 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentanglement and Compositionality of Letter Identity and Letter Position in Variational Auto-Encoder Vision Models
Dec 11, 2024



Human readers can accurately count how many letters are in a word (e.g., 7 in ``buffalo''), remove a letter from a given position (e.g., ``bufflo'') or add a new one. The human brain of readers must have therefore learned to disentangle information related to the position of a letter and its identity. Such disentanglement is necessary for the compositional, unbounded, ability of humans to create and parse new strings, with any combination of letters appearing in any positions. Do modern deep neural models also possess this crucial compositional ability? Here, we tested whether neural models that achieve state-of-the-art on disentanglement of features in visual input can also disentangle letter position and letter identity when trained on images of written words. Specifically, we trained beta variational autoencoder ($\beta$-VAE) to reconstruct images of letter strings and evaluated their disentanglement performance using CompOrth - a new benchmark that we created for studying compositional learning and zero-shot generalization in visual models for orthography. The benchmark suggests a set of tests, of increasing complexity, to evaluate the degree of disentanglement between orthographic features of written words in deep neural models. Using CompOrth, we conducted a set of experiments to analyze the generalization ability of these models, in particular, to unseen word length and to unseen combinations of letter identities and letter positions. We found that while models effectively disentangle surface features, such as horizontal and vertical `retinal' locations of words within an image, they dramatically fail to disentangle letter position and letter identity and lack any notion of word length. Together, this study demonstrates the shortcomings of state-of-the-art $\beta$-VAE models compared to humans and proposes a new challenge and a corresponding benchmark to evaluate neural models.
Cracking the neural code for word recognition in convolutional neural networks
Mar 10, 2024



Learning to read places a strong challenge on the visual system. Years of expertise lead to a remarkable capacity to separate highly similar letters and encode their relative positions, thus distinguishing words such as FORM and FROM, invariantly over a large range of sizes and absolute positions. How neural circuits achieve invariant word recognition remains unknown. Here, we address this issue by training deep neural network models to recognize written words and then analyzing how reading-specialized units emerge and operate across different layers of the network. With literacy, a small subset of units becomes specialized for word recognition in the learned script, similar to the "visual word form area" of the human brain. We show that these units are sensitive to specific letter identities and their distance from the blank space at the left or right of a word, thus acting as "space bigrams". These units specifically encode ordinal positions and operate by pooling across low and high-frequency detector units from early layers of the network. The proposed neural code provides a mechanistic insight into how information on letter identity and position is extracted and allow for invariant word recognition, and leads to predictions for reading behavior, error patterns, and the neurophysiology of reading.
