 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Autoencoders for Sequential Recommendation Models: Interpretation and Flexible Control
Jul 16, 2025Many current state-of-the-art models for sequential recommendations are based on transformer architectures. Interpretation and explanation of such black box models is an important research question, as a better understanding of their internals can help understand, influence, and control their behavior, which is very important in a variety of real-world applications. Recently sparse autoencoders (SAE) have been shown to be a promising unsupervised approach for extracting interpretable features from language models. These autoencoders learn to reconstruct hidden states of the transformer's internal layers from sparse linear combinations of directions in their activation space. This paper is focused on the application of SAE to the sequential recommendation domain. We show that this approach can be successfully applied to the transformer trained on a sequential recommendation task: learned directions turn out to be more interpretable and monosemantic than the original hidden state dimensions. Moreover, we demonstrate that the features learned by SAE can be used to effectively and flexibly control the model's behavior, providing end-users with a straightforward method to adjust their recommendations to different custom scenarios and contexts.
Simplicial SMOTE: Oversampling Solution to the Imbalanced Learning Problem
Mar 05, 2025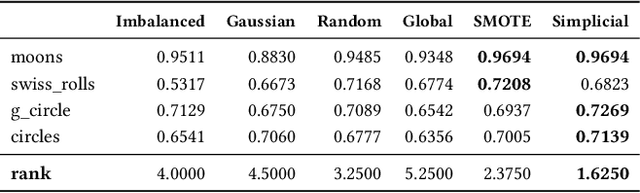
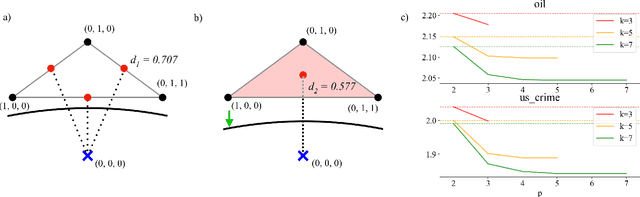
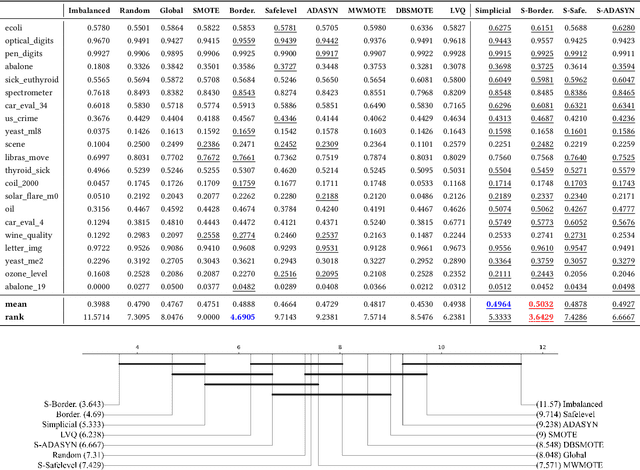
SMOTE (Synthetic Minority Oversampling Technique) is the established geometric approach to random oversampling to balance classes in the imbalanced learning problem, followed by many extensions. Its idea is to introduce synthetic data points of the minor class, with each new point being the convex combination of an existing data point and one of its k-nearest neighbors. In this paper, by viewing SMOTE as sampling from the edges of a geometric neighborhood graph and borrowing tools from the topological data analysis, we propose a novel technique, Simplicial SMOTE, that samples from the simplices of a geometric neighborhood simplicial complex. A new synthetic point is defined by the barycentric coordinates w.r.t. a simplex spanned by an arbitrary number of data points being sufficiently close rather than a pair. Such a replacement of the geometric data model results in better coverage of the underlying data distribution compared to existing geometric sampling methods and allows the generation of synthetic points of the minority class closer to the majority class on the decision boundary. We experimentally demonstrate that our Simplicial SMOTE outperforms several popular geometric sampling methods, including the original SMOTE. Moreover, we show that simplicial sampling can be easily integrated into existing SMOTE extensions. We generalize and evaluate simplicial extensions of the classic Borderline SMOTE, Safe-level SMOTE, and ADASYN algorithms, all of which outperform their graph-based counterparts.
