 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitti: Designing Scale-Wise Transformers for Text-to-Image Synthesis
Dec 03, 2024This work presents Switti, a scale-wise transformer for text-to-image generation. Starting from existing next-scale prediction AR models, we first explore them for T2I generation and propose architectural modifications to improve their convergence and overall performance. We then observe that self-attention maps of our pretrained scale-wise AR model exhibit weak dependence on preceding scales. Based on this insight, we propose a non-AR counterpart facilitating ~11% faster sampling and lower memory usage while also achieving slightly better generation quality. Furthermore, we reveal that classifier-free guidance at high-resolution scales is often unnecessary and can even degrade performance. By disabling guidance at these scales, we achieve an additional sampling acceleration of ~20% and improve the generation of fine-grained details. Extensive human preference studies and automated evaluations show that Switti outperforms existing T2I AR models and competes with state-of-the-art T2I diffusion models while being up to 7 times faster.
Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Aug 31, 2024Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.
Mind Your Format: Towards Consistent Evaluation of In-Context Learning Improvements
Jan 22, 2024Large language models demonstrate a remarkable capability for learning to solve new tasks from a few examples. The prompt template, or the way the input examples are formatted to obtain the prompt, is an important yet often overlooked aspect of in-context learning. In this work, we conduct a comprehensive study of the template format's influence on the in-context learning performance. We evaluate the impact of the prompt template across models (from 770M to 70B parameters) and 4 standard classification datasets. We show that a poor choice of the template can reduce the performance of the strongest models and inference methods to a random guess level. More importantly, the best templates do not transfer between different setups and even between models of the same family. Our findings show that the currently prevalent approach to evaluation, which ignores template selection, may give misleading results due to different templates in different works. As a first step towards mitigating this issue, we propose Template Ensembles that aggregate model predictions across several templates. This simple test-time augmentation boosts average performance while being robust to the choice of random set of templates.
Is This Loss Informative? Speeding Up Textual Inversion with Deterministic Objective Evaluation
Feb 09, 2023Text-to-image generation models represent the next step of evolution in image synthesis, offering natural means of flexible yet fine-grained control over the result. One emerging area of research is the rapid adaptation of large text-to-image models to smaller datasets or new visual concepts. However, the most efficient method of adaptation, called textual inversion, has a known limitation of long training time, which both restricts practical applications and increases the experiment time for research. In this work, we study the training dynamics of textual inversion, aiming to speed it up. We observe that most concepts are learned at early stages and do not improve in quality later, but standard model convergence metrics fail to indicate that. Instead, we propose a simple early stopping criterion that only requires computing the textual inversion loss on the same inputs for all training iterations. Our experiments on both Latent Diffusion and Stable Diffusion models for 93 concepts demonstrate the competitive performance of our method, speeding adaptation up to 15 times with no significant drops in quality.
Learning to Solve Voxel Building Embodied Tasks from Pixels and Natural Language Instructions
Nov 01, 2022The adoption of pre-trained language models to generate action plans for embodied agents is a promising research strategy. However, execution of instructions in real or simulated environments requires verification of the feasibility of actions as well as their relevance to the completion of a goal. We propose a new method that combines a language model and reinforcement learning for the task of building objects in a Minecraft-like environment according to the natural language instructions. Our method first generates a set of consistently achievable sub-goals from the instructions and then completes associated sub-tasks with a pre-trained RL policy. The proposed method formed the RL baseline at the IGLU 2022 competition.