Aligning individual brains with Fused Unbalanced Gromov-Wasserstein
Jun 19, 2022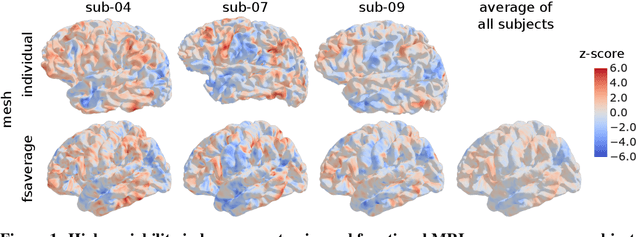
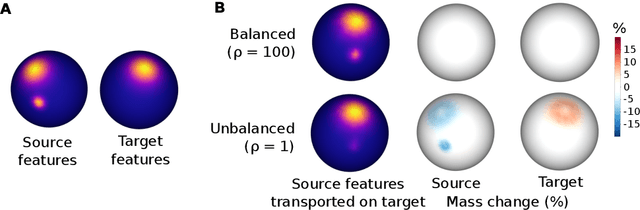

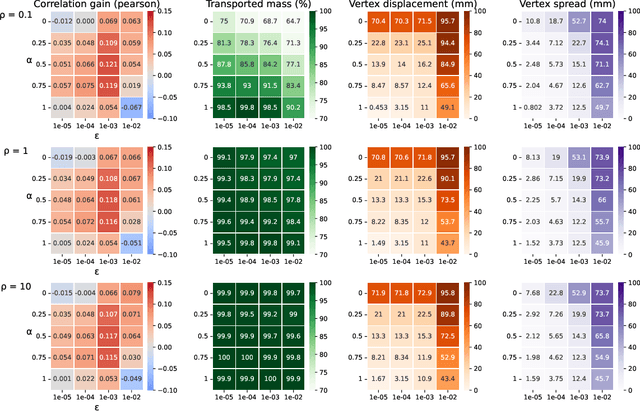
Individual brains vary in both anatomy and functional organization, even within a given species. Inter-individual variability is a major impediment when trying to draw generalizable conclusions from neuroimaging data collected on groups of subjects. Current co-registration procedures rely on limited data, and thus lead to very coarse inter-subject alignments. In this work, we present a novel method for inter-subject alignment based on Optimal Transport, denoted as Fused Unbalanced Gromov Wasserstein (FUGW). The method aligns cortical surfaces based on the similarity of their functional signatures in response to a variety of stimulation settings, while penalizing large deformations of individual topographic organization. We demonstrate that FUGW is well-suited for whole-brain landmark-free alignment. The unbalanced feature allows to deal with the fact that functional areas vary in size across subjects. Our results show that FUGW alignment significantly increases between-subject correlation of activity for independent functional data, and leads to more precise mapping at the group level.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Causal Transformers Perform Below Chance on Recursive Nested Constructions, Unlike Humans
Oct 14, 2021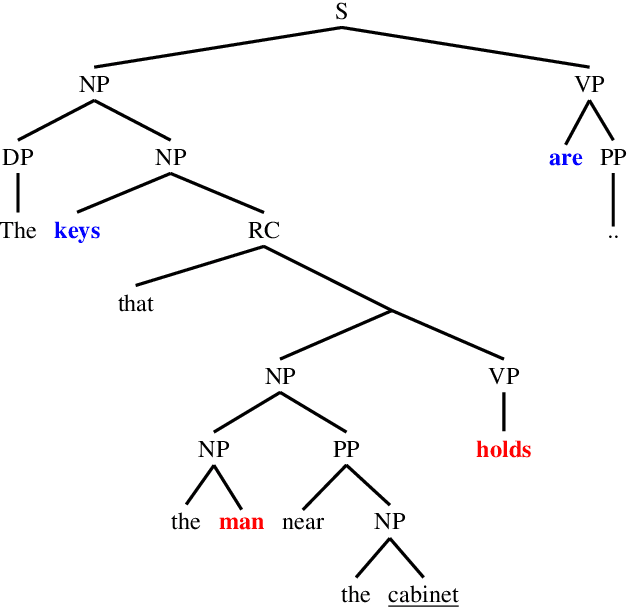
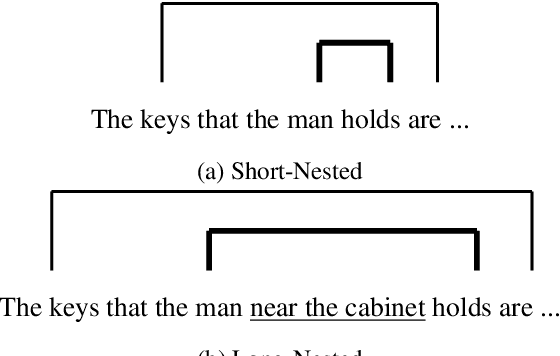
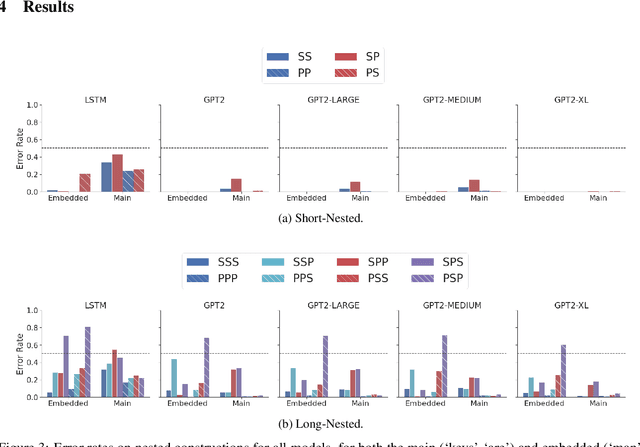
Recursive processing is considered a hallmark of human linguistic abilities. A recent study evaluated recursive processing in recurrent neural language models (RNN-LMs) and showed that such models perform below chance level on embedded dependencies within nested constructions -- a prototypical example of recursion in natural language. Here, we study if state-of-the-art Transformer LMs do any better. We test four different Transformer LMs on two different types of nested constructions, which differ in whether the embedded (inner) dependency is short or long range. We find that Transformers achieve near-perfect performance on short-range embedded dependencies, significantly better than previous results reported for RNN-LMs and humans. However, on long-range embedded dependencies, Transformers' performance sharply drops below chance level. Remarkably, the addition of only three words to the embedded dependency caused Transformers to fall from near-perfect to below-chance performance. Taken together, our results reveal Transformers' shortcoming when it comes to recursive, structure-based, processing.
Can RNNs learn Recursive Nested Subject-Verb Agreements?
