 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdditive regularization schedule for neural architecture search
Jun 18, 2024Neural network structures have a critical impact on the accuracy and stability of forecasting. Neural architecture search procedures help design an optimal neural network according to some loss function, which represents a set of quality criteria. This paper investigates the problem of neural network structure optimization. It proposes a way to construct a loss function, which contains a set of additive elements. Each element is called the regularizer. It corresponds to some part of the neural network structure and represents a criterion to optimize. The optimization procedure changes the structure in iterations. To optimize various parts of the structure, the procedure changes the set of regularizers according to some schedule. The authors propose a way to construct the additive regularization schedule. By comparing regularized models with non-regularized ones for a collection of datasets the computational experiments show that the proposed method finds efficient neural network structure and delivers accurate networks of low complexity.
Startup success prediction and VC portfolio simulation using CrunchBase data
Sep 27, 2023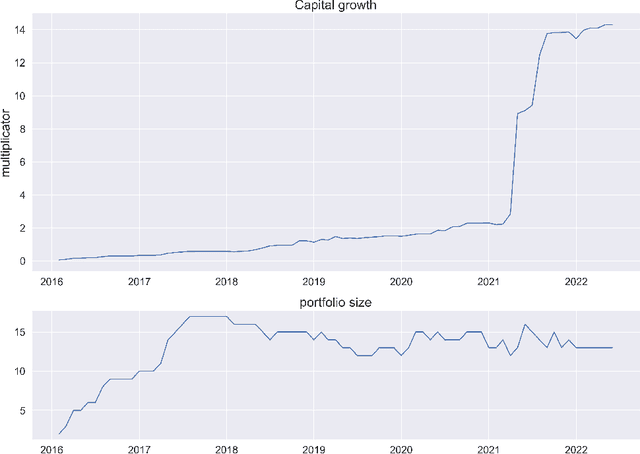
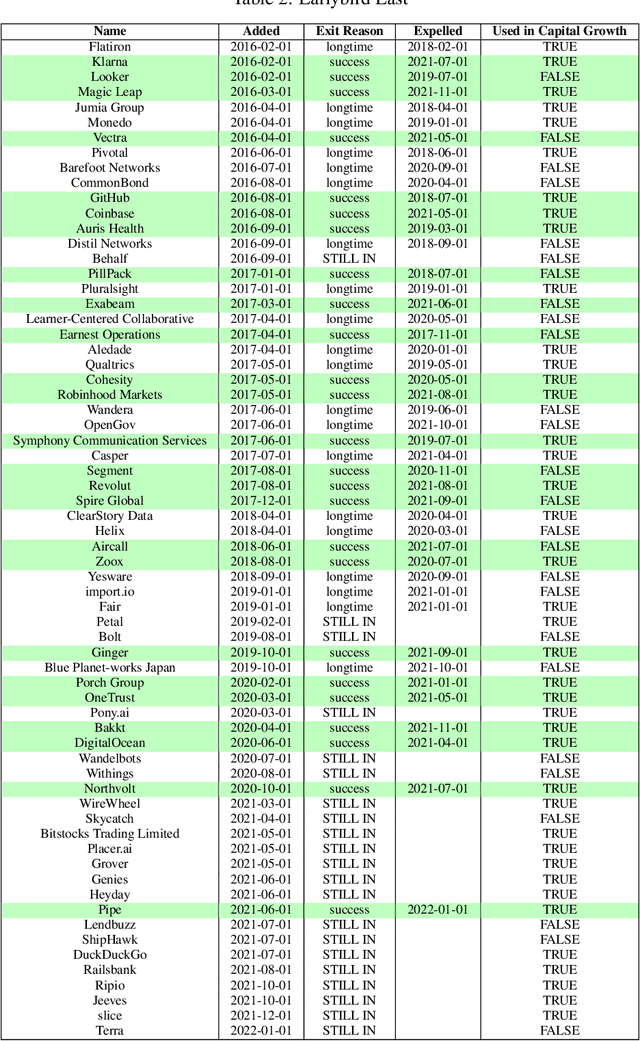
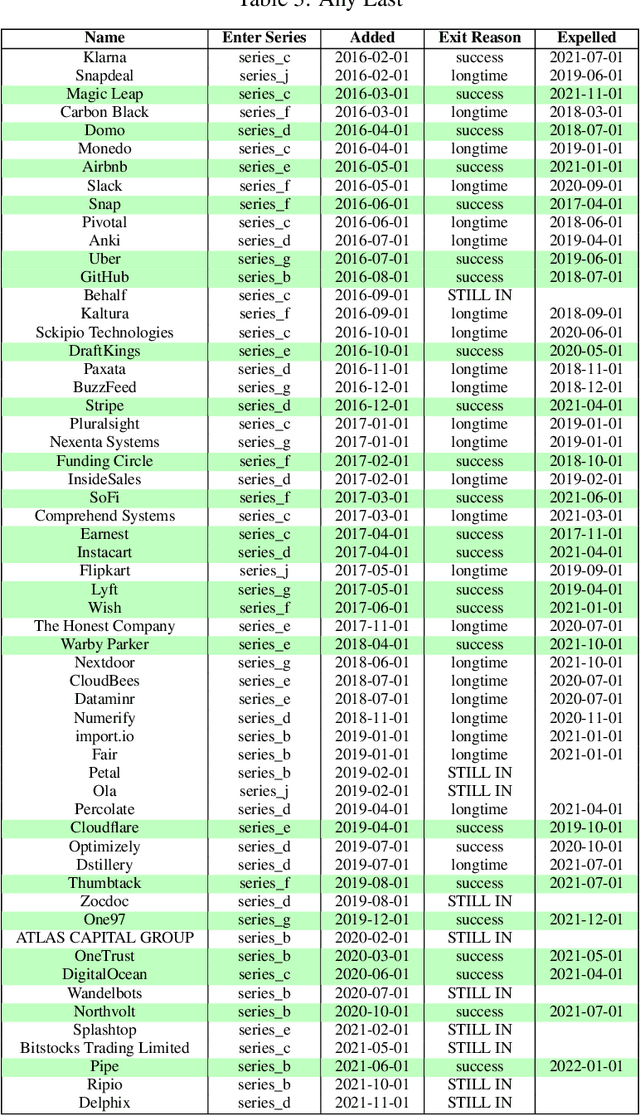
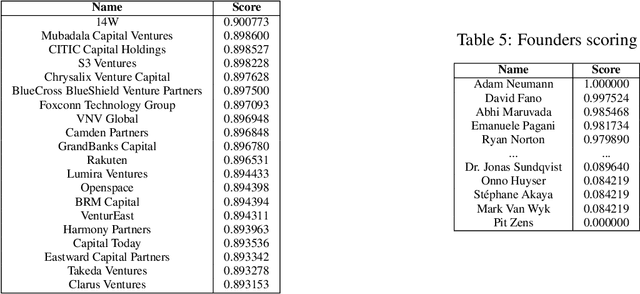
Predicting startup success presents a formidable challenge due to the inherently volatile landscape of the entrepreneurial ecosystem. The advent of extensive databases like Crunchbase jointly with available open data enables the application of machine learning and artificial intelligence for more accurate predictive analytics. This paper focuses on startups at their Series B and Series C investment stages, aiming to predict key success milestones such as achieving an Initial Public Offering (IPO), attaining unicorn status, or executing a successful Merger and Acquisition (M\&A). We introduce novel deep learning model for predicting startup success, integrating a variety of factors such as funding metrics, founder features, industry category. A distinctive feature of our research is the use of a comprehensive backtesting algorithm designed to simulate the venture capital investment process. This simulation allows for a robust evaluation of our model's performance against historical data, providing actionable insights into its practical utility in real-world investment contexts. Evaluating our model on Crunchbase's, we achieved a 14 times capital growth and successfully identified on B round high-potential startups including Revolut, DigitalOcean, Klarna, Github and others. Our empirical findings illuminate the importance of incorporating diverse feature sets in enhancing the model's predictive accuracy. In summary, our work demonstrates the considerable promise of deep learning models and alternative unstructured data in predicting startup success and sets the stage for future advancements in this research area.
