 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-time convolutions model of event sequences
Feb 13, 2023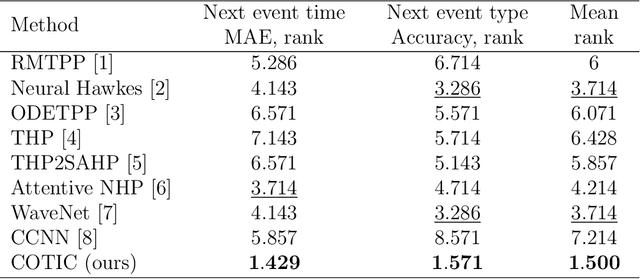
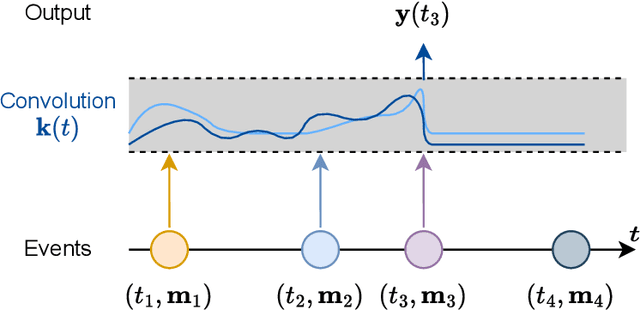
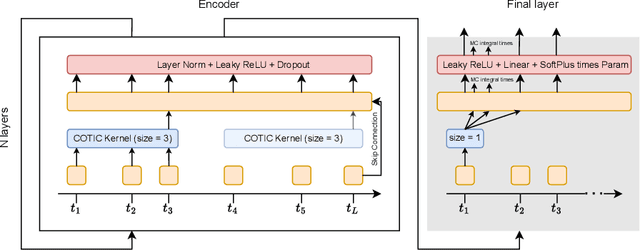

Massive samples of event sequences data occur in various domains, including e-commerce, healthcare, and finance. There are two main challenges regarding inference of such data: computational and methodological. The amount of available data and the length of event sequences per client are typically large, thus it requires long-term modelling. Moreover, this data is often sparse and non-uniform, making classic approaches for time series processing inapplicable. Existing solutions include recurrent and transformer architectures in such cases. To allow continuous time, the authors introduce specific parametric intensity functions defined at each moment on top of existing models. Due to the parametric nature, these intensities represent only a limited class of event sequences. We propose the COTIC method based on a continuous convolution neural network suitable for non-uniform occurrence of events in time. In COTIC, dilations and multi-layer architecture efficiently handle dependencies between events. Furthermore, the model provides general intensity dynamics in continuous time - including self-excitement encountered in practice. The COTIC model outperforms existing approaches on majority of the considered datasets, producing embeddings for an event sequence that can be used to solve downstream tasks - e.g. predicting next event type and return time. The code of the proposed method can be found in the GitHub repository (https://github.com/VladislavZh/COTIC).
