 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZ3D: Zero-Shot 3D Visual Grounding from Images
Feb 03, 20263D visual grounding (3DVG) aims to localize objects in a 3D scene based on natural language queries. In this work, we explore zero-shot 3DVG from multi-view images alone, without requiring any geometric supervision or object priors. We introduce Z3D, a universal grounding pipeline that flexibly operates on multi-view images while optionally incorporating camera poses and depth maps. We identify key bottlenecks in prior zero-shot methods causing significant performance degradation and address them with (i) a state-of-the-art zero-shot 3D instance segmentation method to generate high-quality 3D bounding box proposals and (ii) advanced reasoning via prompt-based segmentation, which utilizes full capabilities of modern VLMs. Extensive experiments on the ScanRefer and Nr3D benchmarks demonstrate that our approach achieves state-of-the-art performance among zero-shot methods. Code is available at https://github.com/col14m/z3d .
cadrille: Multi-modal CAD Reconstruction with Online Reinforcement Learning
May 28, 2025Computer-Aided Design (CAD) plays a central role in engineering and manufacturing, making it possible to create precise and editable 3D models. Using a variety of sensor or user-provided data as inputs for CAD reconstruction can democratize access to design applications. However, existing methods typically focus on a single input modality, such as point clouds, images, or text, which limits their generalizability and robustness. Leveraging recent advances in vision-language models (VLM), we propose a multi-modal CAD reconstruction model that simultaneously processes all three input modalities. Inspired by large language model (LLM) training paradigms, we adopt a two-stage pipeline: supervised fine-tuning (SFT) on large-scale procedurally generated data, followed by reinforcement learning (RL) fine-tuning using online feedback, obtained programatically. Furthermore, we are the first to explore RL fine-tuning of LLMs for CAD tasks demonstrating that online RL algorithms such as Group Relative Preference Optimization (GRPO) outperform offline alternatives. In the DeepCAD benchmark, our SFT model outperforms existing single-modal approaches in all three input modalities simultaneously. More importantly, after RL fine-tuning, cadrille sets new state-of-the-art on three challenging datasets, including a real-world one.
MultiMAE Meets Earth Observation: Pre-training Multi-modal Multi-task Masked Autoencoders for Earth Observation Tasks
May 20, 2025Multi-modal data in Earth Observation (EO) presents a huge opportunity for improving transfer learning capabilities when pre-training deep learning models. Unlike prior work that often overlooks multi-modal EO data, recent methods have started to include it, resulting in more effective pre-training strategies. However, existing approaches commonly face challenges in effectively transferring learning to downstream tasks where the structure of available data differs from that used during pre-training. This paper addresses this limitation by exploring a more flexible multi-modal, multi-task pre-training strategy for EO data. Specifically, we adopt a Multi-modal Multi-task Masked Autoencoder (MultiMAE) that we pre-train by reconstructing diverse input modalities, including spectral, elevation, and segmentation data. The pre-trained model demonstrates robust transfer learning capabilities, outperforming state-of-the-art methods on various EO datasets for classification and segmentation tasks. Our approach exhibits significant flexibility, handling diverse input configurations without requiring modality-specific pre-trained models. Code will be available at: https://github.com/josesosajs/multimae-meets-eo.
CAD-Assistant: Tool-Augmented VLLMs as Generic CAD Task Solvers?
Dec 18, 2024We propose CAD-Assistant, a general-purpose CAD agent for AI-assisted design. Our approach is based on a powerful Vision and Large Language Model (VLLM) as a planner and a tool-augmentation paradigm using CAD-specific modules. CAD-Assistant addresses multimodal user queries by generating actions that are iteratively executed on a Python interpreter equipped with the FreeCAD software, accessed via its Python API. Our framework is able to assess the impact of generated CAD commands on geometry and adapts subsequent actions based on the evolving state of the CAD design. We consider a wide range of CAD-specific tools including Python libraries, modules of the FreeCAD Python API, helpful routines, rendering functions and other specialized modules. We evaluate our method on multiple CAD benchmarks and qualitatively demonstrate the potential of tool-augmented VLLMs as generic CAD task solvers across diverse CAD workflows.