Handwritten text generation and strikethrough characters augmentation
Dec 14, 2021

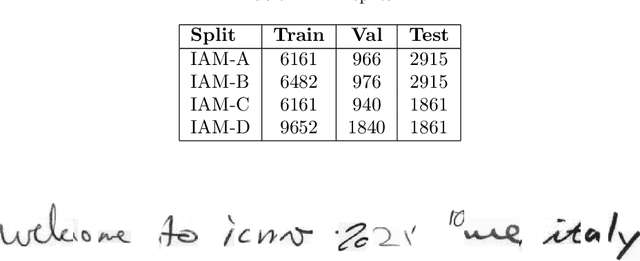
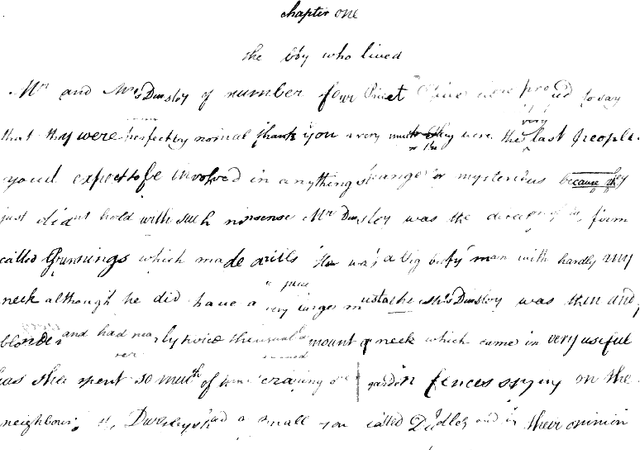
We introduce two data augmentation techniques, which, used with a Resnet-BiLSTM-CTC network, significantly reduce Word Error Rate (WER) and Character Error Rate (CER) beyond best-reported results on handwriting text recognition (HTR) tasks. We apply a novel augmentation that simulates strikethrough text (HandWritten Blots) and a handwritten text generation method based on printed text (StackMix), which proved to be very effective in HTR tasks. StackMix uses weakly-supervised framework to get character boundaries. Because these data augmentation techniques are independent of the network used, they could also be applied to enhance the performance of other networks and approaches to HTR. Extensive experiments on ten handwritten text datasets show that HandWritten Blots augmentation and StackMix significantly improve the quality of HTR models
Many Heads but One Brain: an Overview of Fusion Brain Challenge on AI Journey 2021
Nov 22, 2021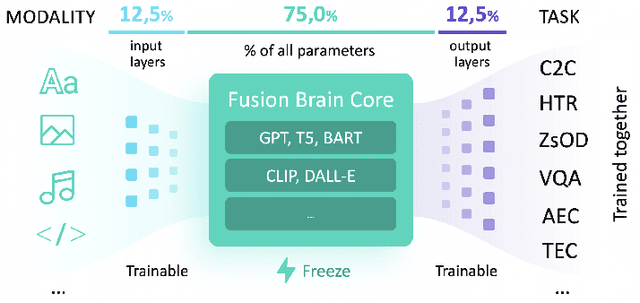
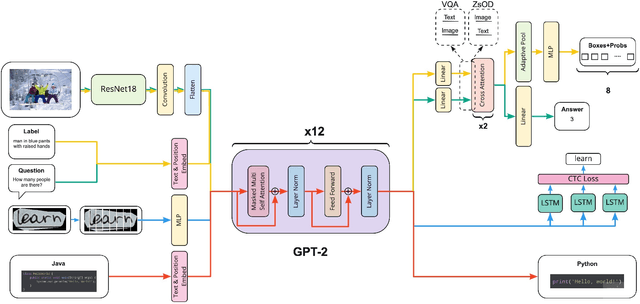
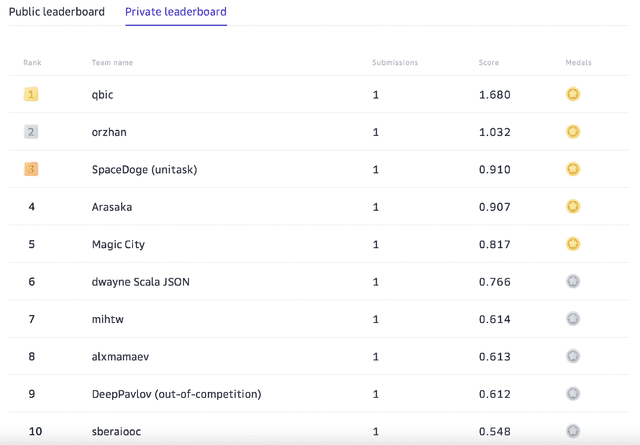
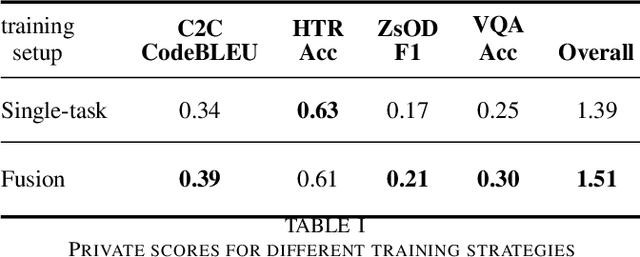
Supporting the current trend in the AI community, we propose the AI Journey 2021 Challenge called Fusion Brain which is targeted to make the universal architecture process different modalities (namely, images, texts, and code) and to solve multiple tasks for vision and language. The Fusion Brain Challenge https://github.com/sberbank-ai/fusion_brain_aij2021 combines the following specific tasks: Code2code Translation, Handwritten Text recognition, Zero-shot Object Detection, and Visual Question Answering. We have created datasets for each task to test the participants' submissions on it. Moreover, we have opened a new handwritten