Adversarial Attacks on Deep Models for Financial Transaction Records
Jun 15, 2021
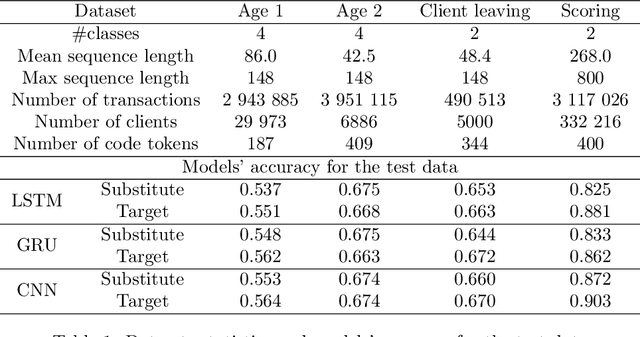
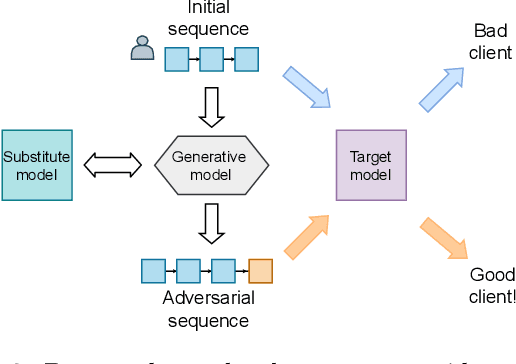
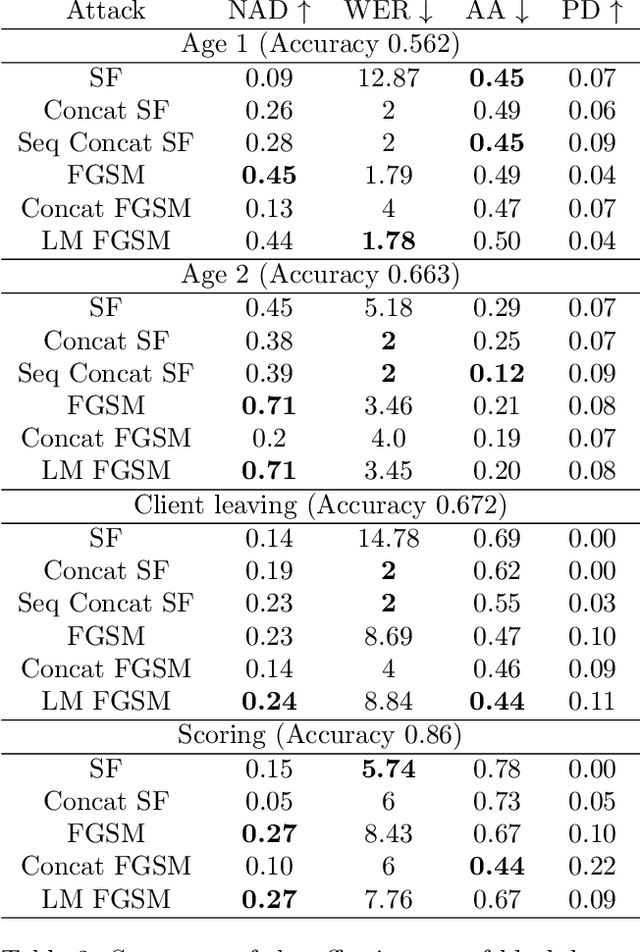
Machine learning models using transaction records as inputs are popular among financial institutions. The most efficient models use deep-learning architectures similar to those in the NLP community, posing a challenge due to their tremendous number of parameters and limited robustness. In particular, deep-learning models are vulnerable to adversarial attacks: a little change in the input harms the model's output. In this work, we examine adversarial attacks on transaction records data and defences from these attacks. The transaction records data have a different structure than the canonical NLP or time series data, as neighbouring records are less connected than words in sentences, and each record consists of both discrete merchant code and continuous transaction amount. We consider a black-box attack scenario, where the attack doesn't know the true decision model, and pay special attention to adding transaction tokens to the end of a sequence. These limitations provide more realistic scenario, previously unexplored in NLP world. The proposed adversarial attacks and the respective defences demonstrate remarkable performance using relevant datasets from the financial industry. Our results show that a couple of generated transactions are sufficient to fool a deep-learning model. Further, we improve model robustness via adversarial training or separate adversarial examples detection. This work shows that embedding protection from adversarial attacks improves model robustness, allowing a wider adoption of deep models for transaction records in banking and finance.
