 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeft-right asymmetry in predicting brain activity from LLMs' representations emerges with their formal linguistic competence
Feb 13, 2026When humans and large language models (LLMs) process the same text, activations in the LLMs correlate with brain activity measured, e.g., with functional magnetic resonance imaging (fMRI). Moreover, it has been shown that, as the training of an LLM progresses, the performance in predicting brain activity from its internal activations improves more in the left hemisphere than in the right one. The aim of the present work is to understand which kind of competence acquired by the LLMs underlies the emergence of this left-right asymmetry. Using the OLMo-2 7B language model at various training checkpoints and fMRI data from English participants, we compare the evolution of the left-right asymmetry in brain scores alongside performance on several benchmarks. We observe that the asymmetry co-emerges with the formal linguistic abilities of the LLM. These abilities are demonstrated in two ways: by the model's capacity to assign a higher probability to an acceptable sentence than to a grammatically unacceptable one within a minimal contrasting pair, or its ability to produce well-formed text. On the opposite, the left-right asymmetry does not correlate with the performance on arithmetic or Dyck language tasks; nor with text-based tasks involving world knowledge and reasoning. We generalize these results to another family of LLMs (Pythia) and another language, namely French. Our observations indicate that the left-right asymmetry in brain predictivity matches the progress in formal linguistic competence (knowledge of linguistic patterns).
Optimizing fMRI Data Acquisition for Decoding Natural Speech with Limited Participants
May 27, 2025We investigate optimal strategies for decoding perceived natural speech from fMRI data acquired from a limited number of participants. Leveraging Lebel et al. (2023)'s dataset of 8 participants, we first demonstrate the effectiveness of training deep neural networks to predict LLM-derived text representations from fMRI activity. Then, in this data regime, we observe that multi-subject training does not improve decoding accuracy compared to single-subject approach. Furthermore, training on similar or different stimuli across subjects has a negligible effect on decoding accuracy. Finally, we find that our decoders better model syntactic than semantic features, and that stories containing sentences with complex syntax or rich semantic content are more challenging to decode. While our results demonstrate the benefits of having extensive data per participant (deep phenotyping), they suggest that leveraging multi-subject for natural speech decoding likely requires deeper phenotyping or a substantially larger cohort.
Decoding individual words from non-invasive brain recordings across 723 participants
Dec 11, 2024Deep learning has recently enabled the decoding of language from the neural activity of a few participants with electrodes implanted inside their brain. However, reliably decoding words from non-invasive recordings remains an open challenge. To tackle this issue, we introduce a novel deep learning pipeline to decode individual words from non-invasive electro- (EEG) and magneto-encephalography (MEG) signals. We train and evaluate our approach on an unprecedentedly large number of participants (723) exposed to five million words either written or spoken in English, French or Dutch. Our model outperforms existing methods consistently across participants, devices, languages, and tasks, and can decode words absent from the training set. Our analyses highlight the importance of the recording device and experimental protocol: MEG and reading are easier to decode than EEG and listening, respectively, and it is preferable to collect a large amount of data per participant than to repeat stimuli across a large number of participants. Furthermore, decoding performance consistently increases with the amount of (i) data used for training and (ii) data used for averaging during testing. Finally, single-word predictions show that our model effectively relies on word semantics but also captures syntactic and surface properties such as part-of-speech, word length and even individual letters, especially in the reading condition. Overall, our findings delineate the path and remaining challenges towards building non-invasive brain decoders for natural language.
