 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting BPR: A Replicability Study of a Common Recommender System Baseline
Sep 21, 2024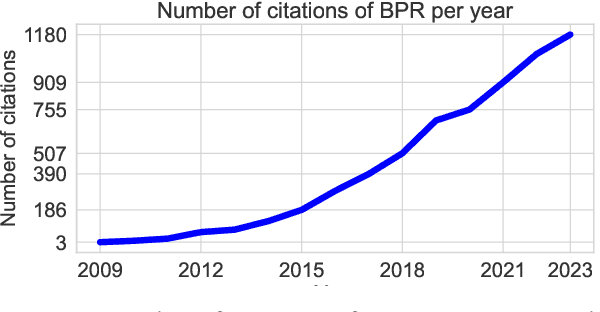
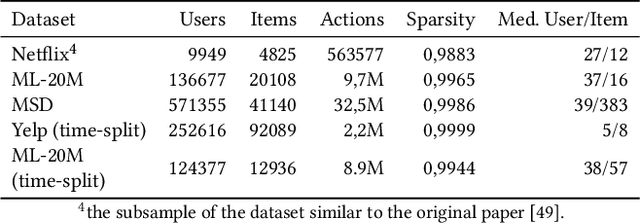
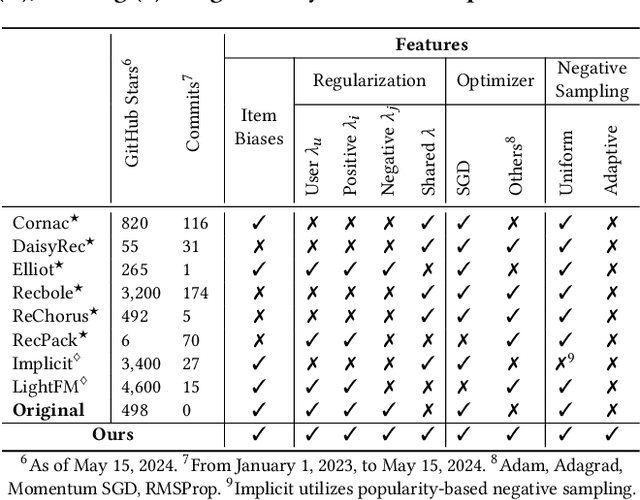
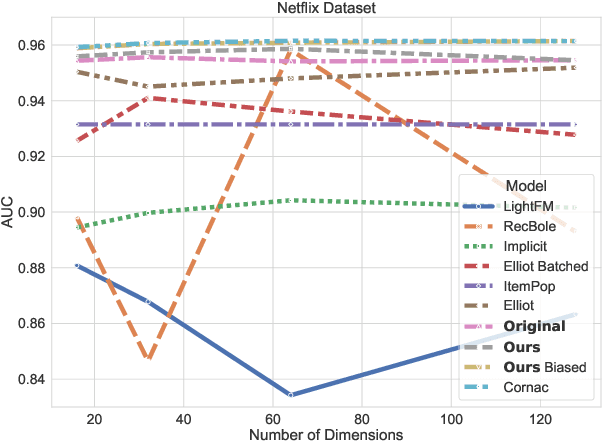
Bayesian Personalized Ranking (BPR), a collaborative filtering approach based on matrix factorization, frequently serves as a benchmark for recommender systems research. However, numerous studies often overlook the nuances of BPR implementation, claiming that it performs worse than newly proposed methods across various tasks. In this paper, we thoroughly examine the features of the BPR model, indicating their impact on its performance, and investigate open-source BPR implementations. Our analysis reveals inconsistencies between these implementations and the original BPR paper, leading to a significant decrease in performance of up to 50% for specific implementations. Furthermore, through extensive experiments on real-world datasets under modern evaluation settings, we demonstrate that with proper tuning of its hyperparameters, the BPR model can achieve performance levels close to state-of-the-art methods on the top-n recommendation tasks and even outperform them on specific datasets. Specifically, on the Million Song Dataset, the BPR model with hyperparameters tuning statistically significantly outperforms Mult-VAE by 10% in NDCG@100 with binary relevance function.