COHORTNEY: Deep Clustering for Heterogeneous Event Sequences
Apr 03, 2021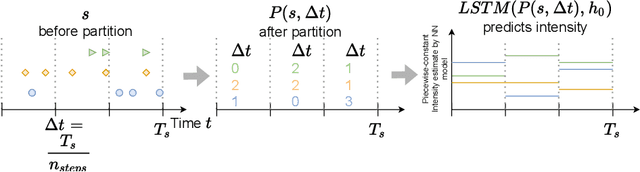
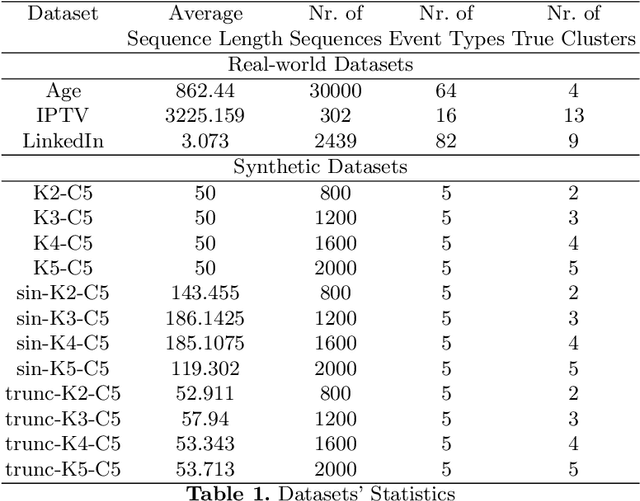
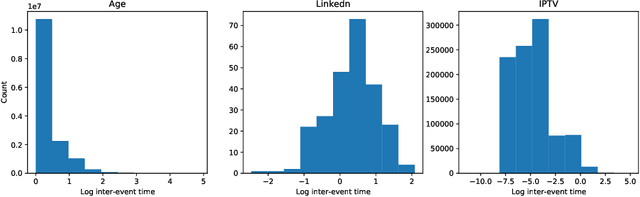
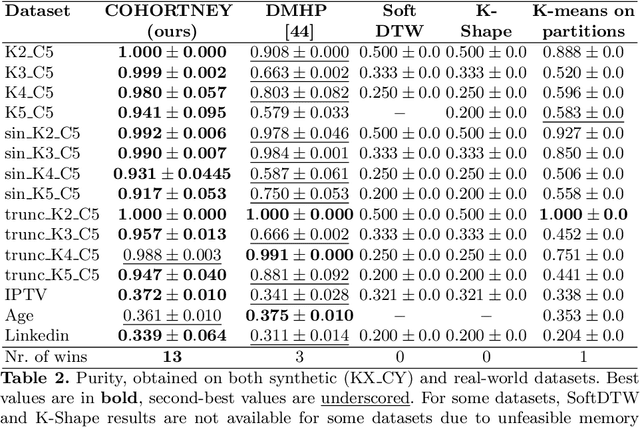
There is emerging attention towards working with event sequences. In particular, clustering of event sequences is widely applicable in domains such as healthcare, marketing, and finance. Use cases include analysis of visitors to websites, hospitals, or bank transactions. Unlike traditional time series, event sequences tend to be sparse and not equally spaced in time. As a result, they exhibit different properties, which are essential to account for when developing state-of-the-art methods. The community has paid little attention to the specifics of heterogeneous event sequences. Existing research in clustering primarily focuses on classic times series data. It is unclear if proposed methods in the literature generalize well to event sequences. Here we propose COHORTNEY as a novel deep learning method for clustering heterogeneous event sequences. Our contributions include (i) a novel method using a combination of LSTM and the EM algorithm and code implementation; (ii) a comparison of this method to previous research on time series and event sequence clustering; (iii) a performance benchmark of different approaches on a new dataset from the finance industry and fourteen additional datasets. Our results show that COHORTNEY vastly outperforms in speed and cluster quality the state-of-the-art algorithm for clustering event sequences.
TOTOPO: Classifying univariate and multivariate time series with Topological Data Analysis
Oct 10, 2020
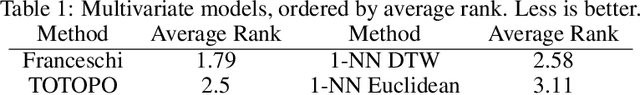
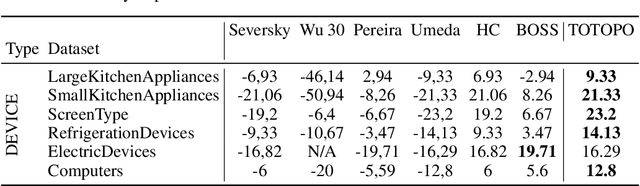
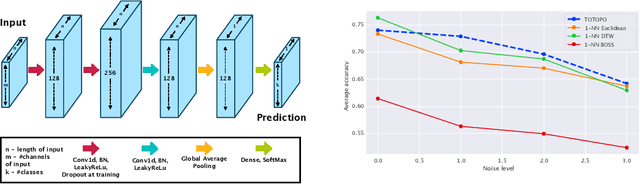
This work is devoted to a comprehensive analysis of topological data analysis fortime series classification. Previous works have significant shortcomings, such aslack of large-scale benchmarking or missing state-of-the-art methods. In this work,we propose TOTOPO for extracting topological descriptors from different types ofpersistence diagrams. The results suggest that TOTOPO significantly outperformsexisting baselines in terms of accuracy. TOTOPO is also competitive with thestate-of-the-art, being the best on 20% of univariate and 40% of multivariate timeseries datasets. This work validates the hypothesis that TDA-based approaches arerobust to small perturbations in data and are useful for cases where periodicity andshape help discriminate between classes.
