 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusGraph: Graph-Structured Frame Selection for Embodied Long Video Question Answering
Mar 04, 2026The ability to understand long videos is vital for embodied intelligent agents, because their effectiveness depends on how well they can accumulate, organize, and leverage long-horizon perceptual memories. Recently, multimodal LLMs have been gaining popularity for solving the long video understanding task due to their general ability to understand natural language and to leverage world knowledge. However, as the number of frames provided to an MLLM increases, the quality of its responses tends to degrade, and inference time grows. Therefore, when using MLLMs for long video understanding, a crucial step is selecting key frames from the video to answer user queries. In this work, we develop FocusGraph, a framework for keyframe selection for question answering over long egocentric videos. It leverages a lightweight trainable Scene-Caption LLM Selector that selects query-relevant clips based on their graph-based captions, and a training-free method for selecting keyframes from these clips. Unlike existing methods, the proposed Scene-Caption LLM Selector does not rely on the original sequence of low-resolution frames; instead, it operates on a compact textual representation of the scene. We then design a training-free Patch-wise Sparse-Flow Retention (PSFR) method to select keyframes from the resulting sequence of clips, which are fed into an MLLM to produce the final answer. Together, these components enable FocusGraph to achieve state-of-the-art results on challenging egocentric long-video question answering benchmarks, including FindingDory and HourVideo, while significantly reducing inference time relative to baseline approaches.
3DGraphLLM: Combining Semantic Graphs and Large Language Models for 3D Scene Understanding
Dec 24, 2024A 3D scene graph represents a compact scene model, storing information about the objects and the semantic relationships between them, making its use promising for robotic tasks. When interacting with a user, an embodied intelligent agent should be capable of responding to various queries about the scene formulated in natural language. Large Language Models (LLMs) are beneficial solutions for user-robot interaction due to their natural language understanding and reasoning abilities. Recent methods for creating learnable representations of 3D scenes have demonstrated the potential to improve the quality of LLMs responses by adapting to the 3D world. However, the existing methods do not explicitly utilize information about the semantic relationships between objects, limiting themselves to information about their coordinates. In this work, we propose a method 3DGraphLLM for constructing a learnable representation of a 3D scene graph. The learnable representation is used as input for LLMs to perform 3D vision-language tasks. In our experiments on popular ScanRefer, RIORefer, Multi3DRefer, ScanQA, Sqa3D, and Scan2cap datasets, we demonstrate the advantage of this approach over baseline methods that do not use information about the semantic relationships between objects. The code is publicly available at https://github.com/CognitiveAISystems/3DGraphLLM.
Beyond Bare Queries: Open-Vocabulary Object Retrieval with 3D Scene Graph
Jun 11, 2024



Locating objects referred to in natural language poses a significant challenge for autonomous agents. Existing CLIP-based open-vocabulary methods successfully perform 3D object retrieval with simple (bare) queries but cannot cope with ambiguous descriptions that demand an understanding of object relations. To tackle this problem, we propose a modular approach called BBQ (Beyond Bare Queries), which constructs 3D scene spatial graph representation with metric edges and utilizes a large language model as a human-to-agent interface through our deductive scene reasoning algorithm. BBQ employs robust DINO-powered associations to form 3D objects, an advanced raycasting algorithm to project them to 2D, and a vision-language model to describe them as graph nodes. On Replica and ScanNet datasets, we show that the designed method accurately constructs 3D object-centric maps. We have demonstrated that their quality takes a leading place for open-vocabulary 3D semantic segmentation against other zero-shot methods. Also, we show that leveraging spatial relations is especially effective for scenes containing multiple entities of the same semantic class. On Sr3D and Nr3D benchmarks, our deductive approach demonstrates a significant improvement, enabling retrieving objects by complex queries compared to other state-of-the-art methods. Considering our design solutions, we achieved a processing speed approximately x3 times faster than the closest analog. This promising performance enables our approach for usage in applied intelligent robotics projects. We make the code publicly available at linukc.github.io/bbq/.