Multimodal Banking Dataset: Understanding Client Needs through Event Sequences
Sep 26, 2024Financial organizations collect a huge amount of data about clients that typically has a temporal (sequential) structure and is collected from various sources (modalities). Due to privacy issues, there are no large-scale open-source multimodal datasets of event sequences, which significantly limits the research in this area. In this paper, we present the industrial-scale publicly available multimodal banking dataset, MBD, that contains more than 1.5M corporate clients with several modalities: 950M bank transactions, 1B geo position events, 5M embeddings of dialogues with technical support and monthly aggregated purchases of four bank's products. All entries are properly anonymized from real proprietary bank data. Using this dataset, we introduce a novel benchmark with two business tasks: campaigning (purchase prediction in the next month) and matching of clients. We provide numerical results that demonstrate the superiority of our multi-modal baselines over single-modal techniques for each task. As a result, the proposed dataset can open new perspectives and facilitate the future development of practically important large-scale multimodal algorithms for event sequences. HuggingFace Link: https://huggingface.co/datasets/ai-lab/MBD Github Link: https://github.com/Dzhambo/MBD
TransCAD: A Hierarchical Transformer for CAD Sequence Inference from Point Clouds
Jul 18, 20243D reverse engineering, in which a CAD model is inferred given a 3D scan of a physical object, is a research direction that offers many promising practical applications. This paper proposes TransCAD, an end-to-end transformer-based architecture that predicts the CAD sequence from a point cloud. TransCAD leverages the structure of CAD sequences by using a hierarchical learning strategy. A loop refiner is also introduced to regress sketch primitive parameters. Rigorous experimentation on the DeepCAD and Fusion360 datasets show that TransCAD achieves state-of-the-art results. The result analysis is supported with a proposed metric for CAD sequence, the mean Average Precision of CAD Sequence, that addresses the limitations of existing metrics.
SHARP Challenge 2023: Solving CAD History and pArameters Recovery from Point clouds and 3D scans. Overview, Datasets, Metrics, and Baselines
Aug 30, 2023



Recent breakthroughs in geometric Deep Learning (DL) and the availability of large Computer-Aided Design (CAD) datasets have advanced the research on learning CAD modeling processes and relating them to real objects. In this context, 3D reverse engineering of CAD models from 3D scans is considered to be one of the most sought-after goals for the CAD industry. However, recent efforts assume multiple simplifications limiting the applications in real-world settings. The SHARP Challenge 2023 aims at pushing the research a step closer to the real-world scenario of CAD reverse engineering through dedicated datasets and tracks. In this paper, we define the proposed SHARP 2023 tracks, describe the provided datasets, and propose a set of baseline methods along with suitable evaluation metrics to assess the performance of the track solutions. All proposed datasets along with useful routines and the evaluation metrics are publicly available.
SepicNet: Sharp Edges Recovery by Parametric Inference of Curves in 3D Shapes
Apr 13, 20233D scanning as a technique to digitize objects in reality and create their 3D models, is used in many fields and areas. Though the quality of 3D scans depends on the technical characteristics of the 3D scanner, the common drawback is the smoothing of fine details, or the edges of an object. We introduce SepicNet, a novel deep network for the detection and parametrization of sharp edges in 3D shapes as primitive curves. To make the network end-to-end trainable, we formulate the curve fitting in a differentiable manner. We develop an adaptive point cloud sampling technique that captures the sharp features better than uniform sampling. The experiments were conducted on a newly introduced large-scale dataset of 50k 3D scans, where the sharp edge annotations were extracted from their parametric CAD models, and demonstrate significant improvement over state-of-the-art methods.
