 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric World Models Meet Monte Carlo Tree Search
Jan 10, 2026In this paper, we introduce ObjectZero, a novel reinforcement learning (RL) algorithm that leverages the power of object-level representations to model dynamic environments more effectively. Unlike traditional approaches that process the world as a single undifferentiated input, our method employs Graph Neural Networks (GNNs) to capture intricate interactions among multiple objects. These objects, which can be manipulated and interact with each other, serve as the foundation for our model's understanding of the environment. We trained the algorithm in a complex setting teeming with diverse, interactive objects, demonstrating its ability to effectively learn and predict object dynamics. Our results highlight that a structured world model operating on object-centric representations can be successfully integrated into a model-based RL algorithm utilizing Monte Carlo Tree Search as a planning module.
CoRL-MPPI: Enhancing MPPI With Learnable Behaviours For Efficient And Provably-Safe Multi-Robot Collision Avoidance
Nov 12, 2025Decentralized collision avoidance remains a core challenge for scalable multi-robot systems. One of the promising approaches to tackle this problem is Model Predictive Path Integral (MPPI) -- a framework that is naturally suited to handle any robot motion model and provides strong theoretical guarantees. Still, in practice MPPI-based controller may provide suboptimal trajectories as its performance relies heavily on uninformed random sampling. In this work, we introduce CoRL-MPPI, a novel fusion of Cooperative Reinforcement Learning and MPPI to address this limitation. We train an action policy (approximated as deep neural network) in simulation that learns local cooperative collision avoidance behaviors. This learned policy is then embedded into the MPPI framework to guide its sampling distribution, biasing it towards more intelligent and cooperative actions. Notably, CoRL-MPPI preserves all the theoretical guarantees of regular MPPI. We evaluate our approach in dense, dynamic simulation environments against state-of-the-art baselines, including ORCA, BVC, and a multi-agent MPPI implementation. Our results demonstrate that CoRL-MPPI significantly improves navigation efficiency (measured by success rate and makespan) and safety, enabling agile and robust multi-robot navigation.
SGN-CIRL: Scene Graph-based Navigation with Curriculum, Imitation, and Reinforcement Learning
Jun 04, 2025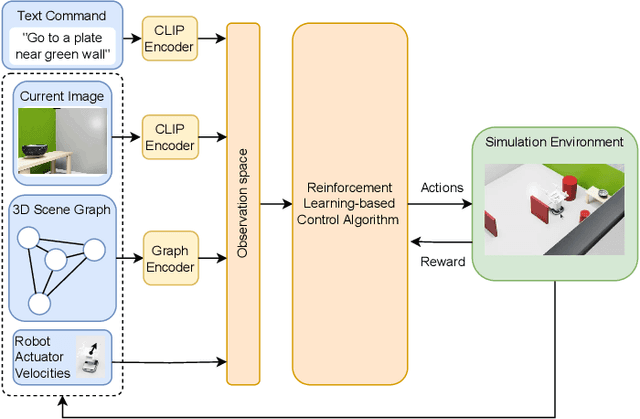
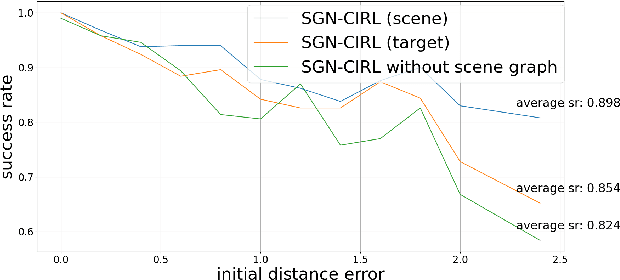

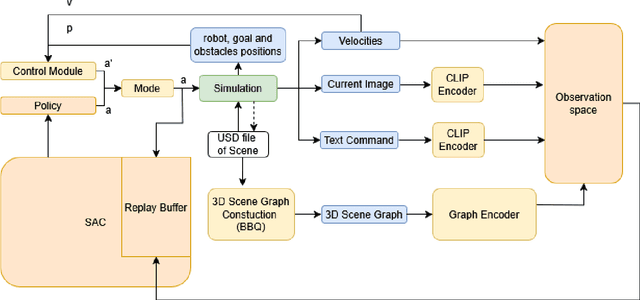
The 3D scene graph models spatial relationships between objects, enabling the agent to efficiently navigate in a partially observable environment and predict the location of the target object.This paper proposes an original framework named SGN-CIRL (3D Scene Graph-Based Reinforcement Learning Navigation) for mapless reinforcement learning-based robot navigation with learnable representation of open-vocabulary 3D scene graph. To accelerate and stabilize the training of reinforcement learning-based algorithms, the framework also employs imitation learning and curriculum learning. The first one enables the agent to learn from demonstrations, while the second one structures the training process by gradually increasing task complexity from simple to more advanced scenarios. Numerical experiments conducted in the Isaac Sim environment showed that using a 3D scene graph for reinforcement learning significantly increased the success rate in difficult navigation cases. The code is open-sourced and available at: https://github.com/Xisonik/Aloha\_graph.