CAD-Recode: Reverse Engineering CAD Code from Point Clouds
Dec 18, 2024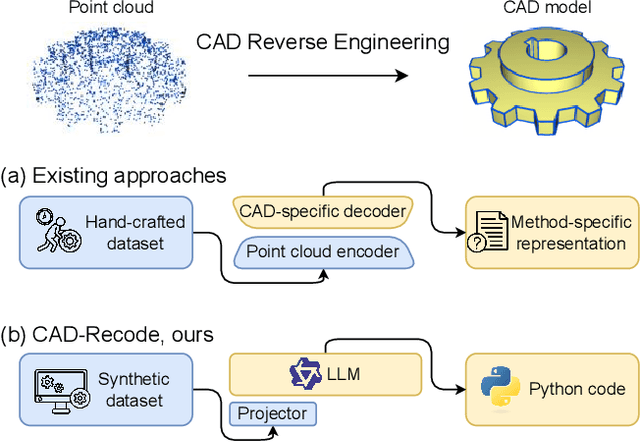
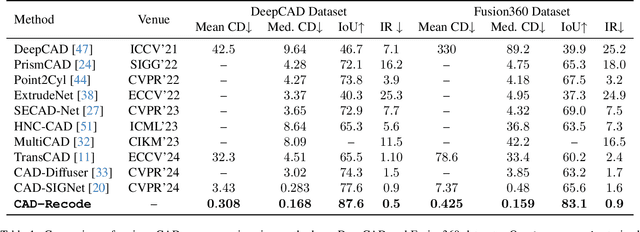

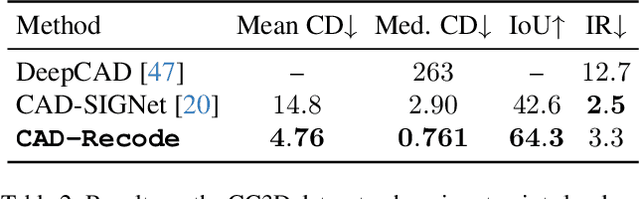
Computer-Aided Design (CAD) models are typically constructed by sequentially drawing parametric sketches and applying CAD operations to obtain a 3D model. The problem of 3D CAD reverse engineering consists of reconstructing the sketch and CAD operation sequences from 3D representations such as point clouds. In this paper, we address this challenge through novel contributions across three levels: CAD sequence representation, network design, and dataset. In particular, we represent CAD sketch-extrude sequences as Python code. The proposed CAD-Recode translates a point cloud into Python code that, when executed, reconstructs the CAD model. Taking advantage of the exposure of pre-trained Large Language Models (LLMs) to Python code, we leverage a relatively small LLM as a decoder for CAD-Recode and combine it with a lightweight point cloud projector. CAD-Recode is trained solely on a proposed synthetic dataset of one million diverse CAD sequences. CAD-Recode significantly outperforms existing methods across three datasets while requiring fewer input points. Notably, it achieves 10 times lower mean Chamfer distance than state-of-the-art methods on DeepCAD and Fusion360 datasets. Furthermore, we show that our CAD Python code output is interpretable by off-the-shelf LLMs, enabling CAD editing and CAD-specific question answering from point clouds.
How Effective is Pre-training of Large Masked Autoencoders for Downstream Earth Observation Tasks?
