised fine-tuning (SFT) on large-scale procedurally generated data, followed by reinforcement learning (RL) fine-tuning using online feedback, obtained programatically. Furthermore, we are the first to explore RL fine-tuning of LLMs for CAD tasks demonstrating that online RL algorithms such as Group Relative Preference Optimization (GRPO) outperform offline alternatives. In the DeepCAD benchmark, our SFT model outperforms existing single-modal approaches in all three input modalities simultaneously. More importantly, after RL fine-tuning, cadrille sets new state-of-the-art on three challenging datasets, including a real-world one.
Yes, Q-learning Helps Offline In-Context RL
Feb 24, 2025



In this work, we explore the integration of Reinforcement Learning (RL) approaches within a scalable offline In-Context RL (ICRL) framework. Through experiments across more than 150 datasets derived from GridWorld and MuJoCo environments, we demonstrate that optimizing RL objectives improves performance by approximately 40% on average compared to the widely established Algorithm Distillation (AD) baseline across various dataset coverages, structures, expertise levels, and environmental complexities. Our results also reveal that offline RL-based methods outperform online approaches, which are not specifically designed for offline scenarios. These findings underscore the importance of aligning the learning objectives with RL's reward-maximization goal and demonstrate that offline RL is a promising direction for application in ICRL settings.
Vintix: Action Model via In-Context Reinforcement Learning
Jan 31, 2025In-Context Reinforcement Learning (ICRL) represents a promising paradigm for developing generalist agents that learn at inference time through trial-and-error interactions, analogous to how large language models adapt contextually, but with a focus on reward maximization. However, the scalability of ICRL beyond toy tasks and single-domain settings remains an open challenge. In this work, we present the first steps toward scaling ICRL by introducing a fixed, cross-domain model capable of learning behaviors through in-context reinforcement learning. Our results demonstrate that Algorithm Distillation, a framework designed to facilitate ICRL, offers a compelling and competitive alternative to expert distillation to construct versatile action models. These findings highlight the potential of ICRL as a scalable approach for generalist decision-making systems. Code to be released at https://github.com/dunnolab/vintix
The Role of Deep Learning Regularizations on Actors in Offline RL
Sep 11, 2024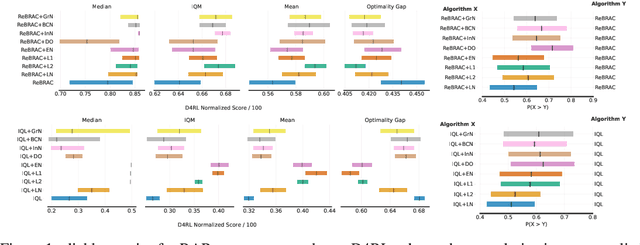

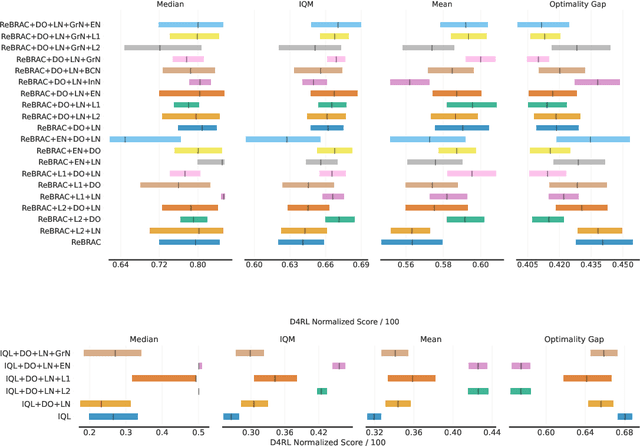

Deep learning regularization techniques, such as \emph{dropout}, \emph{layer normalization}, or \emph{weight decay}, are widely adopted in the construction of modern artificial neural networks, often resulting in more robust training processes and improved generalization capabilities. However, in the domain of \emph{Reinforcement Learning} (RL), the application of these techniques has been limited, usually applied to value function estimators \citep{hiraoka2021dropout, smith2022walk}, and may result in detrimental effects. This issue is even more pronounced in offline RL settings, which bear greater similarity to supervised learning but have received less attention. Recent work in continuous offline RL has demonstrated that while we can build sufficiently powerful critic networks, the generalization of actor networks remains a bottleneck. In this study, we empirically show that applying standard regularization techniques to actor networks in offline RL actor-critic algorithms yields improvements of 6\% on average across two algorithms and three different continuous D4RL domains.
Is Value Functions Estimation with Classification Plug-and-play for Offline Reinforcement Learning?
Jun 10, 2024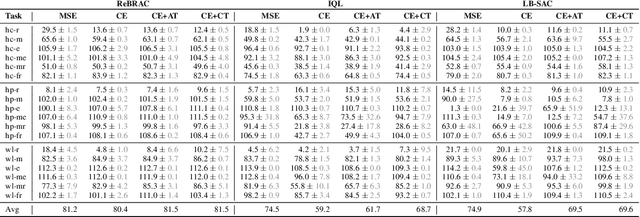



