 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePINE: Pipeline for Important Node Exploration in Attributed Networks
Dec 08, 2025
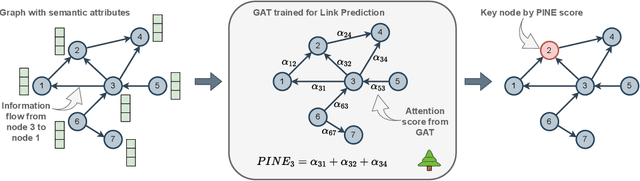
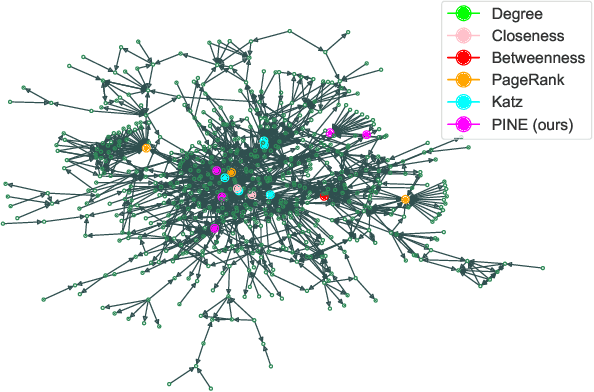
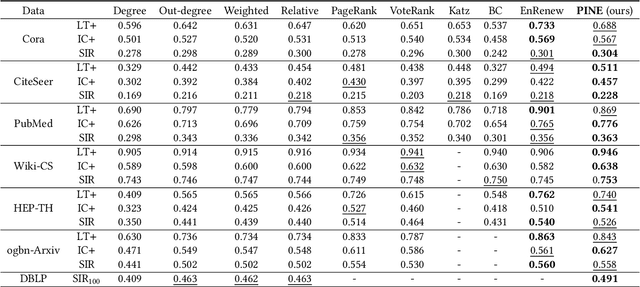
A graph with semantically attributed nodes are a common data structure in a wide range of domains. It could be interlinked web data or citation networks of scientific publications. The essential problem for such a data type is to determine nodes that carry greater importance than all the others, a task that markedly enhances system monitoring and management. Traditional methods to identify important nodes in networks introduce centrality measures, such as node degree or more complex PageRank. However, they consider only the network structure, neglecting the rich node attributes. Recent methods adopt neural networks capable of handling node features, but they require supervision. This work addresses the identified gap--the absence of approaches that are both unsupervised and attribute-aware--by introducing a Pipeline for Important Node Exploration (PINE). At the core of the proposed framework is an attention-based graph model that incorporates node semantic features in the learning process of identifying the structural graph properties. The PINE's node importance scores leverage the obtained attention distribution. We demonstrate the superior performance of the proposed PINE method on various homogeneous and heterogeneous attributed networks. As an industry-implemented system, PINE tackles the real-world challenge of unsupervised identification of key entities within large-scale enterprise graphs.
From Variability to Stability: Advancing RecSys Benchmarking Practices
Feb 15, 2024In the rapidly evolving domain of Recommender Systems (RecSys), new algorithms frequently claim state-of-the-art performance based on evaluations over a limited set of arbitrarily selected datasets. However, this approach may fail to holistically reflect their effectiveness due to the significant impact of dataset characteristics on algorithm performance. Addressing this deficiency, this paper introduces a novel benchmarking methodology to facilitate a fair and robust comparison of RecSys algorithms, thereby advancing evaluation practices. By utilizing a diverse set of $30$ open datasets, including two introduced in this work, and evaluating $11$ collaborative filtering algorithms across $9$ metrics, we critically examine the influence of dataset characteristics on algorithm performance. We further investigate the feasibility of aggregating outcomes from multiple datasets into a unified ranking. Through rigorous experimental analysis, we validate the reliability of our methodology under the variability of datasets, offering a benchmarking strategy that balances quality and computational demands. This methodology enables a fair yet effective means of evaluating RecSys algorithms, providing valuable guidance for future research endeavors.