Interactive Semantic Map Representation for Skill-based Visual Object Navigation
Nov 07, 2023Visual object navigation using learning methods is one of the key tasks in mobile robotics. This paper introduces a new representation of a scene semantic map formed during the embodied agent interaction with the indoor environment. It is based on a neural network method that adjusts the weights of the segmentation model with backpropagation of the predicted fusion loss values during inference on a regular (backward) or delayed (forward) image sequence. We have implemented this representation into a full-fledged navigation approach called SkillTron, which can select robot skills from end-to-end policies based on reinforcement learning and classic map-based planning methods. The proposed approach makes it possible to form both intermediate goals for robot exploration and the final goal for object navigation. We conducted intensive experiments with the proposed approach in the Habitat environment, which showed a significant superiority in navigation quality metrics compared to state-of-the-art approaches. The developed code and used custom datasets are publicly available at github.com/AIRI-Institute/skill-fusion.
SegmATRon: Embodied Adaptive Semantic Segmentation for Indoor Environment
Oct 18, 2023This paper presents an adaptive transformer model named SegmATRon for embodied image semantic segmentation. Its distinctive feature is the adaptation of model weights during inference on several images using a hybrid multicomponent loss function. We studied this model on datasets collected in the photorealistic Habitat and the synthetic AI2-THOR Simulators. We showed that obtaining additional images using the agent's actions in an indoor environment can improve the quality of semantic segmentation. The code of the proposed approach and datasets are publicly available at https://github.com/wingrune/SegmATRon.
Aligning individual brains with Fused Unbalanced Gromov-Wasserstein
Jun 19, 2022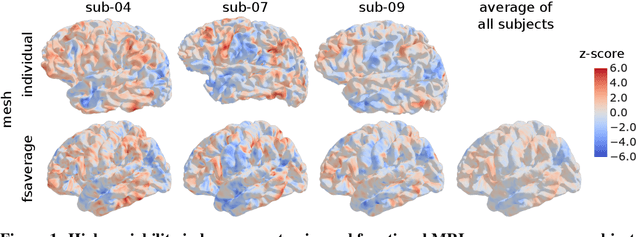
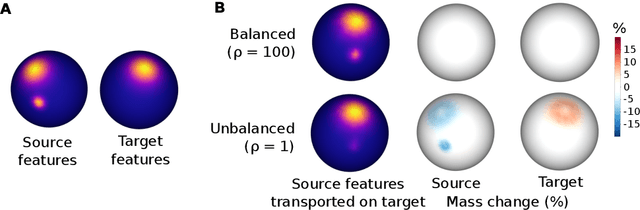

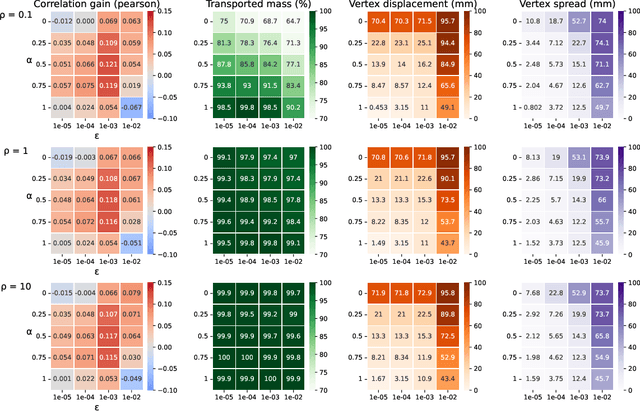
Individual brains vary in both anatomy and functional organization, even within a given species. Inter-individual variability is a major impediment when trying to draw generalizable conclusions from neuroimaging data collected on groups of subjects. Current co-registration procedures rely on limited data, and thus lead to very coarse inter-subject alignments. In this work, we present a novel method for inter-subject alignment based on Optimal Transport, denoted as Fused Unbalanced Gromov Wasserstein (FUGW). The method aligns cortical surfaces based on the similarity of their functional signatures in response to a variety of stimulation settings, while penalizing large deformations of individual topographic organization. We demonstrate that FUGW is well-suited for whole-brain landmark-free alignment. The unbalanced feature allows to deal with the fact that functional areas vary in size across subjects. Our results show that FUGW alignment significantly increases between-subject correlation of activity for independent functional data, and leads to more precise mapping at the group level.