 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Variability to Stability: Advancing RecSys Benchmarking Practices
Feb 15, 2024In the rapidly evolving domain of Recommender Systems (RecSys), new algorithms frequently claim state-of-the-art performance based on evaluations over a limited set of arbitrarily selected datasets. However, this approach may fail to holistically reflect their effectiveness due to the significant impact of dataset characteristics on algorithm performance. Addressing this deficiency, this paper introduces a novel benchmarking methodology to facilitate a fair and robust comparison of RecSys algorithms, thereby advancing evaluation practices. By utilizing a diverse set of $30$ open datasets, including two introduced in this work, and evaluating $11$ collaborative filtering algorithms across $9$ metrics, we critically examine the influence of dataset characteristics on algorithm performance. We further investigate the feasibility of aggregating outcomes from multiple datasets into a unified ranking. Through rigorous experimental analysis, we validate the reliability of our methodology under the variability of datasets, offering a benchmarking strategy that balances quality and computational demands. This methodology enables a fair yet effective means of evaluating RecSys algorithms, providing valuable guidance for future research endeavors.
Logistics, Graphs, and Transformers: Towards improving Travel Time Estimation
Jul 12, 2022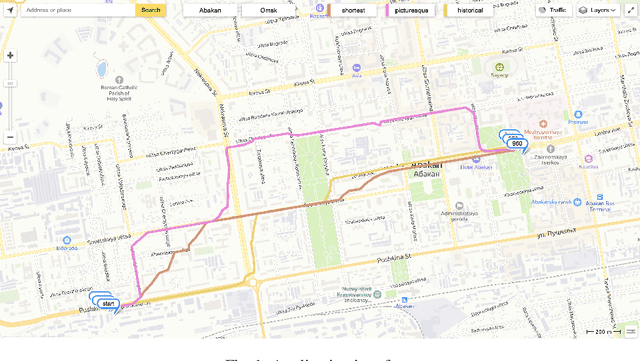
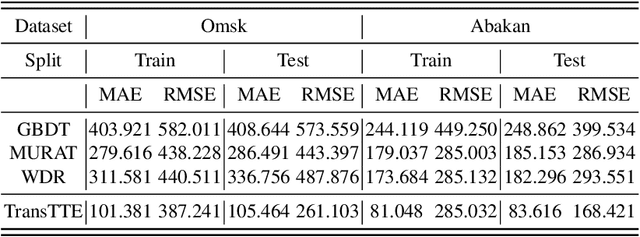
The problem of travel time estimation is widely considered as the fundamental challenge of modern logistics. The complex nature of interconnections between spatial aspects of roads and temporal dynamics of ground transport still preserves an area to experiment with. However, the total volume of currently accumulated data encourages the construction of the learning models which have the perspective to significantly outperform earlier solutions. In order to address the problems of travel time estimation, we propose a new method based on transformer architecture - TransTTE.
Citation network applications in a scientific co-authorship recommender system
Nov 22, 2021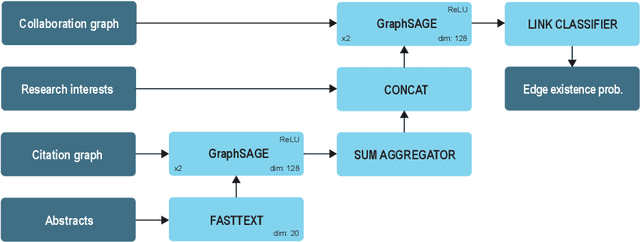
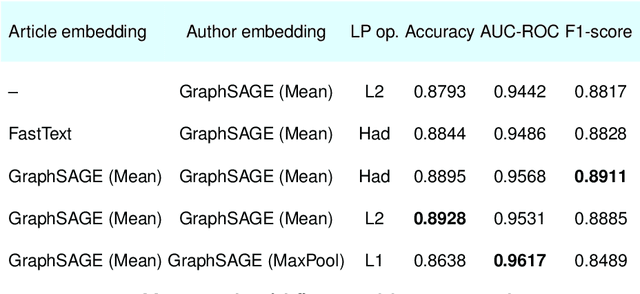
The problem of co-authors selection in the area of scientific collaborations might be a daunting one. In this paper, we propose a new pipeline that effectively utilizes citation data in the link prediction task on the co-authorship network. In particular, we explore the capabilities of a recommender system based on data aggregation strategies on different graphs. Since graph neural networks proved their efficiency on a wide range of tasks related to recommendation systems, we leverage them as a relevant method for the forecasting of potential collaborations in the scientific community.