 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAD-Assistant: Tool-Augmented VLLMs as Generic CAD Task Solvers?
Dec 18, 2024We propose CAD-Assistant, a general-purpose CAD agent for AI-assisted design. Our approach is based on a powerful Vision and Large Language Model (VLLM) as a planner and a tool-augmentation paradigm using CAD-specific modules. CAD-Assistant addresses multimodal user queries by generating actions that are iteratively executed on a Python interpreter equipped with the FreeCAD software, accessed via its Python API. Our framework is able to assess the impact of generated CAD commands on geometry and adapts subsequent actions based on the evolving state of the CAD design. We consider a wide range of CAD-specific tools including Python libraries, modules of the FreeCAD Python API, helpful routines, rendering functions and other specialized modules. We evaluate our method on multiple CAD benchmarks and qualitatively demonstrate the potential of tool-augmented VLLMs as generic CAD task solvers across diverse CAD workflows.
DAVINCI: A Single-Stage Architecture for Constrained CAD Sketch Inference
Oct 30, 2024This work presents DAVINCI, a unified architecture for single-stage Computer-Aided Design (CAD) sketch parameterization and constraint inference directly from raster sketch images. By jointly learning both outputs, DAVINCI minimizes error accumulation and enhances the performance of constrained CAD sketch inference. Notably, DAVINCI achieves state-of-the-art results on the large-scale SketchGraphs dataset, demonstrating effectiveness on both precise and hand-drawn raster CAD sketches. To reduce DAVINCI's reliance on large-scale annotated datasets, we explore the efficacy of CAD sketch augmentations. We introduce Constraint-Preserving Transformations (CPTs), i.e. random permutations of the parametric primitives of a CAD sketch that preserve its constraints. This data augmentation strategy allows DAVINCI to achieve reasonable performance when trained with only 0.1% of the SketchGraphs dataset. Furthermore, this work contributes a new version of SketchGraphs, augmented with CPTs. The newly introduced CPTSketchGraphs dataset includes 80 million CPT-augmented sketches, thus providing a rich resource for future research in the CAD sketch domain.
PICASSO: A Feed-Forward Framework for Parametric Inference of CAD Sketches via Rendering Self-Supervision
Jul 18, 2024We propose PICASSO, a novel framework CAD sketch parameterization from hand-drawn or precise sketch images via rendering self-supervision. Given a drawing of a CAD sketch, the proposed framework turns it into parametric primitives that can be imported into CAD software. Compared to existing methods, PICASSO enables the learning of parametric CAD sketches from either precise or hand-drawn sketch images, even in cases where annotations at the parameter level are scarce or unavailable. This is achieved by leveraging the geometric characteristics of sketches as a learning cue to pre-train a CAD parameterization network. Specifically, PICASSO comprises two primary components: (1) a Sketch Parameterization Network (SPN) that predicts a series of parametric primitives from CAD sketch images, and (2) a Sketch Rendering Network (SRN) that renders parametric CAD sketches in a differentiable manner. SRN facilitates the computation of a image-to-image loss, which can be utilized to pre-train SPN, thereby enabling zero- and few-shot learning scenarios for the parameterization of hand-drawn sketches. Extensive evaluation on the widely used SketchGraphs dataset validates the effectiveness of the proposed framework.
SHARP Challenge 2023: Solving CAD History and pArameters Recovery from Point clouds and 3D scans. Overview, Datasets, Metrics, and Baselines
Aug 30, 2023



Recent breakthroughs in geometric Deep Learning (DL) and the availability of large Computer-Aided Design (CAD) datasets have advanced the research on learning CAD modeling processes and relating them to real objects. In this context, 3D reverse engineering of CAD models from 3D scans is considered to be one of the most sought-after goals for the CAD industry. However, recent efforts assume multiple simplifications limiting the applications in real-world settings. The SHARP Challenge 2023 aims at pushing the research a step closer to the real-world scenario of CAD reverse engineering through dedicated datasets and tracks. In this paper, we define the proposed SHARP 2023 tracks, describe the provided datasets, and propose a set of baseline methods along with suitable evaluation metrics to assess the performance of the track solutions. All proposed datasets along with useful routines and the evaluation metrics are publicly available.
TSCom-Net: Coarse-to-Fine 3D Textured Shape Completion Network
Aug 22, 2022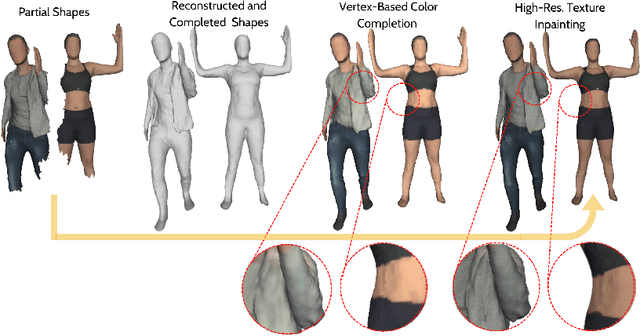
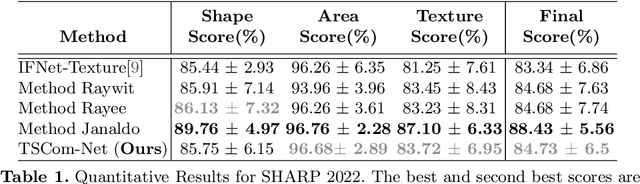