CADOps-Net: Jointly Learning CAD Operation Types and Steps from Boundary-Representations
Aug 22, 2022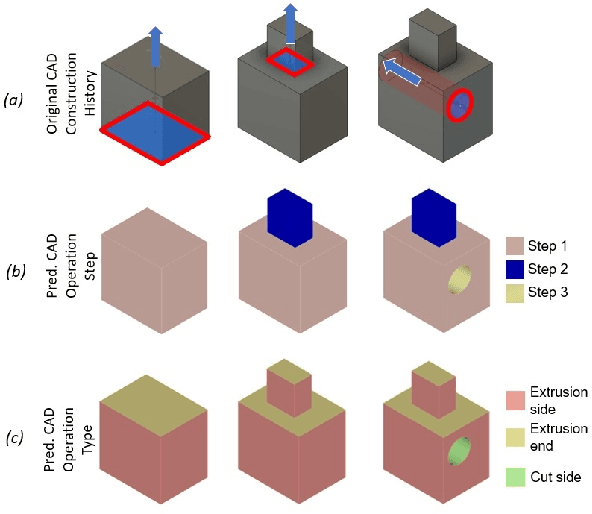



3D reverse engineering is a long sought-after, yet not completely achieved goal in the Computer-Aided Design (CAD) industry. The objective is to recover the construction history of a CAD model. Starting from a Boundary Representation (B-Rep) of a CAD model, this paper proposes a new deep neural network, CADOps-Net, that jointly learns the CAD operation types and the decomposition into different CAD operation steps. This joint learning allows to divide a B-Rep into parts that were created by various types of CAD operations at the same construction step; therefore providing relevant information for further recovery of the design history. Furthermore, we propose the novel CC3D-Ops dataset that includes over $37k$ CAD models annotated with CAD operation type labels and step labels. Compared to existing datasets, the complexity and variety of CC3D-Ops models are closer to those used for industrial purposes. Our experiments, conducted on the proposed CC3D-Ops and the publicly available Fusion360 datasets, demonstrate the competitive performance of CADOps-Net with respect to state-of-the-art, and confirm the importance of the joint learning of CAD operation types and steps.
Towards Computationally Feasible Deep Active Learning
May 07, 2022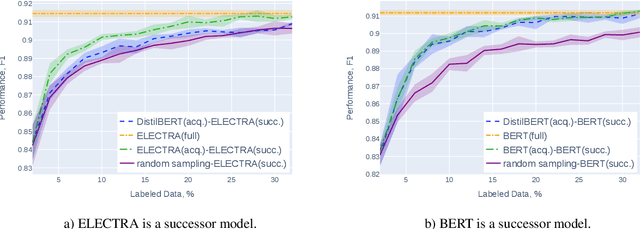
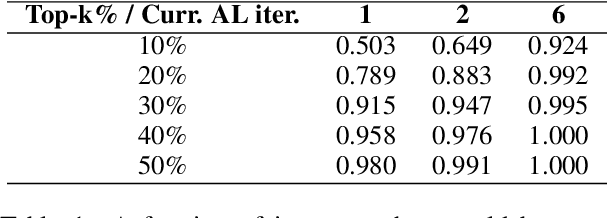
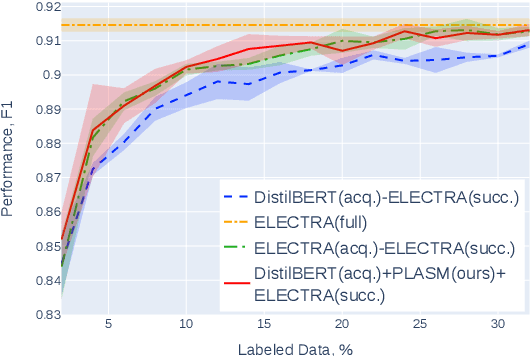
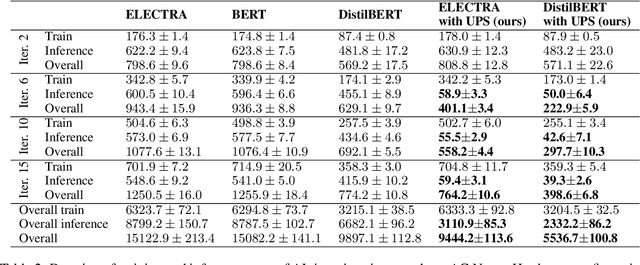
Active learning (AL) is a prominent technique for reducing the annotation effort required for training machine learning models. Deep learning offers a solution for several essential obstacles to deploying AL in practice but introduces many others. One of such problems is the excessive computational resources required to train an acquisition model and estimate its uncertainty on instances in the unlabeled pool. We propose two techniques that tackle this issue for text classification and tagging tasks, offering a substantial reduction of AL iteration duration and the computational overhead introduced by deep acquisition models in AL. We also demonstrate that our algorithm that leverages pseudo-labeling and distilled models overcomes one of the essential obstacles revealed previously in the literature. Namely, it was shown that due to differences between an acquisition model used to select instances during AL and a successor model trained on the labeled data, the benefits of AL can diminish. We show that our algorithm, despite using a smaller and faster acquisition model, is capable of training a more expressive successor model with higher performance.
