 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Phonemic, Syntactic, and Semantic Representations in Artificial Neural Networks
Jan 26, 2026During language acquisition, children successively learn to categorize phonemes, identify words, and combine them with syntax to form new meaning. While the development of this behavior is well characterized, we still lack a unifying computational framework to explain its underlying neural representations. Here, we investigate whether and when phonemic, lexical, and syntactic representations emerge in the activations of artificial neural networks during their training. Our results show that both speech- and text-based models follow a sequence of learning stages: during training, their neural activations successively build subspaces, where the geometry of the neural activations represents phonemic, lexical, and syntactic structure. While this developmental trajectory qualitatively relates to children's, it is quantitatively different: These algorithms indeed require two to four orders of magnitude more data for these neural representations to emerge. Together, these results show conditions under which major stages of language acquisition spontaneously emerge, and hence delineate a promising path to understand the computations underpinning language acquisition.
A Neural Model for Word Repetition
Jun 16, 2025It takes several years for the developing brain of a baby to fully master word repetition-the task of hearing a word and repeating it aloud. Repeating a new word, such as from a new language, can be a challenging task also for adults. Additionally, brain damage, such as from a stroke, may lead to systematic speech errors with specific characteristics dependent on the location of the brain damage. Cognitive sciences suggest a model with various components for the different processing stages involved in word repetition. While some studies have begun to localize the corresponding regions in the brain, the neural mechanisms and how exactly the brain performs word repetition remain largely unknown. We propose to bridge the gap between the cognitive model of word repetition and neural mechanisms in the human brain by modeling the task using deep neural networks. Neural models are fully observable, allowing us to study the detailed mechanisms in their various substructures and make comparisons with human behavior and, ultimately, the brain. Here, we make first steps in this direction by: (1) training a large set of models to simulate the word repetition task; (2) creating a battery of tests to probe the models for known effects from behavioral studies in humans, and (3) simulating brain damage through ablation studies, where we systematically remove neurons from the model, and repeat the behavioral study to examine the resulting speech errors in the "patient" model. Our results show that neural models can mimic several effects known from human research, but might diverge in other aspects, highlighting both the potential and the challenges for future research aimed at developing human-like neural models.
Optimizing fMRI Data Acquisition for Decoding Natural Speech with Limited Participants
May 27, 2025We investigate optimal strategies for decoding perceived natural speech from fMRI data acquired from a limited number of participants. Leveraging Lebel et al. (2023)'s dataset of 8 participants, we first demonstrate the effectiveness of training deep neural networks to predict LLM-derived text representations from fMRI activity. Then, in this data regime, we observe that multi-subject training does not improve decoding accuracy compared to single-subject approach. Furthermore, training on similar or different stimuli across subjects has a negligible effect on decoding accuracy. Finally, we find that our decoders better model syntactic than semantic features, and that stories containing sentences with complex syntax or rich semantic content are more challenging to decode. While our results demonstrate the benefits of having extensive data per participant (deep phenotyping), they suggest that leveraging multi-subject for natural speech decoding likely requires deeper phenotyping or a substantially larger cohort.
Meta-Learning Neural Mechanisms rather than Bayesian Priors
Mar 20, 2025Children acquire language despite being exposed to several orders of magnitude less data than large language models require. Meta-learning has been proposed as a way to integrate human-like learning biases into neural-network architectures, combining both the structured generalizations of symbolic models with the scalability of neural-network models. But what does meta-learning exactly imbue the model with? We investigate the meta-learning of formal languages and find that, contrary to previous claims, meta-trained models are not learning simplicity-based priors when meta-trained on datasets organised around simplicity. Rather, we find evidence that meta-training imprints neural mechanisms (such as counters) into the model, which function like cognitive primitives for the network on downstream tasks. Most surprisingly, we find that meta-training on a single formal language can provide as much improvement to a model as meta-training on 5000 different formal languages, provided that the formal language incentivizes the learning of useful neural mechanisms. Taken together, our findings provide practical implications for efficient meta-learning paradigms and new theoretical insights into linking symbolic theories and neural mechanisms.