Sep 27, 2024
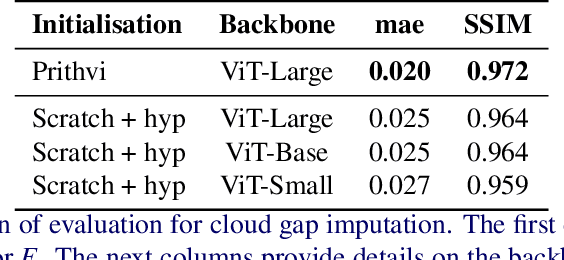


Self-supervised pre-training has proven highly effective for many computer vision tasks, particularly when labelled data are scarce. In the context of Earth Observation (EO), foundation models and various other Vision Transformer (ViT)-based approaches have been successfully applied for transfer learning to downstream tasks. However, it remains unclear under which conditions pre-trained models offer significant advantages over training from scratch. In this study, we investigate the effectiveness of pre-training ViT-based Masked Autoencoders (MAE) for downstream EO tasks, focusing on reconstruction, segmentation, and classification. We consider two large ViT-based MAE pre-trained models: a foundation model (Prithvi) and SatMAE. We evaluate Prithvi on reconstruction and segmentation-based downstream tasks, and for SatMAE we assess its performance on a classification downstream task. Our findings suggest that pre-training is particularly beneficial when the fine-tuning task closely resembles the pre-training task, e.g. reconstruction. In contrast, for tasks such as segmentation or classification, training from scratch with specific hyperparameter adjustments proved to be equally or more effective.
UniDet3D: Multi-dataset Indoor 3D Object Detection
Sep 06, 2024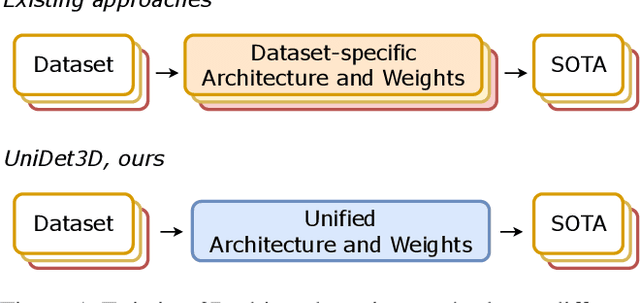
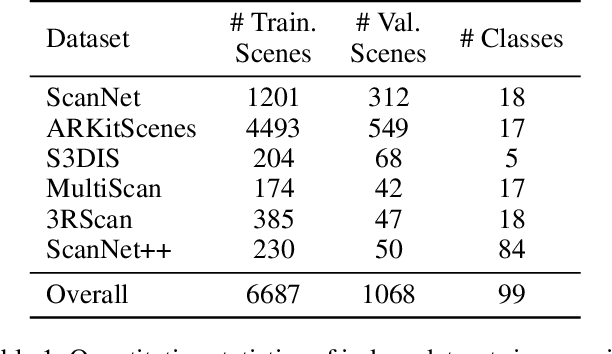
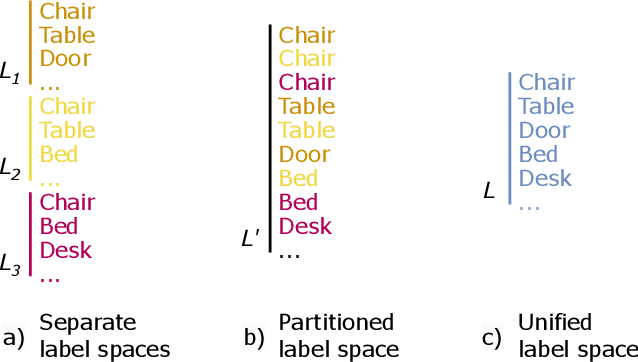
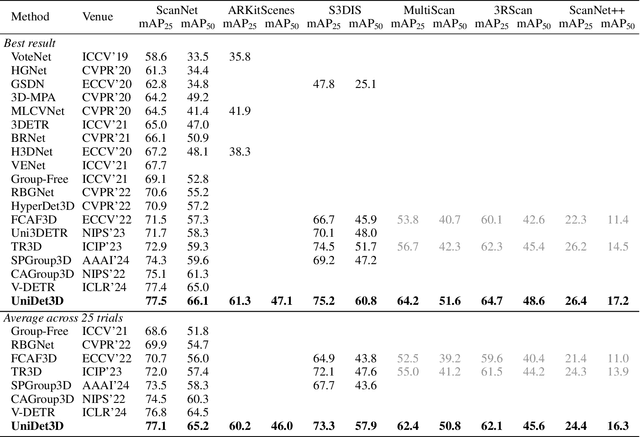
Growing customer demand for smart solutions in robotics and augmented reality has attracted considerable attention to 3D object detection from point clouds. Yet, existing indoor datasets taken individually are too small and insufficiently diverse to train a powerful and general 3D object detection model. In the meantime, more general approaches utilizing foundation models are still inferior in quality to those based on supervised training for a specific task. In this work, we propose \ours{}, a simple yet effective 3D object detection