Topology-based Clusterwise Regression for User Segmentation and Demand Forecasting
Sep 08, 2020
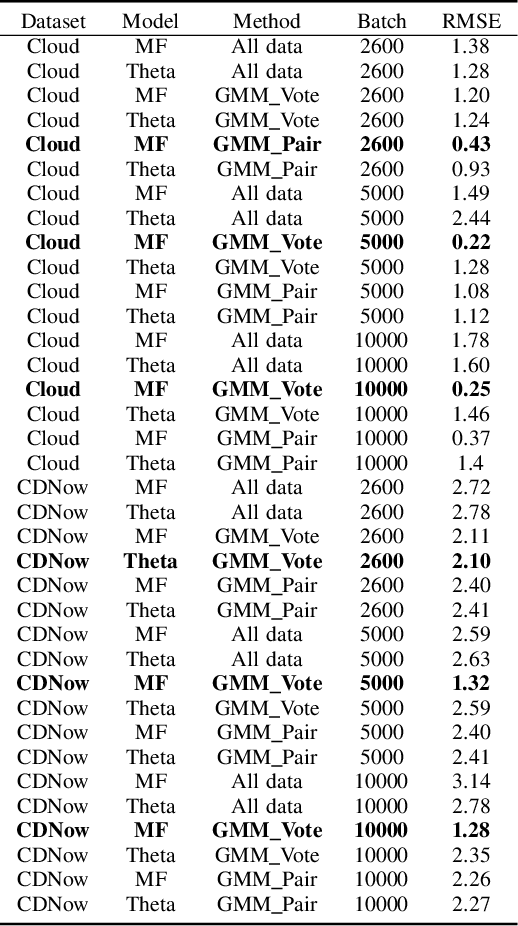

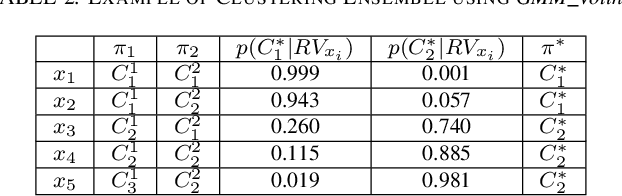
Topological Data Analysis (TDA) is a recent approach to analyze data sets from the perspective of their topological structure. Its use for time series data has been limited. In this work, a system developed for a leading provider of cloud computing combining both user segmentation and demand forecasting is presented. It consists of a TDA-based clustering method for time series inspired by a popular managerial framework for customer segmentation and extended to the case of clusterwise regression using matrix factorization methods to forecast demand. Increasing customer loyalty and producing accurate forecasts remain active topics of discussion both for researchers and managers. Using a public and a novel proprietary data set of commercial data, this research shows that the proposed system enables analysts to both cluster their user base and plan demand at a granular level with significantly higher accuracy than a state of the art baseline. This work thus seeks to introduce TDA-based clustering of time series and clusterwise regression with matrix factorization methods as viable tools for the practitioner.
