 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models Unlock Task-Centric Latent Actions
Jan 30, 2026Latent Action Models (LAMs) have rapidly gained traction as an important component in the pre-training pipelines of leading Vision-Language-Action models. However, they fail when observations contain action-correlated distractors, often encoding noise instead of meaningful latent actions. Humans, on the other hand, can effortlessly distinguish task-relevant motions from irrelevant details in any video given only a brief task description. In this work, we propose to utilize the common-sense reasoning abilities of Vision-Language Models (VLMs) to provide promptable representations, effectively separating controllable changes from the noise in unsupervised way. We use these representations as targets during LAM training and benchmark a wide variety of popular VLMs, revealing substantial variation in the quality of promptable representations as well as their robustness to different prompts and hyperparameters. Interestingly, we find that more recent VLMs may perform worse than older ones. Finally, we show that simply asking VLMs to ignore distractors can substantially improve latent action quality, yielding up to a six-fold increase in downstream success rates on Distracting MetaWorld.
NinA: Normalizing Flows in Action. Training VLA Models with Normalizing Flows
Aug 23, 2025Recent advances in Vision-Language-Action (VLA) models have established a two-component architecture, where a pre-trained Vision-Language Model (VLM) encodes visual observations and task descriptions, and an action decoder maps these representations to continuous actions. Diffusion models have been widely adopted as action decoders due to their ability to model complex, multimodal action distributions. However, they require multiple iterative denoising steps at inference time or downstream techniques to speed up sampling, limiting their practicality in real-world settings where high-frequency control is crucial. In this work, we present NinA (Normalizing Flows in Action), a fast and expressive alter- native to diffusion-based decoders for VLAs. NinA replaces the diffusion action decoder with a Normalizing Flow (NF) that enables one-shot sampling through an invertible transformation, significantly reducing inference time. We integrate NinA into the FLOWER VLA architecture and fine-tune on the LIBERO benchmark. Our experiments show that NinA matches the performance of its diffusion-based counterpart under the same training regime, while achieving substantially faster inference. These results suggest that NinA offers a promising path toward efficient, high-frequency VLA control without compromising performance.
cadrille: Multi-modal CAD Reconstruction with Online Reinforcement Learning
May 28, 2025Computer-Aided Design (CAD) plays a central role in engineering and manufacturing, making it possible to create precise and editable 3D models. Using a variety of sensor or user-provided data as inputs for CAD reconstruction can democratize access to design applications. However, existing methods typically focus on a single input modality, such as point clouds, images, or text, which limits their generalizability and robustness. Leveraging recent advances in vision-language models (VLM), we propose a multi-modal CAD reconstruction model that simultaneously processes all three input modalities. Inspired by large language model (LLM) training paradigms, we adopt a two-stage pipeline: supervised fine-tuning (SFT) on large-scale procedurally generated data, followed by reinforcement learning (RL) fine-tuning using online feedback, obtained programatically. Furthermore, we are the first to explore RL fine-tuning of LLMs for CAD tasks demonstrating that online RL algorithms such as Group Relative Preference Optimization (GRPO) outperform offline alternatives. In the DeepCAD benchmark, our SFT model outperforms existing single-modal approaches in all three input modalities simultaneously. More importantly, after RL fine-tuning, cadrille sets new state-of-the-art on three challenging datasets, including a real-world one.
Electrostatics from Laplacian Eigenbasis for Neural Network Interatomic Potentials
May 20, 2025Recent advances in neural network interatomic potentials have emerged as a promising research direction. However, popular deep learning models often lack auxiliary constraints grounded in physical laws, which could accelerate training and improve fidelity through physics-based regularization. In this work, we introduce $\Phi$-Module, a universal plugin module that enforces Poisson's equation within the message-passing framework to learn electrostatic interactions in a self-supervised manner. Specifically, each atom-wise representation is encouraged to satisfy a discretized Poisson's equation, making it possible to acquire a potential $\boldsymbol{\phi}$ and a corresponding charge density $\boldsymbol{\rho}$ linked to the learnable Laplacian eigenbasis coefficients of a given molecular graph. We then derive an electrostatic energy term, crucial for improved total energy predictions. This approach integrates seamlessly into any existing neural potential with insignificant computational overhead. Experiments on the OE62 and MD22 benchmarks confirm that models combined with $\Phi$-Module achieve robust improvements over baseline counterparts. For OE62 error reduction ranges from 4.5\% to 17.8\%, and for MD22, baseline equipped with $\Phi$-Module achieves best results on 5 out of 14 cases. Our results underscore how embedding a first-principles constraint in neural interatomic potentials can significantly improve performance while remaining hyperparameter-friendly, memory-efficient and lightweight in training. Code will be available at \href{https://github.com/dunnolab/phi-module}{dunnolab/phi-module}.
Zero-Shot Adaptation of Behavioral Foundation Models to Unseen Dynamics
May 19, 2025Behavioral Foundation Models (BFMs) proved successful in producing policies for arbitrary tasks in a zero-shot manner, requiring no test-time training or task-specific fine-tuning. Among the most promising BFMs are the ones that estimate the successor measure learned in an unsupervised way from task-agnostic offline data. However, these methods fail to react to changes in the dynamics, making them inefficient under partial observability or when the transition function changes. This hinders the applicability of BFMs in a real-world setting, e.g., in robotics, where the dynamics can unexpectedly change at test time. In this work, we demonstrate that Forward-Backward (FB) representation, one of the methods from the BFM family, cannot distinguish between distinct dynamics, leading to an interference among the latent directions, which parametrize different policies. To address this, we propose a FB model with a transformer-based belief estimator, which greatly facilitates zero-shot adaptation. We also show that partitioning the policy encoding space into dynamics-specific clusters, aligned with the context-embedding directions, yields additional gain in performance. These traits allow our method to respond to the dynamics observed during training and to generalize to unseen ones. Empirically, in the changing dynamics setting, our approach achieves up to a 2x higher zero-shot returns compared to the baselines for both discrete and continuous tasks.