model, which is trained on a mixture of indoor datasets and is capable of working in various indoor environments. By unifying different label spaces, \ours{} enables learning a strong representation across multiple datasets through a supervised joint training scheme. The proposed network architecture is built upon a vanilla transformer encoder, making it easy to run, customize and extend the prediction pipeline for practical use. Extensive experiments demonstrate that \ours{} obtains significant gains over existing 3D object detection methods in 6 indoor benchmarks: ScanNet (+1.1 mAP50), ARKitScenes (+19.4 mAP25), S3DIS (+9.1 mAP50), MultiScan (+9.3 mAP50), 3RScan (+3.2 mAP50), and ScanNet++ (+2.7 mAP50). Code is available at https://github.com/filapro/unidet3d .
OneFormer3D: One Transformer for Unified Point Cloud Segmentation
Nov 24, 2023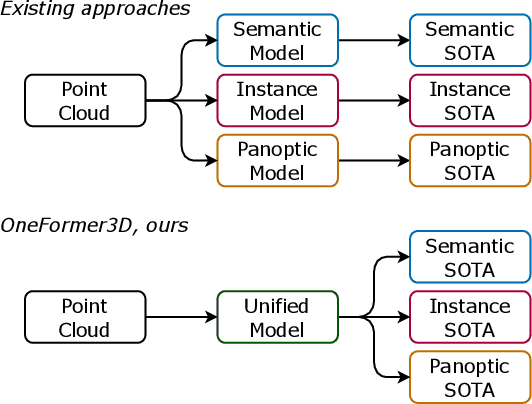



Semantic, instance, and panoptic segmentation of 3D point clouds have been addressed using task-specific models of distinct design. Thereby, the similarity of all segmentation tasks and the implicit relationship between them have not been utilized effectively. This paper presents a unified, simple, and effective model addressing all these tasks jointly. The model, named OneFormer3D, performs instance and semantic segmentation consistently, using a group of learnable kernels, where each kernel is responsible for generating a mask for either an instance or a semantic category. These kernels are trained with a transformer-based decoder with unified instance and semantic queries passed as an input. Such a design enables training a model end-to-end in a single run, so that it achieves top performance on all three segmentation tasks simultaneously. Specifically, our OneFormer3D ranks 1st and sets a new state-of-the-art (+2.1 mAP50) in the ScanNet test leaderboard. We also demonstrate the state-of-the-art results in semantic, instance, and panoptic segmentation of ScanNet (+21 PQ), ScanNet200 (+3.8 mAP50), and S3DIS (+0.8 mIoU) datasets.