Many Heads but One Brain: an Overview of Fusion Brain Challenge on AI Journey 2021
Nov 22, 2021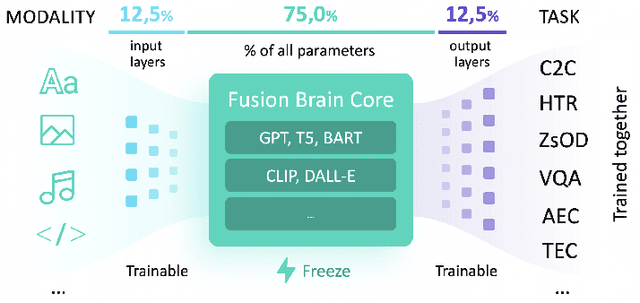
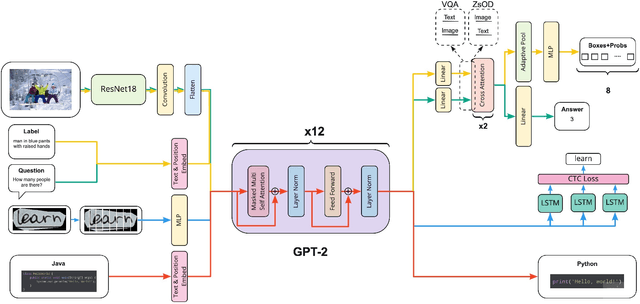
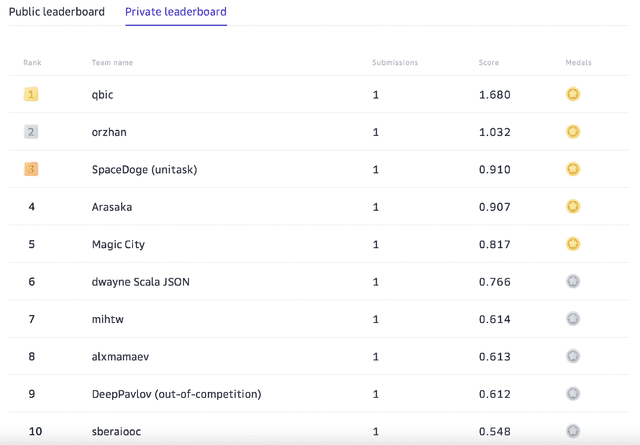
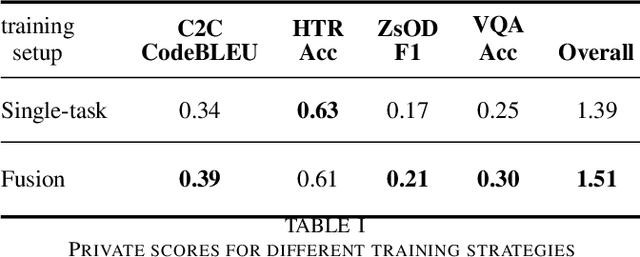
Supporting the current trend in the AI community, we propose the AI Journey 2021 Challenge called Fusion Brain which is targeted to make the universal architecture process different modalities (namely, images, texts, and code) and to solve multiple tasks for vision and language. The Fusion Brain Challenge https://github.com/sberbank-ai/fusion_brain_aij2021 combines the following specific tasks: Code2code Translation, Handwritten Text recognition, Zero-shot Object Detection, and Visual Question Answering. We have created datasets for each task to test the participants' submissions on it. Moreover, we have opened a new handwritten dataset in both Russian and English, which consists of 94,130 pairs of images and texts. The Russian part of the dataset is the largest Russian handwritten dataset in the world. We also propose the baseline solution and corresponding task-specific solutions as well as overall metrics.
Text Detoxification using Large Pre-trained Neural Models
Sep 18, 2021
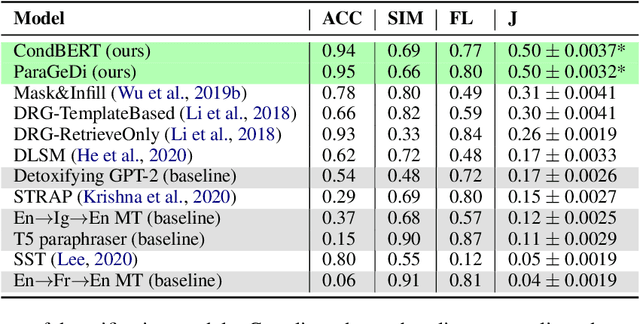
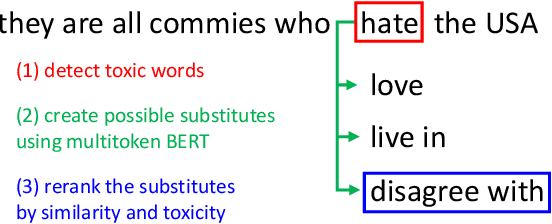

We present two novel unsupervised methods for eliminating toxicity in text. Our first method combines two recent ideas: (1) guidance of the generation process with small style-conditional language models and (2) use of paraphrasing models to perform style transfer. We use a well-performing paraphraser guided by style-trained language models to keep the text content and remove toxicity. Our second method uses BERT to replace toxic words with their non-offensive synonyms. We make the method more flexible by enabling BERT to replace mask tokens with a variable number of words. Finally, we present the first large-scale comparative study of style transfer models on the task of toxicity removal. We compare our models with a number of methods for style transfer. The models are evaluated in a reference-free way using a combination of unsupervised style transfer metrics. Both methods we suggest yield new SOTA results.