 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Variability to Stability: Advancing RecSys Benchmarking Practices
Feb 15, 2024In the rapidly evolving domain of Recommender Systems (RecSys), new algorithms frequently claim state-of-the-art performance based on evaluations over a limited set of arbitrarily selected datasets. However, this approach may fail to holistically reflect their effectiveness due to the significant impact of dataset characteristics on algorithm performance. Addressing this deficiency, this paper introduces a novel benchmarking methodology to facilitate a fair and robust comparison of RecSys algorithms, thereby advancing evaluation practices. By utilizing a diverse set of $30$ open datasets, including two introduced in this work, and evaluating $11$ collaborative filtering algorithms across $9$ metrics, we critically examine the influence of dataset characteristics on algorithm performance. We further investigate the feasibility of aggregating outcomes from multiple datasets into a unified ranking. Through rigorous experimental analysis, we validate the reliability of our methodology under the variability of datasets, offering a benchmarking strategy that balances quality and computational demands. This methodology enables a fair yet effective means of evaluating RecSys algorithms, providing valuable guidance for future research endeavors.
Continuous-time convolutions model of event sequences
Feb 13, 2023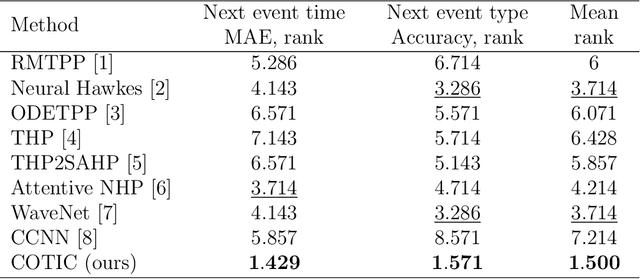
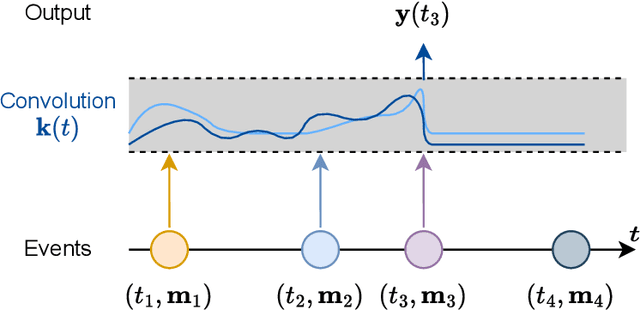
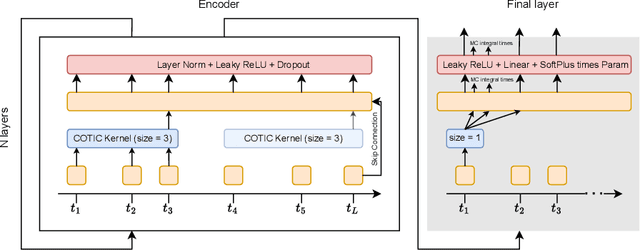

Massive samples of event sequences data occur in various domains, including e-commerce, healthcare, and finance. There are two main challenges regarding inference of such data: computational and methodological. The amount of available data and the length of event sequences per client are typically large, thus it requires long-term modelling. Moreover, this data is often sparse and non-uniform, making classic approaches for time series processing inapplicable. Existing solutions include recurrent and transformer architectures in such cases. To allow continuous time, the authors introduce specific parametric intensity functions defined at each moment on top of existing models. Due to the parametric nature, these intensities represent only a limited class of event sequences. We propose the COTIC method based on a continuous convolution neural network suitable for non-uniform occurrence of events in time. In COTIC, dilations and multi-layer architecture efficiently handle dependencies between events. Furthermore, the model provides general intensity dynamics in continuous time - including self-excitement encountered in practice. The COTIC model outperforms existing approaches on majority of the considered datasets, producing embeddings for an event sequence that can be used to solve downstream tasks - e.g. predicting next event type and return time. The code of the proposed method can be found in the GitHub repository (https://github.com/VladislavZh/COTIC).
Uncertainty estimation for time series forecasting via Gaussian process regression surrogates
Feb 06, 2023Machine learning models are widely used to solve real-world problems in science and industry. To build robust models, we should quantify the uncertainty of the model's predictions on new data. This study proposes a new method for uncertainty estimation based on the surrogate Gaussian process model. Our method can equip any base model with an accurate uncertainty estimate produced by a separate surrogate. Compared to other approaches, the estimate remains computationally effective with training only one additional model and doesn't rely on data-specific assumptions. The only requirement is the availability of the base model as a black box, which is typical. Experiments for challenging time-series forecasting data show that surrogate model-based methods provide more accurate confidence intervals than bootstrap-based methods in both medium and small-data regimes and different families of base models, including linear regression, ARIMA, and gradient boosting.