dataset in both Russian and English, which consists of 94,130 pairs of images and texts. The Russian part of the dataset is the largest Russian handwritten dataset in the world. We also propose the baseline solution and corresponding task-specific solutions as well as overall metrics.
StackMix and Blot Augmentations for Handwritten Text Recognition
Aug 26, 2021


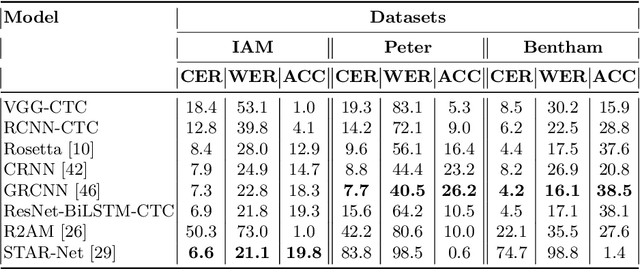
This paper proposes a handwritten text recognition(HTR) system that outperforms current state-of-the-artmethods. The comparison was carried out on three of themost frequently used in HTR task datasets, namely Ben-tham, IAM, and Saint Gall. In addition, the results on tworecently presented datasets, Peter the Greats manuscriptsand HKR Dataset, are provided.The paper describes the architecture of the neural net-work and two ways of increasing the volume of train-ing data: augmentation that simulates strikethrough text(HandWritten Blots) and a new text generation method(StackMix), which proved to be very effective in HTR tasks.StackMix can also be applied to the standalone task of gen-erating handwritten text based on printed text.
Digital Peter: Dataset, Competition and Handwriting Recognition Methods
Mar 16, 2021


This paper presents a new dataset of Peter the Great's manuscripts and describes a segmentation procedure that converts initial images of documents into the lines. The new dataset may be useful for researchers to train handwriting text recognition models as a benchmark for comparing different models. It consists of 9 694 images and text files corresponding to lines in historical documents. The open machine learning competition Digital Peter was held based on the considered dataset. The baseline solution for this competition as well as more advanced methods on handwritten text recognition are described in the article. Full dataset and all code are publicly available.