Revising deep learning methods in parking lot occupancy detection
Jun 08, 2023Parking guidance systems have recently become a popular trend as a part of the smart cities' paradigm of development. The crucial part of such systems is the algorithm allowing drivers to search for available parking lots across regions of interest. The classic approach to this task is based on the application of neural network classifiers to camera records. However, existing systems demonstrate a lack of generalization ability and appropriate testing regarding specific visual conditions. In this study, we extensively evaluate state-of-the-art parking lot occupancy detection algorithms, compare their prediction quality with the recently emerged vision transformers, and propose a new pipeline based on EfficientNet architecture. Performed computational experiments have demonstrated the performance increase in the case of our model, which was evaluated on 5 different datasets.
GCT-TTE: Graph Convolutional Transformer for Travel Time Estimation
Jun 07, 2023This paper introduces a new transformer-based model for the problem of travel time estimation. The key feature of the proposed GCT-TTE architecture is the utilization of different data modalities capturing different properties of an input path. Along with the extensive study regarding the model configuration, we implemented and evaluated a sufficient number of actual baselines for path-aware and path-blind settings. The conducted computational experiments have confirmed the viability of our pipeline, which outperformed state-of-the-art models on both considered datasets. Additionally, GCT-TTE was deployed as a web service accessible for further experiments with user-defined routes.
Transformer-based classification of premise in tweets related to COVID-19
Sep 08, 2022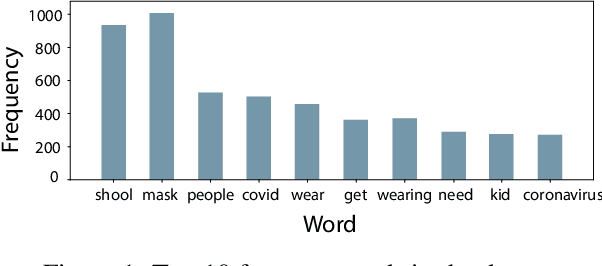
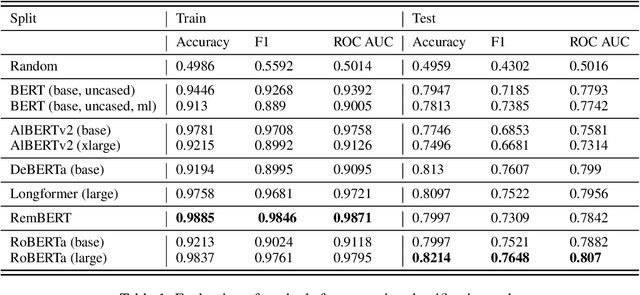
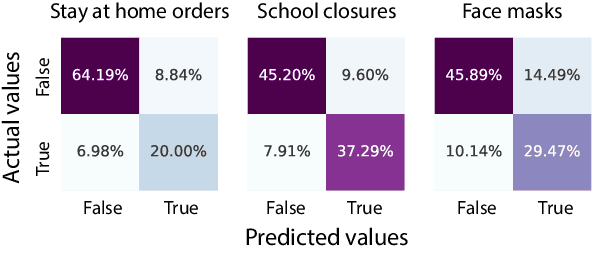
Automation of social network data assessment is one of the classic challenges of natural language processing. During the COVID-19 pandemic, mining people's stances from public messages have become crucial regarding understanding attitudes towards health orders. In this paper, the authors propose the predictive model based on transformer architecture to classify the presence of premise in Twitter texts. This work is completed as part of the Social Media Mining for Health (SMM4H) Workshop 2022. We explored modern transformer-based classifiers in order to construct the pipeline efficiently capturing tweets semantics. Our experiments on a Twitter dataset showed that RoBERTa is superior to the other transformer models in the case of the premise prediction task. The model achieved competitive performance with respect to ROC AUC value 0.807, and 0.7648 for the F1 score.