Jan 06, 2021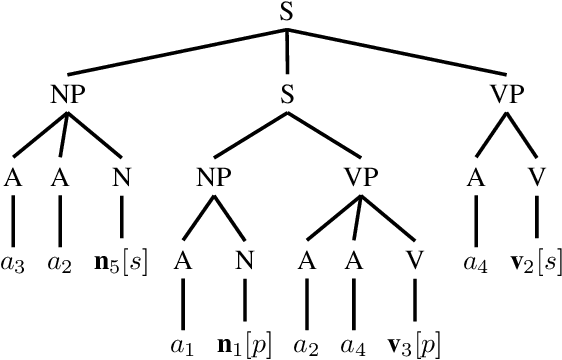
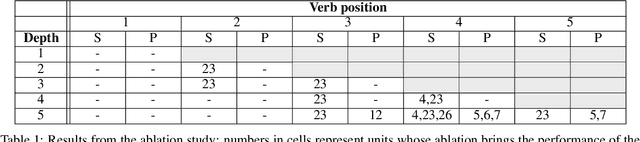
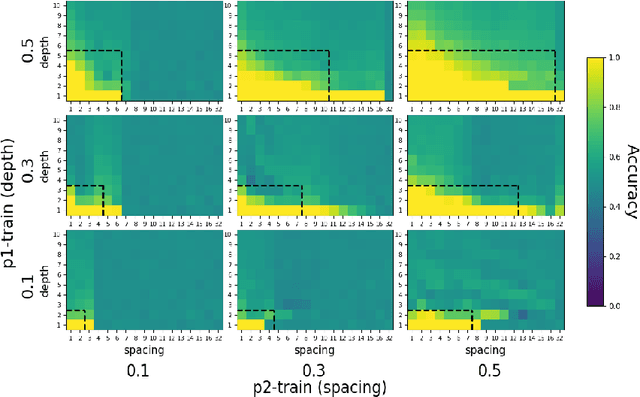

One of the fundamental principles of contemporary linguistics states that language processing requires the ability to extract recursively nested tree structures. However, it remains unclear whether and how this code could be implemented in neural circuits. Recent advances in Recurrent Neural Networks (RNNs), which achieve near-human performance in some language tasks, provide a compelling model to address such questions. Here, we present a new framework to study recursive processing in RNNs, using subject-verb agreement as a probe into the representations of the neural network. We trained six distinct types of RNNs on a simplified probabilistic context-free grammar designed to independently manipulate the length of a sentence and the depth of its syntactic tree. All RNNs generalized to subject-verb dependencies longer than those seen during training. However, none systematically generalized to deeper tree structures, even those with a structural bias towards learning nested tree (i.e., stack-RNNs). In addition, our analyses revealed primacy and recency effects in the generalization patterns of LSTM-based models, showing that these models tend to perform well on the outer- and innermost parts of a center-embedded tree structure, but poorly on its middle levels. Finally, probing the internal states of the model during the processing of sentences with nested tree structures, we found a complex encoding of grammatical agreement information (e.g. grammatical number), in which all the information for multiple words nouns was carried by a single unit. Taken together, these results indicate how neural networks may extract bounded nested tree structures, without learning a systematic recursive rule.
Exploring Processing of Nested Dependencies in Neural-Network Language Models and Humans
Jun 19, 2020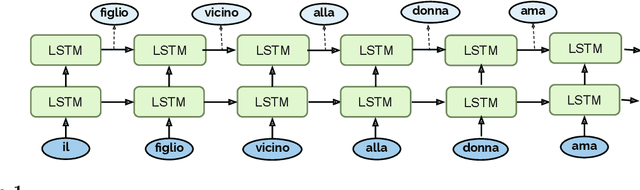

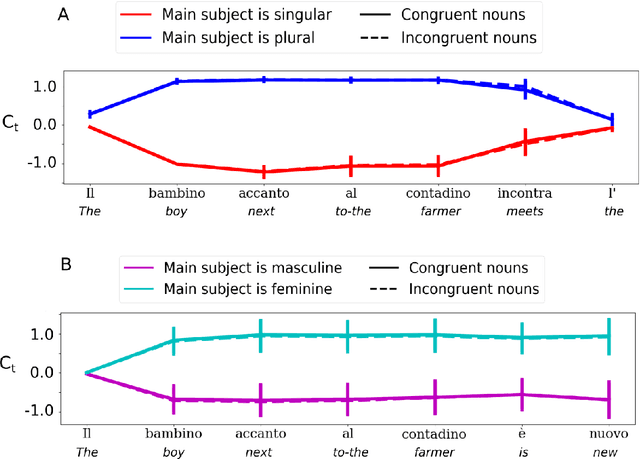

Recursive processing in sentence comprehension is considered a hallmark of human linguistic abilities. However, its underlying neural mechanisms remain largely unknown. We studied whether a recurrent neural network with Long Short-Term Memory units can mimic a central aspect of human sentence processing, namely the handling of long-distance agreement dependencies. Although the network was solely trained to predict the next word in a large corpus, analysis showed the emergence of a small set of specialized units that successfully handled local and long-distance syntactic agreement for grammatical number. However, simulations showed that this mechanism does not support full recursion and fails with some long-range embedded dependencies. We tested the model's predictions in a behavioral experiment where humans detected violations in number agreement in sentences with systematic variations in the singular/plural status of multiple nouns, with or without embedding. Human and model error patterns were remarkably similar, showing that the model echoes various effects observed in human data. However, a key difference was that, with embedded long-range dependencies, humans remained above chance level, while the model's systematic errors brought it below chance. Overall, our study shows that exploring the ways in which modern artificial neural networks process sentences leads to precise and testable hypotheses about human linguistic performance.