TOCALib: Optimal control library with interpolation for bimanual manipulation and obstacles avoidance
Apr 10, 2025The paper presents a new approach for constructing a library of optimal trajectories for two robotic manipulators, Two-Arm Optimal Control and Avoidance Library (TOCALib). The optimisation takes into account kinodynamic and other constraints within the FROST framework. The novelty of the method lies in the consideration of collisions using the DCOL method, which allows obtaining symbolic expressions for assessing the presence of collisions and using them in gradient-based optimization control methods. The proposed approach allowed the implementation of complex bimanual manipulations. In this paper we used Mobile Aloha as an example of TOCALib application. The approach can be extended to other bimanual robots, as well as to gait control of bipedal robots. It can also be used to construct training data for machine learning tasks for manipulation.
Dynamic Neural Potential Field: Online Trajectory Optimization in Presence of Moving Obstacles
Oct 09, 2024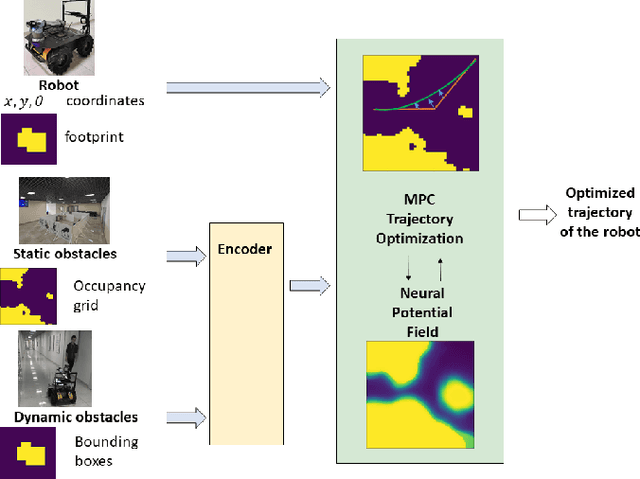
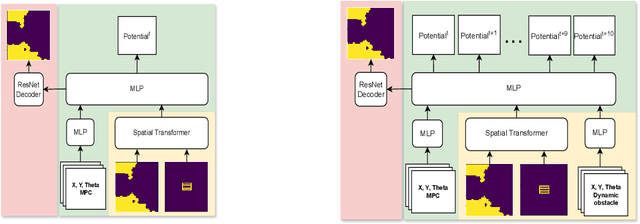
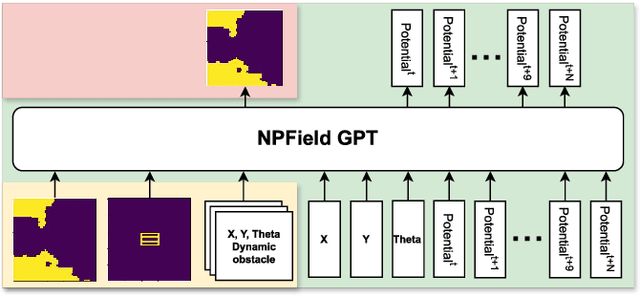
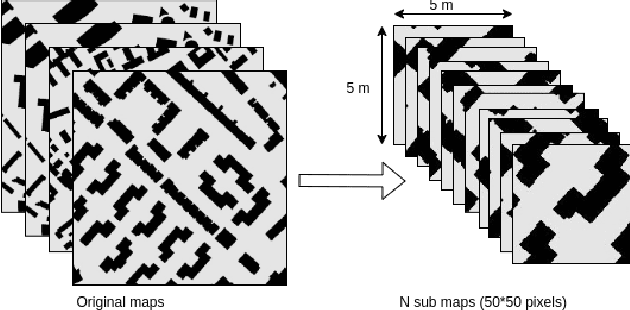
We address a task of local trajectory planning for the mobile robot in the presence of static and dynamic obstacles. Local trajectory is obtained as a numerical solution of the Model Predictive Control (MPC) problem. Collision avoidance may be provided by adding repulsive potential of the obstacles to the cost function of MPC. We develop an approach, where repulsive potential is estimated by the neural model. We propose and explore three possible strategies of handling dynamic obstacles. First, environment with dynamic obstacles is considered as a sequence of static environments. Second, the neural model predict a sequence of repulsive potential at once. Third, the neural model predict future repulsive potential step by step in autoregressive mode. We implement these strategies and compare it with CIAO* and MPPI using BenchMR framework. First two strategies showed higher performance than CIAO* and MPPI while preserving