 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETROcode: Leveraging a Code Database for Improved Natural Language to Code Generation
Apr 09, 2025As text and code resources have expanded, large-scale pre-trained models have shown promising capabilities in code generation tasks, typically employing supervised fine-tuning with problem statement-program pairs. However, increasing model size and data volume for performance gains also raises computational demands and risks of overfitting. Addressing these challenges, we present RETROcode, a novel adaptation of the RETRO architecture \cite{RETRO} for sequence-to-sequence models, utilizing a large code database as an auxiliary scaling method. This approach, diverging from simply enlarging model and dataset sizes, allows RETROcode to leverage a vast code database for prediction, enhancing the model's efficiency by integrating extensive memory. Our findings indicate that RETROcode not only outperforms similar-sized traditional architectures on test sets but also approaches the effectiveness of the much larger Codex model, despite being trained from scratch on a substantially smaller dataset.
CodeInsight: A Curated Dataset of Practical Coding Solutions from Stack Overflow
Sep 25, 2024



We introduce a novel dataset tailored for code generation, aimed at aiding developers in common tasks. Our dataset provides examples that include a clarified intent, code snippets associated, and an average of three related unit tests. It encompasses a range of libraries such as \texttt{Pandas}, \texttt{Numpy}, and \texttt{Regex}, along with more than 70 standard libraries in Python code derived from Stack Overflow. Comprising 3,409 crafted examples by Python experts, our dataset is designed for both model finetuning and standalone evaluation. To complete unit tests evaluation, we categorize examples in order to get more fine grained analysis, enhancing the understanding of models' strengths and weaknesses in specific coding tasks. The examples have been refined to reduce data contamination, a process confirmed by the performance of three leading models: Mistral 7B, CodeLLaMa 13B, and Starcoder 15B. We further investigate data-contamination testing GPT-4 performance on a part of our dataset. The benchmark can be accessed at \url{https://github.com/NathanaelBeau/CodeInsight}.
Assessing the Capacity of Transformer to Abstract Syntactic Representations: A Contrastive Analysis Based on Long-distance Agreement
Dec 08, 2022The long-distance agreement, evidence for syntactic structure, is increasingly used to assess the syntactic generalization of Neural Language Models. Much work has shown that transformers are capable of high accuracy in varied agreement tasks, but the mechanisms by which the models accomplish this behavior are still not well understood. To better understand transformers' internal working, this work contrasts how they handle two superficially similar but theoretically distinct agreement phenomena: subject-verb and object-past participle agreement in French. Using probing and counterfactual analysis methods, our experiments show that i) the agreement task suffers from several confounders which partially question the conclusions drawn so far and ii) transformers handle subject-verb and object-past participle agreements in a way that is consistent with their modeling in theoretical linguistics.
The impact of lexical and grammatical processing on generating code from natural language
Mar 16, 2022
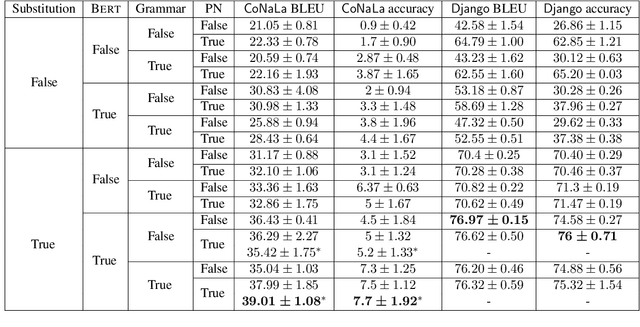

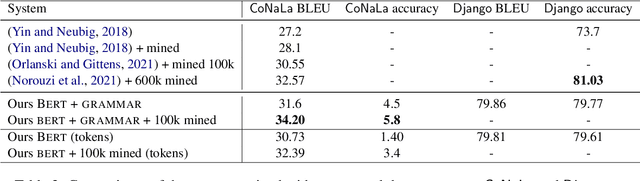
Considering the seq2seq architecture of TranX for natural language to code translation, we identify four key components of importance: grammatical constraints, lexical preprocessing, input representations, and copy mechanisms. To study the impact of these components, we use a state-of-the-art architecture that relies on BERT encoder and a grammar-based decoder for which a formalization is provided. The paper highlights the importance of the lexical substitution component in the current natural language to code systems.
Can RNNs learn Recursive Nested Subject-Verb Agreements?
Jan 06, 2021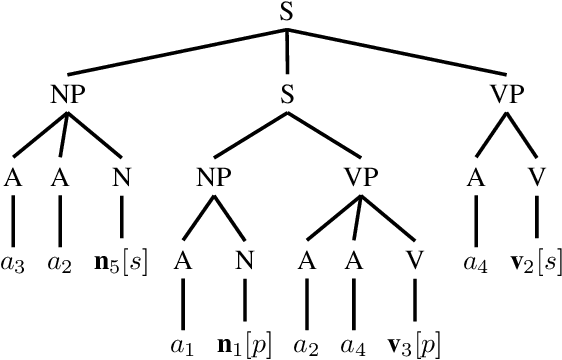
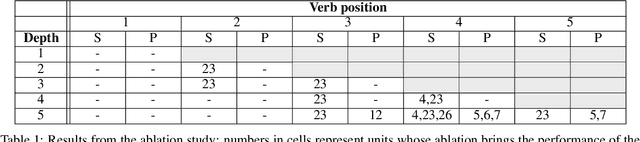
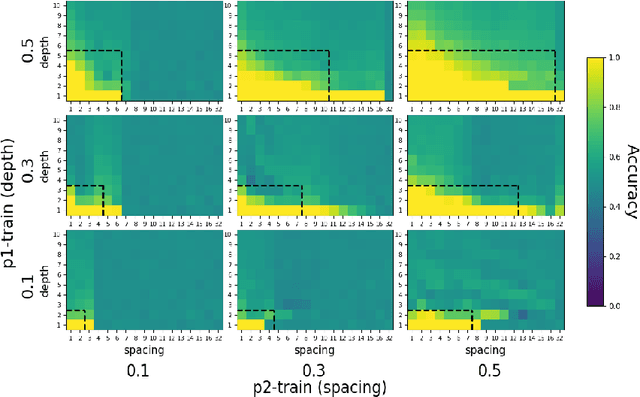