Adversarial Attacks on Deep Models for Financial Transaction Records
Jun 15, 2021
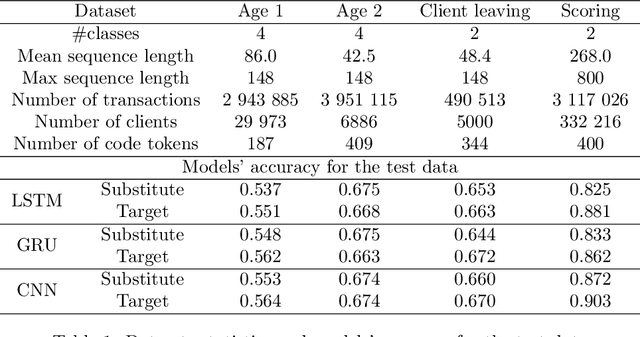
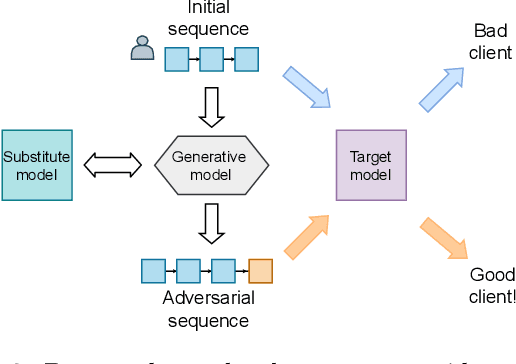
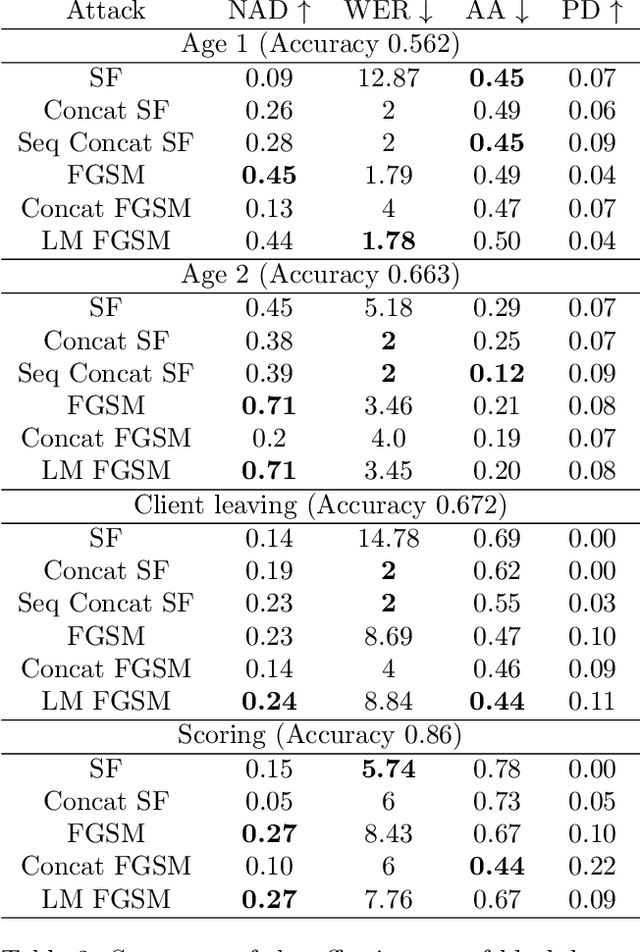
Machine learning models using transaction records as inputs are popular among financial institutions. The most efficient models use deep-learning architectures similar to those in the NLP community, posing a challenge due to their tremendous number of parameters and limited robustness. In particular, deep-learning models are vulnerable to adversarial attacks: a little change in the input harms the model's output. In this work, we examine adversarial attacks on transaction records data and defences from these attacks. The transaction records data have a different structure than the canonical NLP or time series data, as neighbouring records are less connected than words in sentences, and each record consists of both discrete merchant code and continuous transaction amount. We consider a black-box attack scenario, where the attack doesn't know the true decision model, and pay special attention to adding transaction tokens to the end of a sequence. These limitations provide more realistic scenario, previously unexplored in NLP world. The proposed adversarial attacks and the respective defences demonstrate remarkable performance using relevant datasets from the financial industry. Our results show that a couple of generated transactions are sufficient to fool a deep-learning model. Further, we improve model robustness via