XLand-100B: A Large-Scale Multi-Task Dataset for In-Context Reinforcement Learning
Jun 13, 2024



Following the success of the in-context learning paradigm in large-scale language and computer vision models, the recently emerging field of in-context reinforcement learning is experiencing a rapid growth. However, its development has been held back by the lack of challenging benchmarks, as all the experiments have been carried out in simple environments and on small-scale datasets. We present \textbf{XLand-100B}, a large-scale dataset for in-context reinforcement learning based on the XLand-MiniGrid environment, as a first step to alleviate this problem. It contains complete learning histories for nearly $30,000$ different tasks, covering $100$B transitions and $2.5$B episodes. It took $50,000$ GPU hours to collect the dataset, which is beyond the reach of most academic labs. Along with the dataset, we provide the utilities to reproduce or expand it even further. With this substantial effort, we aim to democratize research in the rapidly growing field of in-context reinforcement learning and provide a solid foundation for further scaling. The code is open-source and available under Apache 2.0 licence at https://github.com/dunno-lab/xland-minigrid-datasets.
In-Context Reinforcement Learning for Variable Action Spaces
Dec 20, 2023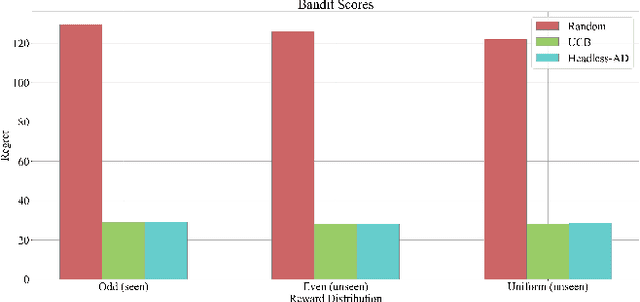
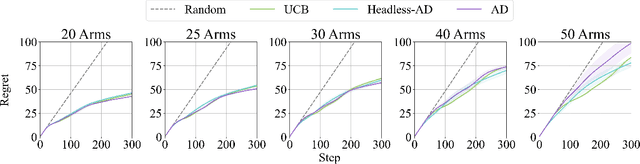
Recent work has shown that supervised pre-training on learning histories of RL algorithms results in a model that captures the learning process and is able to improve in-context on novel tasks through interactions with an environment. Despite the progress in this area, there is still a gap in the existing literature, particularly in the in-context generalization to new action spaces. While existing methods show high performance on new tasks created by different reward distributions, their architectural design and training process are not suited for the introduction of new actions during evaluation. We aim to bridge this gap by developing an architecture and training methodology specifically for the task of generalizing to new action spaces. Inspired by Headless LLM, we remove the dependence on the number of actions by directly predicting the action embeddings. Furthermore, we use random embeddings to force the semantic inference of actions from context and to prepare for the new unseen embeddings during test time. Using multi-armed bandit environments with a variable number of arms, we show that our model achieves the performance of the data generation algorithm without requiring retraining for each new environment.
Emergence of In-Context Reinforcement Learning from Noise Distillation
Dec 19, 2023
In-Context Reinforcement Learning is an emerging field with great potential for advancing Artificial Intelligence. Its core capability lies in generalizing to unseen tasks through interaction with the environment. To master these capabilities, an agent must be trained on specifically curated data that includes a policy improvement that an algorithm seeks to extract and then apply in context in the environment. However, for numerous tasks, training RL agents may be unfeasible, while obtaining human demonstrations can be relatively easy. Additionally, it is rare to be given the optimal policy, typically, only suboptimal demonstrations are available. We propose $AD^{\epsilon}$, a method that leverages demonstrations without policy improvement and enables multi-task in-context learning in the presence of a suboptimal demonstrator. This is achieved by artificially creating a history of incremental improvement, wherein noise is systematically introduced into the demonstrator's policy. Consequently, each successive transition illustrates a marginally better trajectory than the previous one. Our approach was tested on the Dark Room and Dark Key-to-Door environments, resulting in over a $\textbf{2}$x improvement compared to the best available policy in the data.