Disentanglement and Compositionality of Letter Identity and Letter Position in Variational Auto-Encoder Vision Models
Dec 11, 2024



Human readers can accurately count how many letters are in a word (e.g., 7 in ``buffalo''), remove a letter from a given position (e.g., ``bufflo'') or add a new one. The human brain of readers must have therefore learned to disentangle information related to the position of a letter and its identity. Such disentanglement is necessary for the compositional, unbounded, ability of humans to create and parse new strings, with any combination of letters appearing in any positions. Do modern deep neural models also possess this crucial compositional ability? Here, we tested whether neural models that achieve state-of-the-art on disentanglement of features in visual input can also disentangle letter position and letter identity when trained on images of written words. Specifically, we trained beta variational autoencoder ($\beta$-VAE) to reconstruct images of letter strings and evaluated their disentanglement performance using CompOrth - a new benchmark that we created for studying compositional learning and zero-shot generalization in visual models for orthography. The benchmark suggests a set of tests, of increasing complexity, to evaluate the degree of disentanglement between orthographic features of written words in deep neural models. Using CompOrth, we conducted a set of experiments to analyze the generalization ability of these models, in particular, to unseen word length and to unseen combinations of letter identities and letter positions. We found that while models effectively disentangle surface features, such as horizontal and vertical `retinal' locations of words within an image, they dramatically fail to disentangle letter position and letter identity and lack any notion of word length. Together, this study demonstrates the shortcomings of state-of-the-art $\beta$-VAE models compared to humans and proposes a new challenge and a corresponding benchmark to evaluate neural models.
A polar coordinate system represents syntax in large language models
Dec 07, 2024



Originally formalized with symbolic representations, syntactic trees may also be effectively represented in the activations of large language models (LLMs). Indeed, a 'Structural Probe' can find a subspace of neural activations, where syntactically related words are relatively close to one-another. However, this syntactic code remains incomplete: the distance between the Structural Probe word embeddings can represent the existence but not the type and direction of syntactic relations. Here, we hypothesize that syntactic relations are, in fact, coded by the relative direction between nearby embeddings. To test this hypothesis, we introduce a 'Polar Probe' trained to read syntactic relations from both the distance and the direction between word embeddings. Our approach reveals three main findings. First, our Polar Probe successfully recovers the type and direction of syntactic relations, and substantially outperforms the Structural Probe by nearly two folds. Second, we confirm that this polar coordinate system exists in a low-dimensional subspace of the intermediate layers of many LLMs and becomes increasingly precise in the latest frontier models. Third, we demonstrate with a new benchmark that similar syntactic relations are coded similarly across the nested levels of syntactic trees. Overall, this work shows that LLMs spontaneously learn a geometry of neural activations that explicitly represents the main symbolic structures of linguistic theory.
What Makes Two Language Models Think Alike?
Jun 24, 2024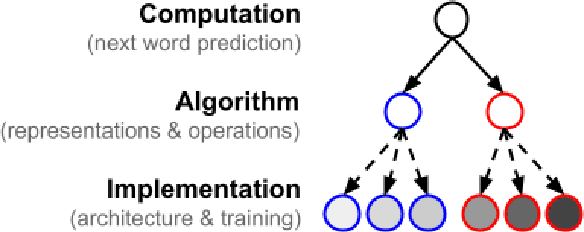



Do architectural differences significantly affect the way models represent and process language? We propose a new approach, based on metric-learning encoding models (MLEMs), as a first step to answer this question. The approach provides a feature-based comparison of how any two layers of any two models represent linguistic information. We apply the method to BERT, GPT-2 and Mamba. Unlike previous methods, MLEMs offer a transparent comparison, by identifying the specific linguistic features responsible for similarities and differences. More generally, the method uses formal, symbolic descriptions of a domain, and use these to compare neural representations. As such, the approach can straightforwardly be extended to other domains, such as speech and vision, and to other neural systems, including human brains.
What makes two models think alike?
Jun 18, 2024Do architectural differences significantly affect the way models represent and process language? We propose a new approach, based on metric-learning encoding models (MLEMs), as a first step to answer this question. The approach provides a feature-based comparison of how any two layers of any two models represent linguistic information. We apply the method to BERT, GPT-2 and Mamba. Unlike previous methods, MLEMs offer a transparent comparison, by identifying the specific linguistic features responsible for similarities and differences. More generally, the method uses formal, symbolic descriptions of a domain, and use these to compare neural representations. As such, the approach can straightforwardly be extended to other domains, such as speech and vision, and to other neural systems, including human brains.