adversarial training or separate adversarial examples detection. This work shows that embedding protection from adversarial attacks improves model robustness, allowing a wider adoption of deep models for transaction records in banking and finance.
PvDeConv: Point-Voxel Deconvolution for Autoencoding CAD Construction in 3D
Jan 12, 2021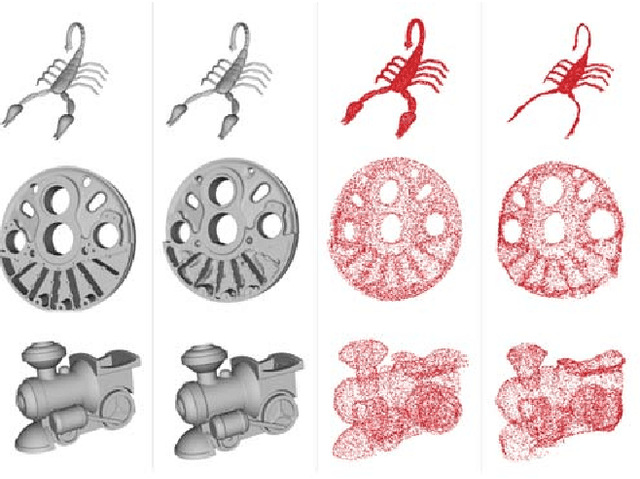



We propose a Point-Voxel DeConvolution (PVDeConv) module for 3D data autoencoder. To demonstrate its efficiency we learn to synthesize high-resolution point clouds of 10k points that densely describe the underlying geometry of Computer Aided Design (CAD) models. Scanning artifacts, such as protrusions, missing parts, smoothed edges and holes, inevitably appear in real 3D scans of fabricated CAD objects. Learning the original CAD model construction from a 3D scan requires a ground truth to be available together with the corresponding 3D scan of an object. To solve the gap, we introduce a new dedicated dataset, the CC3D, containing 50k+ pairs of CAD models and their corresponding 3D meshes. This dataset is used to learn a convolutional autoencoder for point clouds sampled from the pairs of 3D scans - CAD models. The challenges of this new dataset are demonstrated in comparison with other generative point cloud sampling models trained on ShapeNet. The CC3D autoencoder is efficient with respect to memory consumption and training time as compared to stateof-the-art models for 3D data generation.
* 2020 IEEE International Conference on Image Processing (ICIP)