TR3D: Towards Real-Time Indoor 3D Object Detection
Feb 08, 2023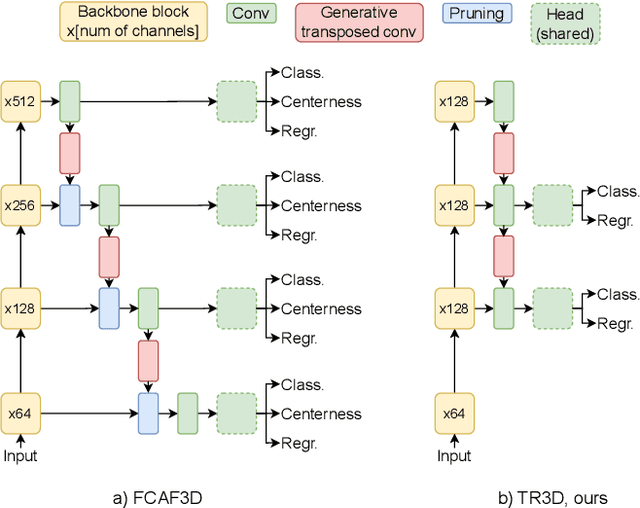
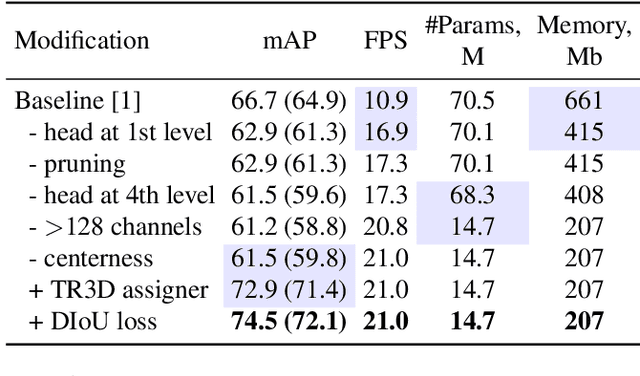

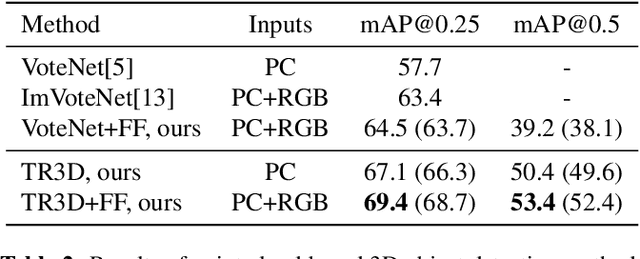
Recently, sparse 3D convolutions have changed 3D object detection. Performing on par with the voting-based approaches, 3D CNNs are memory-efficient and scale to large scenes better. However, there is still room for improvement. With a conscious, practice-oriented approach to problem-solving, we analyze the performance of such methods and localize the weaknesses. Applying modifications that resolve the found issues one by one, we end up with TR3D: a fast fully-convolutional 3D object detection model trained end-to-end, that achieves state-of-the-art results on the standard benchmarks, ScanNet v2, SUN RGB-D, and S3DIS. Moreover, to take advantage of both point cloud and RGB inputs, we introduce an early fusion of 2D and 3D features. We employ our fusion module to make conventional 3D object detection methods multimodal and demonstrate an impressive boost in performance. Our model with early feature fusion, which we refer to as TR3D+FF, outperforms existing 3D object detection approaches on the SUN RGB-D dataset. Overall, besides being accurate, both TR3D and TR3D+FF models are lightweight, memory-efficient, and fast, thereby marking another milestone on the way toward real-time 3D object detection. Code is available at https://github.com/SamsungLabs/tr3d .
Top-Down Beats Bottom-Up in 3D Instance Segmentation
Feb 06, 2023



Most 3D instance segmentation methods exploit a bottom-up strategy, typically including resource-exhaustive post-processing. For point grouping, bottom-up methods rely on prior assumptions about the objects in the form of hyperparameters, which are domain-specific and need to be carefully tuned. On the contrary, we address 3D instance segmentation with a TD3D: top-down, fully data-driven, simple approach trained in an end-to-end manner. With its straightforward fully-convolutional pipeline, it performs surprisingly well on the standard benchmarks: ScanNet v2, its extension ScanNet200, and S3DIS. Besides, our method is much faster on inference than the current state-of-the-art grouping-based approaches. Code is available at https://github.com/SamsungLabs/td3d .