Logistics, Graphs, and Transformers: Towards improving Travel Time Estimation
Jul 12, 2022
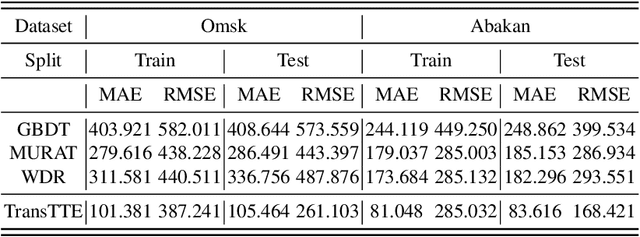
The problem of travel time estimation is widely considered as the fundamental challenge of modern logistics. The complex nature of interconnections between spatial aspects of roads and temporal dynamics of ground transport still preserves an area to experiment with. However, the total volume of currently accumulated data encourages the construction of the learning models which have the perspective to significantly outperform earlier solutions. In order to address the problems of travel time estimation, we propose a new method based on transformer architecture - TransTTE.
Many Heads but One Brain: an Overview of Fusion Brain Challenge on AI Journey 2021
Nov 22, 2021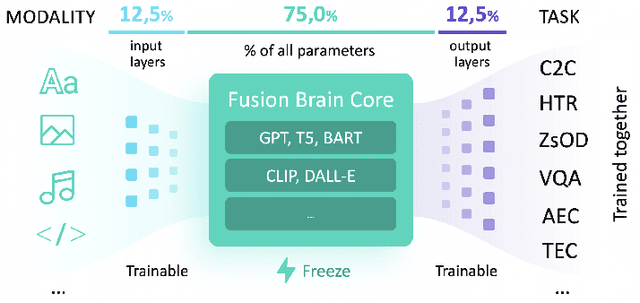
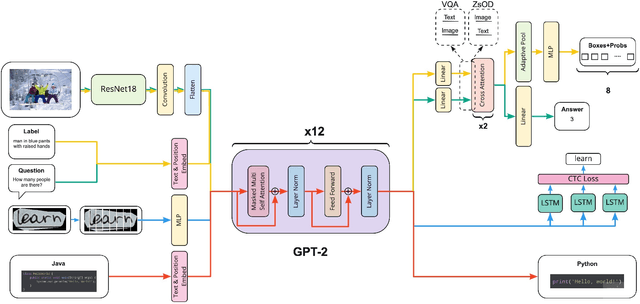
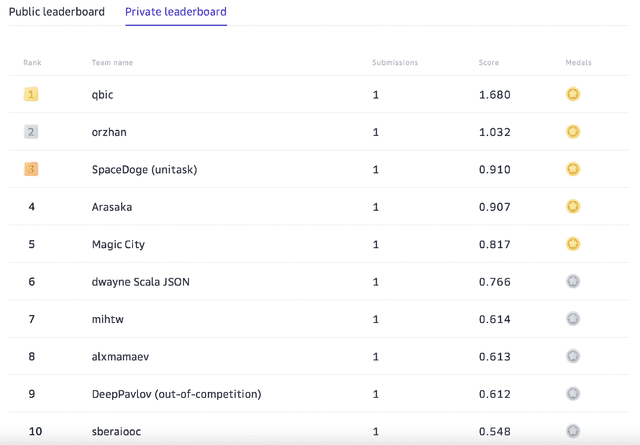
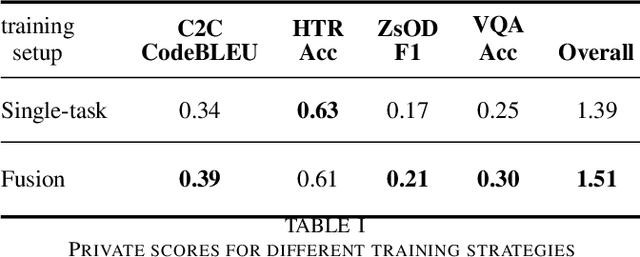
Supporting the current trend in the AI community, we propose the AI Journey 2021 Challenge called Fusion Brain which is targeted to make the universal architecture process different modalities (namely, images, texts, and code) and to solve multiple tasks for vision and language. The Fusion Brain Challenge https://github.com/sberbank-ai/fusion_brain_aij2021 combines the following specific tasks: Code2code Translation, Handwritten Text recognition, Zero-shot Object Detection, and Visual Question Answering. We have created datasets for each task to test the participants' submissions on it. Moreover, we have opened a new handwritten dataset in both Russian and English, which consists of 94,130 pairs of images and texts. The Russian part of the dataset is the largest Russian handwritten dataset in the world. We also propose the baseline solution and corresponding task-specific solutions as well as overall metrics.