The emergence of number and syntax units in LSTM language models
Apr 02, 2019
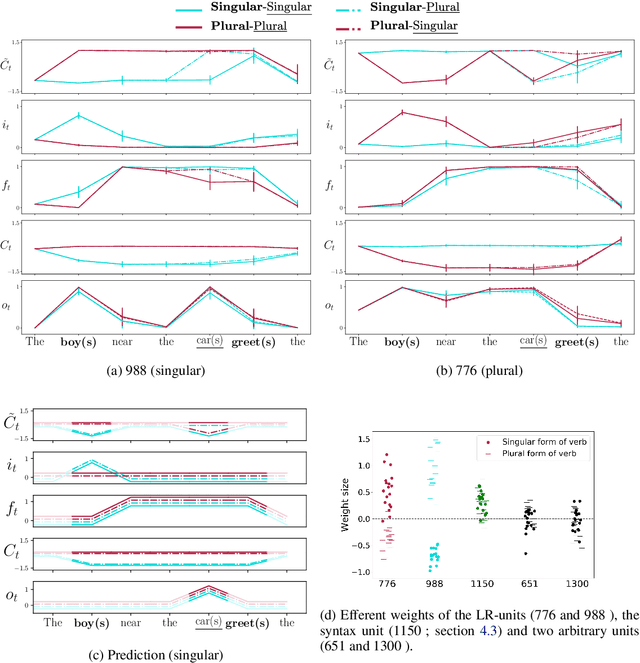
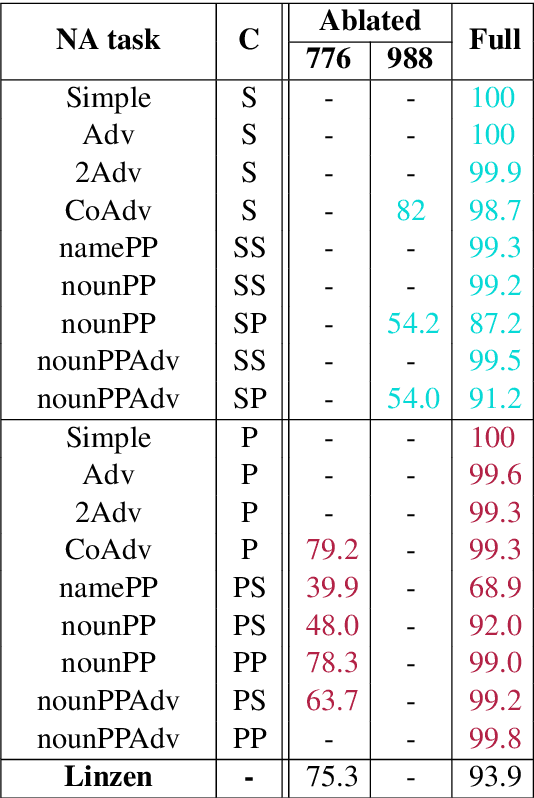
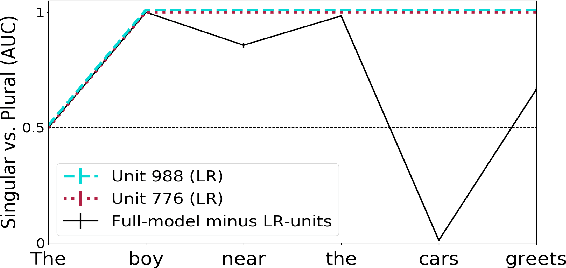
Recent work has shown that LSTMs trained on a generic language modeling objective capture syntax-sensitive generalizations such as long-distance number agreement. We have however no mechanistic understanding of how they accomplish this remarkable feat. Some have conjectured it depends on heuristics that do not truly take hierarchical structure into account. We present here a detailed study of the inner mechanics of number tracking in LSTMs at the single neuron level. We discover that long-distance number information is largely managed by two `number units'. Importantly, the behaviour of these units is partially controlled by other units independently shown to track syntactic structure. We conclude that LSTMs are, to some extent, implementing genuinely syntactic processing mechanisms, paving the way to a more general understanding of grammatical encoding in LSTMs.