Addressing Cold Start in Recommender Systems with Hierarchical Graph Neural Networks
Sep 07, 2020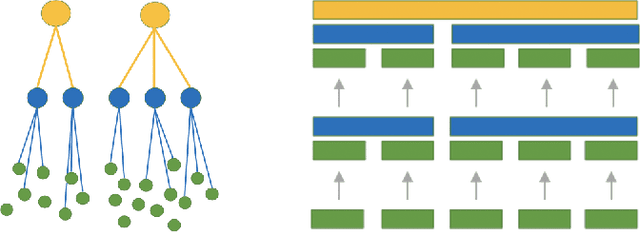
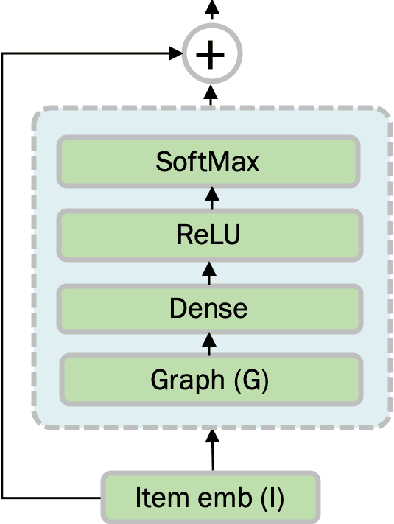
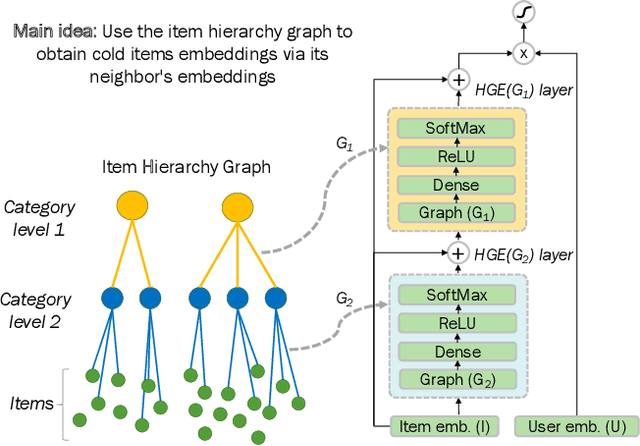
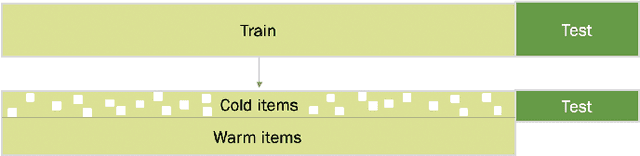
Recommender systems have become an essential instrument in a wide range of industries to personalize the user experience. A significant issue that has captured both researchers' and industry experts' attention is the cold start problem for new items. In this work, we present a graph neural network recommender system using item hierarchy graphs and a bespoke architecture to handle the cold start case for items. The experimental study on multiple datasets and millions of users and interactions indicates that our method achieves better forecasting quality than the state-of-the-art with a comparable computational time.
Topological Data Analysis for Portfolio Management of Cryptocurrencies
Sep 07, 2020


Portfolio management is essential for any investment decision. Yet, traditional methods in the literature are ill-suited for the characteristics and dynamics of cryptocurrencies. This work presents a method to build an investment portfolio consisting of more than 1500 cryptocurrencies covering 6 years of market data. It is centred around Topological Data Analysis (TDA), a recent approach to analyze data sets from the perspective of their topological structure. This publication proposes a system combining persistence landscapes to identify suitable investment opportunities in cryptocurrencies. Using a novel and comprehensive data set of cryptocurrency prices, this research shows that the proposed system enables analysts to outperform a classic method from the literature without requiring any feature engineering or domain knowledge in TDA. This work thus introduces TDA-based portfolio management of cryptocurrencies as a viable tool for the practitioner.