XLand-MiniGrid: Scalable Meta-Reinforcement Learning Environments in JAX
Dec 19, 2023We present XLand-MiniGrid, a suite of tools and grid-world environments for meta-reinforcement learning research inspired by the diversity and depth of XLand and the simplicity and minimalism of MiniGrid. XLand-Minigrid is written in JAX, designed to be highly scalable, and can potentially run on GPU or TPU accelerators, democratizing large-scale experimentation with limited resources. To demonstrate the generality of our library, we have implemented some well-known single-task environments as well as new meta-learning environments capable of generating $10^8$ distinct tasks. We have empirically shown that the proposed environments can scale up to $2^{13}$ parallel instances on the GPU, reaching tens of millions of steps per second.
Unveiling Empirical Pathologies of Laplace Approximation for Uncertainty Estimation
Dec 16, 2023In this paper, we critically evaluate Bayesian methods for uncertainty estimation in deep learning, focusing on the widely applied Laplace approximation and its variants. Our findings reveal that the conventional method of fitting the Hessian matrix negatively impacts out-of-distribution (OOD) detection efficiency. We propose a different point of view, asserting that focusing solely on optimizing prior precision can yield more accurate uncertainty estimates in OOD detection while preserving adequate calibration metrics. Moreover, we demonstrate that this property is not connected to the training stage of a model but rather to its intrinsic properties. Through extensive experimental evaluation, we establish the superiority of our simplified approach over traditional methods in the out-of-distribution domain.
Wild-Tab: A Benchmark For Out-Of-Distribution Generalization In Tabular Regression
Dec 04, 2023Out-of-Distribution (OOD) generalization, a cornerstone for building robust machine learning models capable of handling data diverging from the training set's distribution, is an ongoing challenge in deep learning. While significant progress has been observed in computer vision and natural language processing, its exploration in tabular data, ubiquitous in many industrial applications, remains nascent. To bridge this gap, we present Wild-Tab, a large-scale benchmark tailored for OOD generalization in tabular regression tasks. The benchmark incorporates 3 industrial datasets sourced from fields like weather prediction and power consumption estimation, providing a challenging testbed for evaluating OOD performance under real-world conditions. Our extensive experiments, evaluating 10 distinct OOD generalization methods on Wild-Tab, reveal nuanced insights. We observe that many of these methods often struggle to maintain high-performance levels on unseen data, with OOD performance showing a marked drop compared to in-distribution performance. At the same time, Empirical Risk Minimization (ERM), despite its simplicity, delivers robust performance across all evaluations, rivaling the results of state-of-the-art methods. Looking forward, we hope that the release of Wild-Tab will facilitate further research on OOD generalization and aid in the deployment of machine learning models in various real-world contexts where handling distribution shifts is a crucial requirement.
Time-Aware Item Weighting for the Next Basket Recommendations
Jul 30, 2023



In this paper we study the next basket recommendation problem. Recent methods use different approaches to achieve better performance. However, many of them do not use information about the time of prediction and time intervals between baskets. To fill this gap, we propose a novel method, Time-Aware Item-based Weighting (TAIW), which takes timestamps and intervals into account. We provide experiments on three real-world datasets, and TAIW outperforms well-tuned state-of-the-art baselines for next-basket recommendations. In addition, we show the results of an ablation study and a case study of a few items.