safety constraints. The third strategy was a bit slower, however it still satisfy time limits. We deploy our approach on Husky UGV mobile platform, which move through the office corridors under proposed MPC local trajectory planner. The code and trained models are available at \url{https://github.com/CognitiveAISystems/Dynamic-Neural-Potential-Field}.
Maneuver Decision-Making with Trajectory Streams Prediction for Autonomous Vehicles
Sep 16, 2024Decision-making, motion planning, and trajectory prediction are crucial in autonomous driving systems. By accurately forecasting the movements of other road users, the decision-making capabilities of the autonomous system can be enhanced, making it more effective in responding to dynamic and unpredictable environments and more adaptive to diverse road scenarios. This paper presents the FFStreams++ approach for decision-making and motion planning of different maneuvers, including unprotected left turn, overtaking, and keep-lane. FFStreams++ is a combination of sampling-based and search-based approaches, where iteratively new sampled trajectories for different maneuvers are generated and optimized, and afterward, a heuristic search planner is called, searching for an optimal plan. We model the autonomous diving system in the Planning Domain Definition Language (PDDL) and search for the optimal plan using a heuristic Fast-Forward planner. In this approach, the initial state of the problem is modified iteratively through streams, which will generate maneuver-specific trajectory candidates, increasing the iterating level until an optimal plan is found. FFStreams++ integrates a query-connected network model for predicting possible future trajectories for each surrounding obstacle along with their probabilities. The proposed approach was tested on the CommonRoad simulation framework. We use a collection of randomly generated driving scenarios for overtaking and unprotected left turns at intersections to evaluate the FFStreams++ planner. The test results confirmed that the proposed approach can effectively execute various maneuvers to ensure safety and reduce the risk of collisions with nearby traffic agents.