In deep Reinforcement Learning (RL), value functions are typically approximated using deep neural networks and trained via mean squared error regression objectives to fit the true value functions. Recent research has proposed an alternative approach, utilizing the cross-entropy classification objective, which has demonstrated improved performance and scalability of RL algorithms. However, existing study have not extensively benchmarked the effects of this replacement across various domains, as the primary objective was to demonstrate the efficacy of the concept across a broad spectrum of tasks, without delving into in-depth analysis. Our work seeks to empirically investigate the impact of such a replacement in an offline RL setup and analyze the effects of different aspects on performance. Through large-scale experiments conducted across a diverse range of tasks using different algorithms, we aim to gain deeper insights into the implications of this approach. Our results reveal that incorporating this change can lead to superior performance over state-of-the-art solutions for some algorithms in certain tasks, while maintaining comparable performance levels in other tasks, however for other algorithms this modification might lead to the dramatic performance drop. This findings are crucial for further application of classification approach in research and practical tasks.
Distilling LLMs' Decomposition Abilities into Compact Language Models
Feb 02, 2024
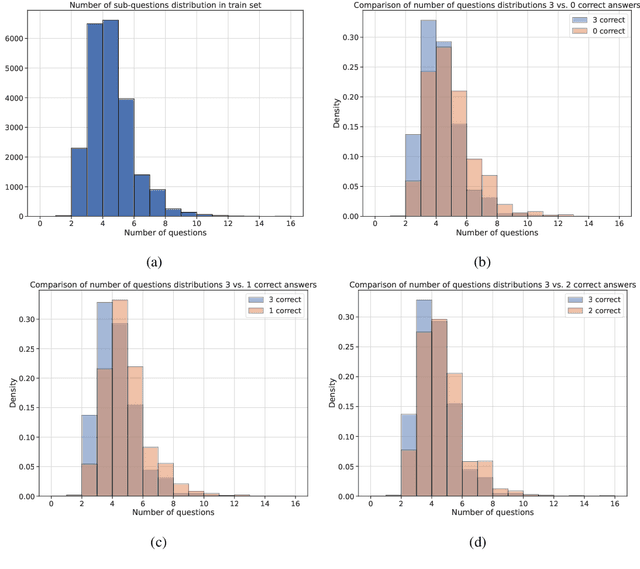
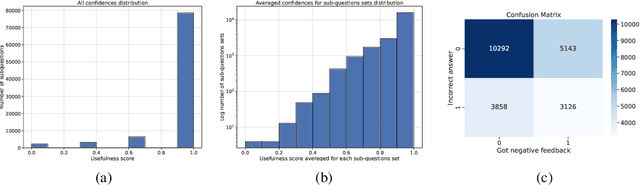
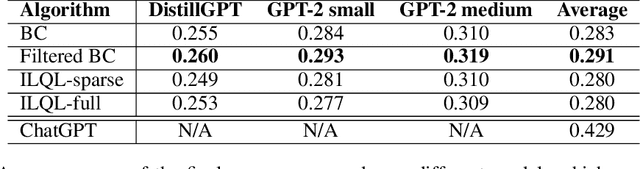
Large Language Models (LLMs) have demonstrated proficiency in their reasoning abilities, yet their large size presents scalability challenges and limits any further customization. In contrast, compact models offer customized training but often fall short in solving complex reasoning tasks. This study focuses on distilling the LLMs' decomposition skills into compact models using offline reinforcement learning. We leverage the advancements in the LLM`s capabilities to provide feedback and generate a specialized task-specific dataset for training compact models. The development of an AI-generated dataset and the establishment of baselines constitute the primary contributions of our work, underscoring the potential of compact models in replicating complex problem-solving skills.
Katakomba: Tools and Benchmarks for Data-Driven NetHack
Jun 14, 2023NetHack is known as the frontier of reinforcement learning research where learning-based methods still need to catch up to rule-based solutions. One of the promising directions for a breakthrough is using pre-collected datasets similar to recent developments in robotics, recommender systems, and more under the umbrella of offline reinforcement learning (ORL). Recently, a large-scale NetHack dataset was released; while it was a necessary step forward, it has yet to gain wide adoption in the ORL community. In this work, we argue that there are three major obstacles for adoption: tool-wise, implementation-wise, and benchmark-wise. To address them, we develop an open-source library that provides workflow fundamentals familiar to the ORL community: pre-defined D4RL-style tasks, uncluttered baseline implementations, and reliable evaluation tools with accompanying configs and logs synced to the cloud.