Hybrid Graph Embedding Techniques in Estimated Time of Arrival Task
Oct 08, 2021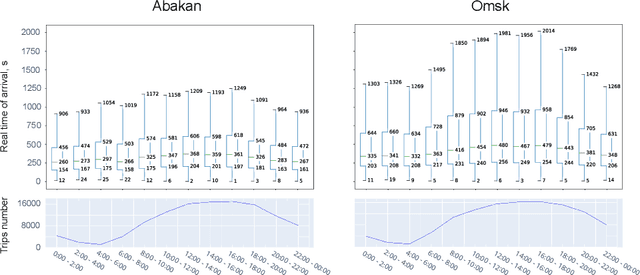
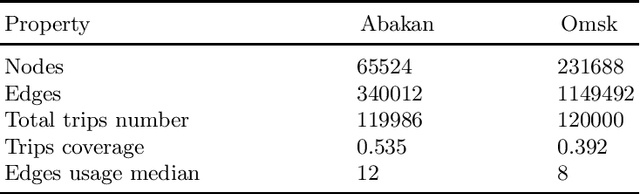
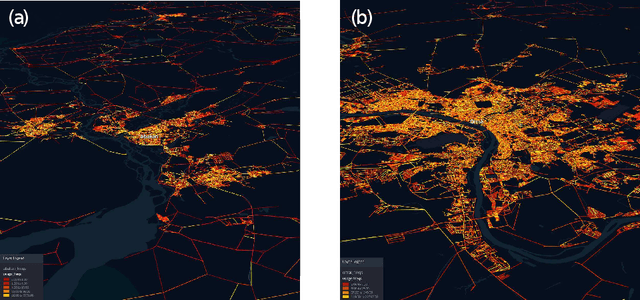
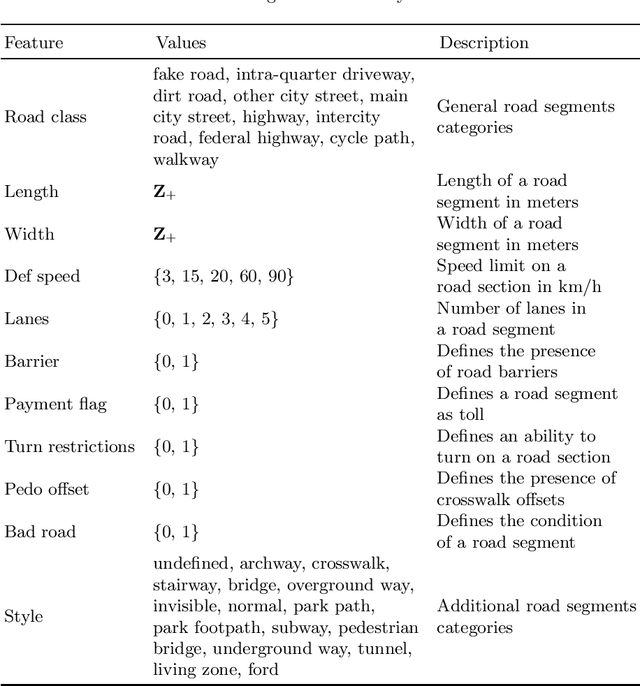
Recently, deep learning has achieved promising results in the calculation of Estimated Time of Arrival (ETA), which is considered as predicting the travel time from the start point to a certain place along a given path. ETA plays an essential role in intelligent taxi services or automotive navigation systems. A common practice is to use embedding vectors to represent the elements of a road network, such as road segments and crossroads. Road elements have their own attributes like length, presence of crosswalks, lanes number, etc. However, many links in the road network are traversed by too few floating cars even in large ride-hailing platforms and affected by the wide range of temporal events. As the primary goal of the research, we explore the generalization ability of different spatial embedding strategies and propose a two-stage approach to deal with such problems.