RecBaselines2023: a new dataset for choosing baselines for recommender models
Jun 25, 2023
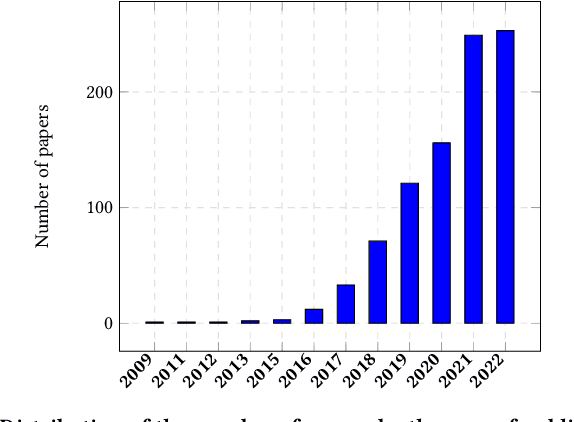
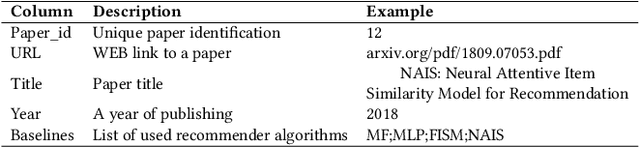
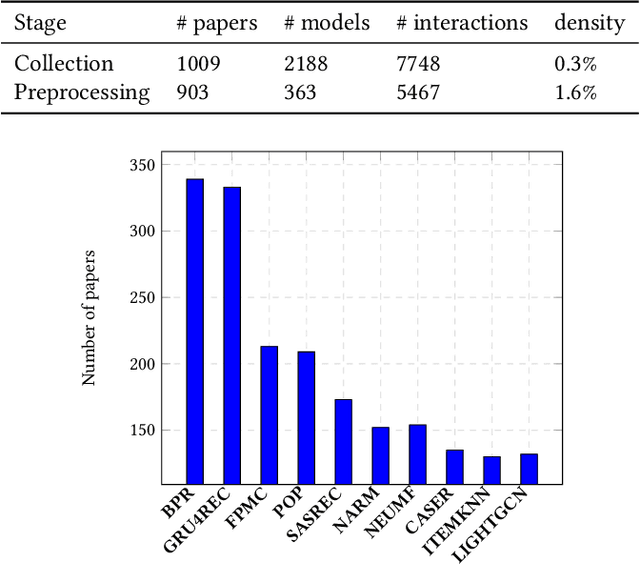
The number of proposed recommender algorithms continues to grow. The authors propose new approaches and compare them with existing models, called baselines. Due to the large number of recommender models, it is difficult to estimate which algorithms to choose in the article. To solve this problem, we have collected and published a dataset containing information about the recommender models used in 903 papers, both as baselines and as proposed approaches. This dataset can be seen as a typical dataset with interactions between papers and previously proposed models. In addition, we provide a descriptive analysis of the dataset and highlight possible challenges to be investigated with the data. Furthermore, we have conducted extensive experiments using a well-established methodology to build a good recommender algorithm under the dataset. Our experiments show that the selection of the best baselines for proposing new recommender approaches can be considered and successfully solved by existing state-of-the-art collaborative filtering models. Finally, we discuss limitations and future work.
Katakomba: Tools and Benchmarks for Data-Driven NetHack
Jun 14, 2023NetHack is known as the frontier of reinforcement learning research where learning-based methods still need to catch up to rule-based solutions. One of the promising directions for a breakthrough is using pre-collected datasets similar to recent developments in robotics, recommender systems, and more under the umbrella of offline reinforcement learning (ORL). Recently, a large-scale NetHack dataset was released; while it was a necessary step forward, it has yet to gain wide adoption in the ORL community. In this work, we argue that there are three major obstacles for adoption: tool-wise, implementation-wise, and benchmark-wise. To address them, we develop an open-source library that provides workflow fundamentals familiar to the ORL community: pre-defined D4RL-style tasks, uncluttered baseline implementations, and reliable evaluation tools with accompanying configs and logs synced to the cloud.