 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Reinforcement Learning for Variable Action Spaces
Paper and Code
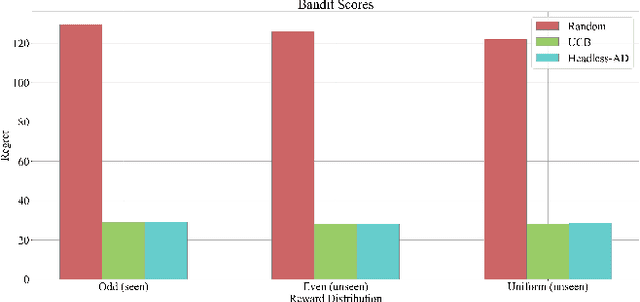
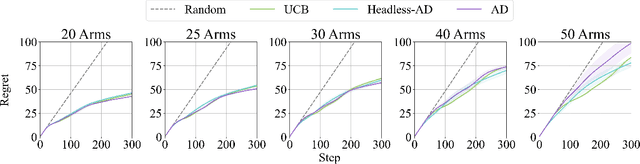
Recent work has shown that supervised pre-training on learning histories of RL algorithms results in a model that captures the learning process and is able to improve in-context on novel tasks through interactions with an environment. Despite the progress in this area, there is still a gap in the existing literature, particularly in the in-context generalization to new action spaces. While existing methods show high performance on new tasks created by different reward distributions, their architectural design and training process are not suited for the introduction of new actions during evaluation. We aim to bridge this gap by developing an architecture and training methodology specifically for the task of generalizing to new action spaces. Inspired by Headless LLM, we remove the dependence on the number of actions by directly predicting the action embeddings. Furthermore, we use random embeddings to force the semantic inference of actions from context and to prepare for the new unseen embeddings during test time. Using multi-armed bandit environments with a variable number of arms, we show that our model achieves the performance of the data generation algorithm without requiring retraining for each new environment.