One of the fundamental principles of contemporary linguistics states that language processing requires the ability to extract recursively nested tree structures. However, it remains unclear whether and how this code could be implemented in neural circuits. Recent advances in Recurrent Neural Networks (RNNs), which achieve near-human performance in some language tasks, provide a compelling model to address such questions. Here, we present a new framework to study recursive processing in RNNs, using subject-verb agreement as a probe into the representations of the neural network. We trained six distinct types of RNNs on a simplified probabilistic context-free grammar designed to independently manipulate the length of a sentence and the depth of its syntactic tree. All RNNs generalized to subject-verb dependencies longer than those seen during training. However, none systematically generalized to deeper tree structures, even those with a structural bias towards learning nested tree (i.e., stack-RNNs). In addition, our analyses revealed primacy and recency effects in the generalization patterns of LSTM-based models, showing that these models tend to perform well on the outer- and innermost parts of a center-embedded tree structure, but poorly on its middle levels. Finally, probing the internal states of the model during the processing of sentences with nested tree structures, we found a complex encoding of grammatical agreement information (e.g. grammatical number), in which all the information for multiple words nouns was carried by a single unit. Taken together, these results indicate how neural networks may extract bounded nested tree structures, without learning a systematic recursive rule.
FlauBERT: Unsupervised Language Model Pre-training for French
Jan 09, 2020
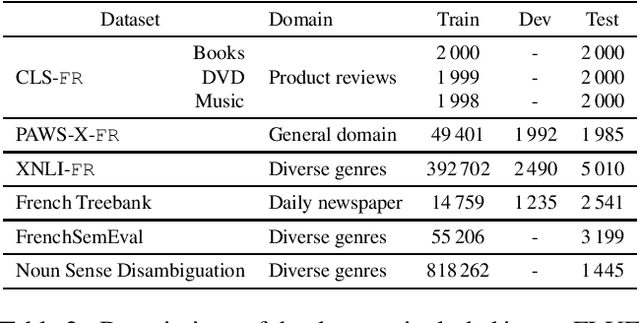
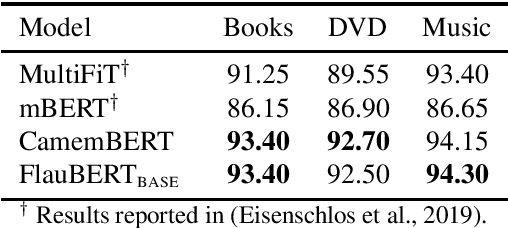

Language models have become a key step to achieve state-of-the art results in many different Natural Language Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their contextualization at the sentence level. This has been widely demonstrated for English using contextualized representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al., 2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the time they outperform other pre-training approaches. Different versions of FlauBERT as well as a unified evaluation protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research community for further reproducible experiments in French NLP.
Unlexicalized Transition-based Discontinuous Constituency Parsing
Feb 24, 2019Lexicalized parsing models are based on the assumptions that (i) constituents are organized around a lexical head (ii) bilexical statistics are crucial to solve ambiguities. In this paper, we introduce an unlexicalized transition-based parser for discontinuous constituency structures, based on a structure-label transition system and a bi-LSTM scoring system. We compare it to lexicalized parsing models in order to address the question of lexicalization in the context of discontinuous constituency parsing. Our experiments show that unlexicalized models systematically achieve higher results than lexicalized models, and provide additional empirical evidence that lexicalization is not necessary to achieve strong parsing results. Our best unlexicalized model sets a new state of the art on English and German discontinuous constituency treebanks. We further provide a per-phenomenon analysis of its errors on discontinuous constituents.