Reconstructing 3D human body shapes from 3D partial textured scans remains a fundamental task for many computer vision and graphics applications -- e.g., body animation, and virtual dressing. We propose a new neural network architecture for 3D body shape and high-resolution texture completion -- BCom-Net -- that can reconstruct the full geometry from mid-level to high-level partial input scans. We decompose the overall reconstruction task into two stages - first, a joint implicit learning network (SCom-Net and TCom-Net) that takes a voxelized scan and its occupancy grid as input to reconstruct the full body shape and predict vertex textures. Second, a high-resolution texture completion network, that utilizes the predicted coarse vertex textures to inpaint the missing parts of the partial 'texture atlas'. A thorough experimental evaluation on 3DBodyTex.V2 dataset shows that our method achieves competitive results with respect to the state-of-the-art while generalizing to different types and levels of partial shapes. The proposed method has also ranked second in the track1 of SHApe Recovery from Partial textured 3D scans (SHARP [38,1]) 2022 challenge1.
Burst Photography for Learning to Enhance Extremely Dark Images
Jun 17, 2020



Capturing images under extremely low-light conditions poses significant challenges for the standard camera pipeline. Images become too dark and too noisy, which makes traditional enhancement techniques almost impossible to apply. Recently, learning-based approaches have shown very promising results for this task since they have substantially more expressive capabilities to allow for improved quality. Motivated by these studies, in this paper, we aim to leverage burst photography to boost the performance and obtain much sharper and more accurate RGB images from extremely dark raw images. The backbone of our proposed framework is a novel coarse-to-fine network architecture that generates high-quality outputs progressively. The coarse network predicts a low-resolution, denoised raw image, which is then fed to the fine network to recover fine-scale details and realistic textures. To further reduce the noise level and improve the color accuracy, we extend this network to a permutation invariant structure so that it takes a burst of low-light images as input and merges information from multiple images at the feature-level. Our experiments demonstrate that our approach leads to perceptually more pleasing results than the state-of-the-art methods by producing more detailed and considerably higher quality images.
Burst Denoising of Dark Images
Mar 17, 2020
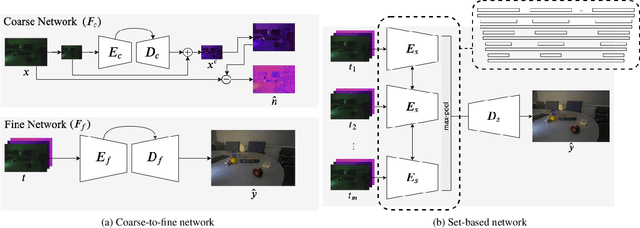
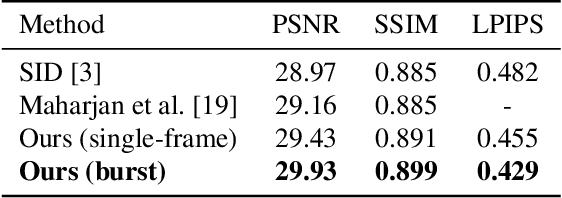

Capturing images under extremely low-light conditions poses significant challenges for the standard camera pipeline. Images become too dark and too noisy, which makes traditional image enhancement techniques almost impossible to apply. Very recently, researchers have shown promising results using learning based approaches. Motivated by these ideas, in this paper, we propose a deep learning framework for obtaining clean and colorful RGB images from extremely dark raw images. The backbone of our framework is a novel coarse-to-fine network architecture that generates high-quality outputs in a progressive manner. The coarse network predicts a low-resolution, denoised raw image, which is then fed to the fine network to recover fine-scale details and realistic textures. To further reduce noise and improve color accuracy, we extend this network to a permutation invariant structure so that it takes a burst of low-light images as input and merges information from multiple images at the feature-level. Our experiments demonstrate that the proposed approach leads to perceptually more pleasing results than state-of-the-art methods by producing much sharper and higher quality images.