Metric-Learning Encoding Models Identify Processing Profiles of Linguistic Features in BERT's Representations
Feb 18, 2024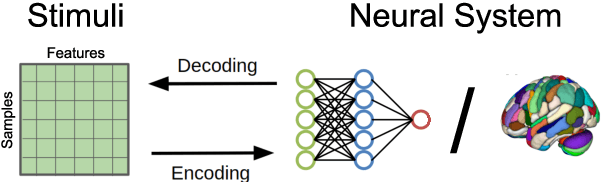
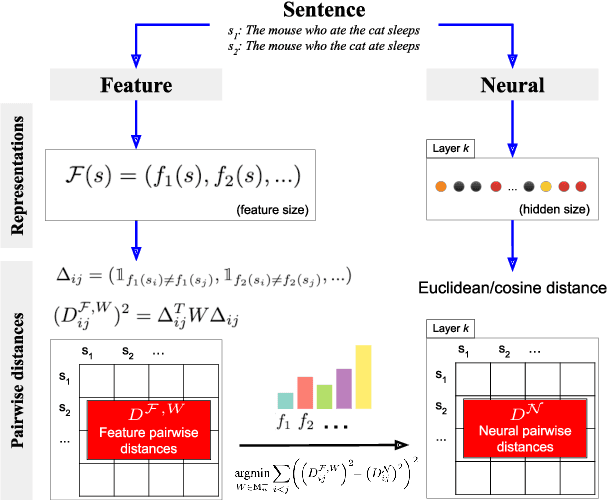
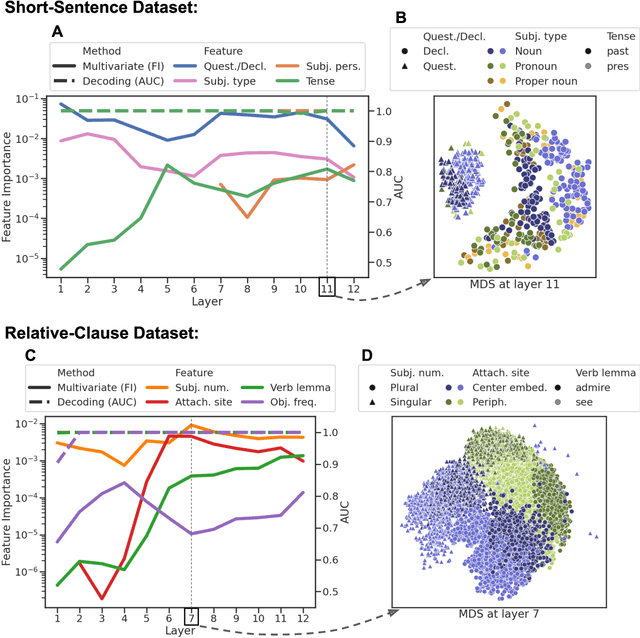
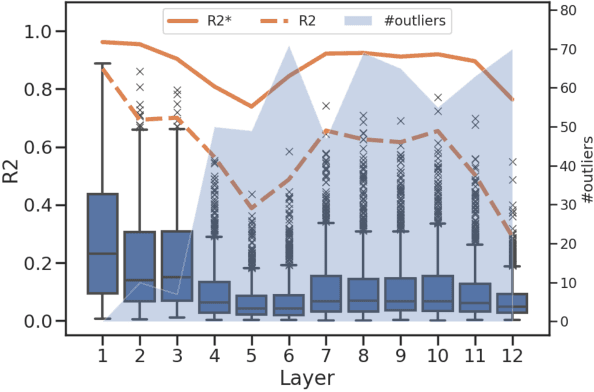
We introduce Metric-Learning Encoding Models (MLEMs) as a new approach to understand how neural systems represent the theoretical features of the objects they process. As a proof-of-concept, we apply MLEMs to neural representations extracted from BERT, and track a wide variety of linguistic features (e.g., tense, subject person, clause type, clause embedding). We find that: (1) linguistic features are ordered: they separate representations of sentences to different degrees in different layers; (2) neural representations are organized hierarchically: in some layers, we find clusters of representations nested within larger clusters, following successively important linguistic features; (3) linguistic features are disentangled in middle layers: distinct, selective units are activated by distinct linguistic features. Methodologically, MLEMs are superior (4) to multivariate decoding methods, being more robust to type-I errors, and (5) to univariate encoding methods, in being able to predict both local and distributed representations. Together, this demonstrates the utility of Metric-Learning Encoding Methods for studying how linguistic features are neurally encoded in language models and the advantage of MLEMs over traditional methods. MLEMs can be extended to other domains (e.g. vision) and to other neural systems, such as the human brain.
Language acquisition: do children and language models follow similar learning stages?
Jun 06, 2023



During language acquisition, children follow a typical sequence of learning stages, whereby they first learn to categorize phonemes before they develop their lexicon and eventually master increasingly complex syntactic structures. However, the computational principles that lead to this learning trajectory remain largely unknown. To investigate this, we here compare the learning trajectories of deep language models to those of children. Specifically, we test whether, during its training, GPT-2 exhibits stages of language acquisition comparable to those observed in children aged between 18 months and 6 years. For this, we train 48 GPT-2 models from scratch and evaluate their syntactic and semantic abilities at each training step, using 96 probes curated from the BLiMP, Zorro and BIG-Bench benchmarks. We then compare these evaluations with the behavior of 54 children during language production. Our analyses reveal three main findings. First, similarly to children, the language models tend to learn linguistic skills in a systematic order. Second, this learning scheme is parallel: the language tasks that are learned last improve from the very first training steps. Third, some - but not all - learning stages are shared between children and these language models. Overall, these results shed new light on the principles of language acquisition, and highlight important divergences in how humans and modern algorithms learn to process natural language.