DeepFolio: Convolutional Neural Networks for Portfolios with Limit Order Book Data
Aug 27, 2020
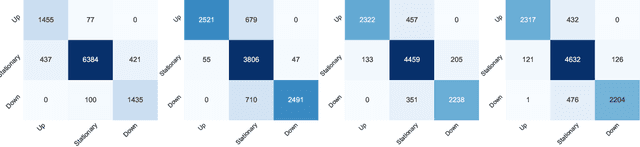
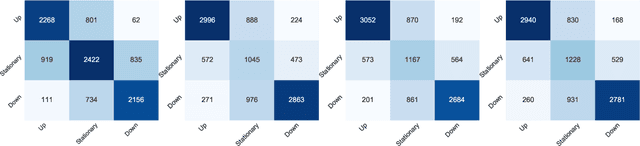
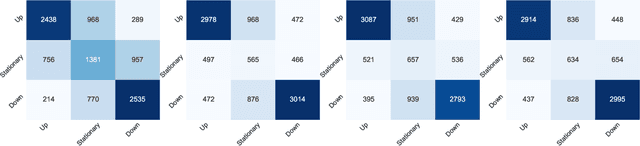
This work proposes DeepFolio, a new model for deep portfolio management based on data from limit order books (LOB). DeepFolio solves problems found in the state-of-the-art for LOB data to predict price movements. Our evaluation consists of two scenarios using a large dataset of millions of time series. The improvements deliver superior results both in cases of abundant as well as scarce data. The experiments show that DeepFolio outperforms the state-of-the-art on the benchmark FI-2010 LOB. Further, we use DeepFolio for optimal portfolio allocation of crypto-assets with rebalancing. For this purpose, we use two loss-functions - Sharpe ratio loss and minimum volatility risk. We show that DeepFolio outperforms widely used portfolio allocation techniques in the literature.
Topological Data Analysis of Time Series Data for B2B Customer Relationshop Management
May 26, 2019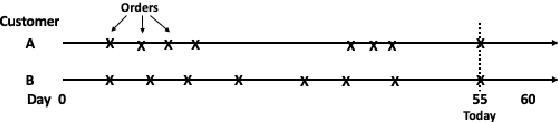
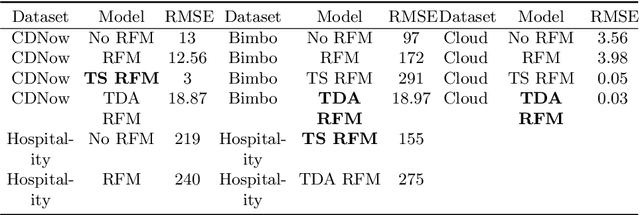
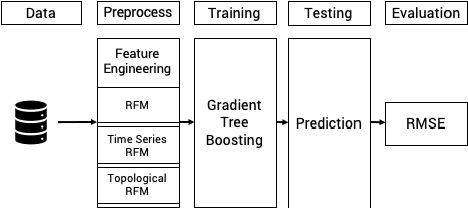
Topological Data Analysis (TDA) is a recent approach to analyze data sets from the perspective of their topological structure. Its use for time series data has been limited to the field of financial time series primarily and as a method for feature generation in machine learning applications. In this work, TDA is presented as a technique to gain additional understanding of the customers' loyalty for business-to-business customer relationship management. Increasing loyalty and strengthening relationships with key accounts remain an active topic of discussion both for researchers and managers. Using two public and two proprietary data sets of commercial data, this research shows that the technique enables analysts to better understand their customer base and identify prospective opportunities. In addition, the approach can be used as a clustering method to increase the accuracy of a predictive model for loyalty scoring. This work thus seeks to introduce TDA as a viable tool for data analysis to the quantitate marketing practitioner.
* 9 pages, 2 figures, 1 table
Demand forecasting techniques for build-to-order lean manufacturing supply chains
May 20, 2019
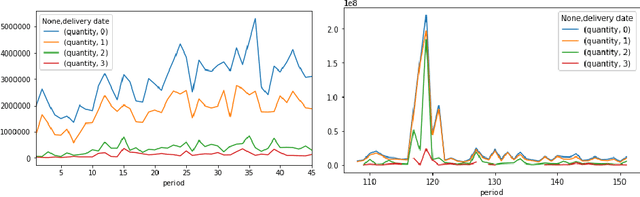
Build-to-order (BTO) supply chains have become common-place in industries such as electronics, automotive and fashion. They enable building products based on individual requirements with a short lead time and minimum inventory and production costs. Due to their nature, they differ significantly from traditional supply chains. However, there have not been studies dedicated to demand forecasting methods for this type of setting. This work makes two contributions. First, it presents a new and unique data set from a manufacturer in the BTO sector. Second, it proposes a novel data transformation technique for demand forecasting of BTO products. Results from thirteen forecasting methods show that the approach compares well to the state-of-the-art while being easy to implement and to explain to decision-makers.
* 10 pages, 2 figures