MAPF-GPT: Imitation Learning for Multi-Agent Pathfinding at Scale
Aug 29, 2024Multi-agent pathfinding (MAPF) is a challenging computational problem that typically requires to find collision-free paths for multiple agents in a shared environment. Solving MAPF optimally is NP-hard, yet efficient solutions are critical for numerous applications, including automated warehouses and transportation systems. Recently, learning-based approaches to MAPF have gained attention, particularly those leveraging deep reinforcement learning. Following current trends in machine learning, we have created a foundation model for the MAPF problems called MAPF-GPT. Using imitation learning, we have trained a policy on a set of pre-collected sub-optimal expert trajectories that can generate actions in conditions of partial observability without additional heuristics, reward functions, or communication with other agents. The resulting MAPF-GPT model demonstrates zero-shot learning abilities when solving the MAPF problem instances that were not present in the training dataset. We show that MAPF-GPT notably outperforms the current best-performing learnable-MAPF solvers on a diverse range of problem instances and is efficient in terms of computation (in the inference mode).
Safe Policy Exploration Improvement via Subgoals
Aug 25, 2024Reinforcement learning is a widely used approach to autonomous navigation, showing potential in various tasks and robotic setups. Still, it often struggles to reach distant goals when safety constraints are imposed (e.g., the wheeled robot is prohibited from moving close to the obstacles). One of the main reasons for poor performance in such setups, which is common in practice, is that the need to respect the safety constraints degrades the exploration capabilities of an RL agent. To this end, we introduce a novel learnable algorithm that is based on decomposing the initial problem into smaller sub-problems via intermediate goals, on the one hand, and respects the limit of the cumulative safety constraints, on the other hand -- SPEIS(Safe Policy Exploration Improvement via Subgoals). It comprises the two coupled policies trained end-to-end: subgoal and safe. The subgoal policy is trained to generate the subgoal based on the transitions from the buffer of the safe (main) policy that helps the safe policy to reach distant goals. Simultaneously, the safe policy maximizes its rewards while attempting not to violate the limit of the cumulative safety constraints, thus providing a certain level of safety. We evaluate SPEIS in a wide range of challenging (simulated) environments that involve different types of robots in two different environments: autonomous vehicles from the POLAMP environment and car, point, doggo, and sweep from the safety-gym environment. We demonstrate that our method consistently outperforms state-of-the-art competitors and can significantly reduce the collision rate while maintaining high success rates (higher by 80% compared to the best-performing methods).
POGEMA: A Benchmark Platform for Cooperative Multi-Agent Navigation
Jul 20, 2024Multi-agent reinforcement learning (MARL) has recently excelled in solving challenging cooperative and competitive multi-agent problems in various environments with, mostly, few agents and full observability. Moreover, a range of crucial robotics-related tasks, such as multi-robot navigation and obstacle avoidance, that have been conventionally approached with the classical non-learnable methods (e.g., heuristic search) is currently suggested to be solved by the learning-based or hybrid methods. Still, in this domain, it is hard, not to say impossible, to conduct a fair comparison between classical, learning-based, and hybrid approaches due to the lack of a unified framework that supports both learning and evaluation. To this end, we introduce POGEMA, a set of comprehensive tools that includes a fast environment for learning, a generator of problem instances, the collection of pre-defined ones, a visualization toolkit, and a benchmarking tool that allows automated evaluation. We introduce and specify an evaluation protocol defining a range of domain-related metrics computed on the basics of the primary evaluation indicators (such as success rate and path length), allowing a fair multi-fold comparison. The results of such a comparison, which involves a variety of state-of-the-art MARL, search-based, and hybrid methods, are presented.
Model-based Policy Optimization using Symbolic World Model
Jul 18, 2024



The application of learning-based control methods in robotics presents significant challenges. One is that model-free reinforcement learning algorithms use observation data with low sample efficiency. To address this challenge, a prevalent approach is model-based reinforcement learning, which involves employing an environment dynamics model. We suggest approximating transition dynamics with symbolic expressions, which are generated via symbolic regression. Approximation of a mechanical system with a symbolic model has fewer parameters than approximation with neural networks, which can potentially lead to higher accuracy and quality of extrapolation. We use a symbolic dynamics model to generate trajectories in model-based policy optimization to improve the sample efficiency of the learning algorithm. We evaluate our approach across various tasks within simulated environments. Our method demonstrates superior sample efficiency in these tasks compared to model-free and model-based baseline methods.