Yes, Q-learning Helps Offline In-Context RL
Feb 24, 2025In this work, we explore the integration of Reinforcement Learning (RL) approaches within a scalable offline In-Context RL (ICRL) framework. Through experiments across more than 150 datasets derived from GridWorld and MuJoCo environments, we demonstrate that optimizing RL objectives improves performance by approximately 40% on average compared to the widely established Algorithm Distillation (AD) baseline across various dataset coverages, structures, expertise levels, and environmental complexities. Our results also reveal that offline RL-based methods outperform online approaches, which are not specifically designed for offline scenarios. These findings underscore the importance of aligning the learning objectives with RL's reward-maximization goal and demonstrate that offline RL is a promising direction for application in ICRL settings.
Vintix: Action Model via In-Context Reinforcement Learning
Jan 31, 2025In-Context Reinforcement Learning (ICRL) represents a promising paradigm for developing generalist agents that learn at inference time through trial-and-error interactions, analogous to how large language models adapt contextually, but with a focus on reward maximization. However, the scalability of ICRL beyond toy tasks and single-domain settings remains an open challenge. In this work, we present the first steps toward scaling ICRL by introducing a fixed, cross-domain model capable of learning behaviors through in-context reinforcement learning. Our results demonstrate that Algorithm Distillation, a framework designed to facilitate ICRL, offers a compelling and competitive alternative to expert distillation to construct versatile action models. These findings highlight the potential of ICRL as a scalable approach for generalist decision-making systems. Code to be released at https://github.com/dunnolab/vintix
N-Gram Induction Heads for In-Context RL: Improving Stability and Reducing Data Needs
Nov 04, 2024In-context learning allows models like transformers to adapt to new tasks from a few examples without updating their weights, a desirable trait for reinforcement learning (RL). However, existing in-context RL methods, such as Algorithm Distillation (AD), demand large, carefully curated datasets and can be unstable and costly to train due to the transient nature of in-context learning abilities. In this work we integrated the n-gram induction heads into transformers for in-context RL. By incorporating these n-gram attention patterns, we significantly reduced the data required for generalization - up to 27 times fewer transitions in the Key-to-Door environment - and eased the training process by making models less sensitive to hyperparameters. Our approach not only matches but often surpasses the performance of AD, demonstrating the potential of n-gram induction heads to enhance the efficiency of in-context RL.
XLand-100B: A Large-Scale Multi-Task Dataset for In-Context Reinforcement Learning
Jun 13, 2024



Following the success of the in-context learning paradigm in large-scale language and computer vision models, the recently emerging field of in-context reinforcement learning is experiencing a rapid growth. However, its development has been held back by the lack of challenging benchmarks, as all the experiments have been carried out in simple environments and on small-scale datasets. We present \textbf{XLand-100B}, a large-scale dataset for in-context reinforcement learning based on the XLand-MiniGrid environment, as a first step to alleviate this problem. It contains complete learning histories for nearly $30,000$ different tasks, covering $100$B transitions and $2.5$B episodes. It took $50,000$ GPU hours to collect the dataset, which is beyond the reach of most academic labs. Along with the dataset, we provide the utilities to reproduce or expand it even further. With this substantial effort, we aim to democratize research in the rapidly growing field of in-context reinforcement learning and provide a solid foundation for further scaling. The code is open-source and available under Apache 2.0 licence at https://github.com/dunno-lab/xland-minigrid-datasets.
In-Context Reinforcement Learning for Variable Action Spaces
Dec 20, 2023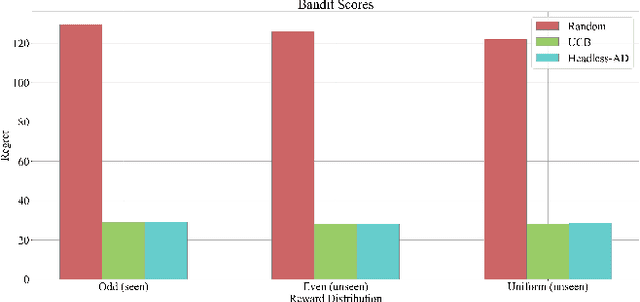
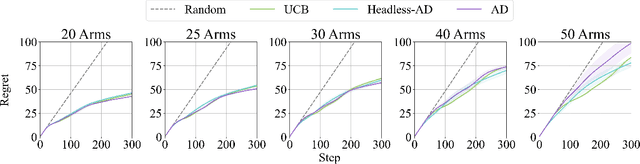
Recent work has shown that supervised pre-training on learning histories of RL algorithms results in a model that captures the learning process and is able to improve in-context on novel tasks through interactions with an environment. Despite the progress in this area, there is still a gap in the existing literature, particularly in the in-context generalization to new action spaces. While existing methods show high performance on new tasks created by different reward distributions, their architectural design and training process are not suited for the introduction of new actions during evaluation. We aim to bridge this gap by developing an architecture and training methodology specifically for the task of generalizing to new action spaces. Inspired by Headless LLM, we remove the dependence on the number of actions by directly predicting the action embeddings. Furthermore, we use random embeddings to force the semantic inference of actions from context and to prepare for the new unseen embeddings during test time. Using multi-armed bandit environments with a variable number of arms, we show that our model achieves the performance of the data generation algorithm without requiring retraining for each new environment.