fMRI predictors based on language models of increasing complexity recover brain left lateralization
May 28, 2024



Over the past decade, studies of naturalistic language processing where participants are scanned while listening to continuous text have flourished. Using word embeddings at first, then large language models, researchers have created encoding models to analyze the brain signals. Presenting these models with the same text as the participants allows to identify brain areas where there is a significant correlation between the functional magnetic resonance imaging (fMRI) time series and the ones predicted by the models' artificial neurons. One intriguing finding from these studies is that they have revealed highly symmetric bilateral activation patterns, somewhat at odds with the well-known left lateralization of language processing. Here, we report analyses of an fMRI dataset where we manipulate the complexity of large language models, testing 28 pretrained models from 8 different families, ranging from 124M to 14.2B parameters. First, we observe that the performance of models in predicting brain responses follows a scaling law, where the fit with brain activity increases linearly with the logarithm of the number of parameters of the model (and its performance on natural language processing tasks). Second, we show that a left-right asymmetry gradually appears as model size increases, and that the difference in left-right brain correlations also follows a scaling law. Whereas the smallest models show no asymmetry, larger models fit better and better left hemispheric activations than right hemispheric ones. This finding reconciles computational analyses of brain activity using large language models with the classic observation from aphasic patients showing left hemisphere dominance for language.
Probing Brain Context-Sensitivity with Masked-Attention Generation
May 23, 2023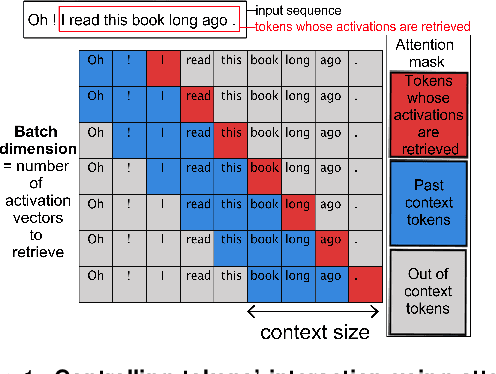
Two fundamental questions in neurolinguistics concerns the brain regions that integrate information beyond the lexical level, and the size of their window of integration. To address these questions we introduce a new approach named masked-attention generation. It uses GPT-2 transformers to generate word embeddings that capture a fixed amount of contextual information. We then tested whether these embeddings could predict fMRI brain activity in humans listening to naturalistic text. The results showed that most of the cortex within the language network is sensitive to contextual information, and that the right hemisphere is more sensitive to longer contexts than the left. Masked-attention generation supports previous analyses of context-sensitivity in the brain, and complements them by quantifying the window size of context integration per voxel.
* 2 pages, 2 figures, CCN 2023
Information-Restricted Neural Language Models Reveal Different Brain Regions' Sensitivity to Semantics, Syntax and Context
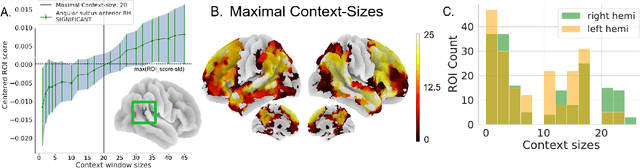
Feb 28, 2023A fundamental question in neurolinguistics concerns the brain regions involved in syntactic and semantic processing during speech comprehension, both at the lexical (word processing) and supra-lexical levels (sentence and discourse processing). To what extent are these regions separated or intertwined? To address this question, we trained a lexical language model, Glove, and a supra-lexical language model, GPT-2, on a text corpus from which we selectively removed either syntactic or semantic information. We then assessed to what extent these information-restricted models were able to predict the time-courses of fMRI signal of humans listening to naturalistic text. We also manipulated the size of contextual information provided to GPT-2 in order to determine the windows of integration of brain regions involved in supra-lexical processing. Our analyses show that, while most brain regions involved in language are sensitive to both syntactic and semantic variables, the relative magnitudes of these effects vary a lot across these regions. Furthermore, we found an asymmetry between the left and right hemispheres, with semantic and syntactic processing being more dissociated in the left hemisphere than in the right, and the left and right hemispheres showing respectively greater sensitivity to short and long contexts. The use of information-restricted NLP models thus shed new light on the spatial organization of syntactic processing, semantic processing and compositionality.
Neural Language Models are not Born Equal to Fit Brain Data, but Training Helps
Jul 07, 2022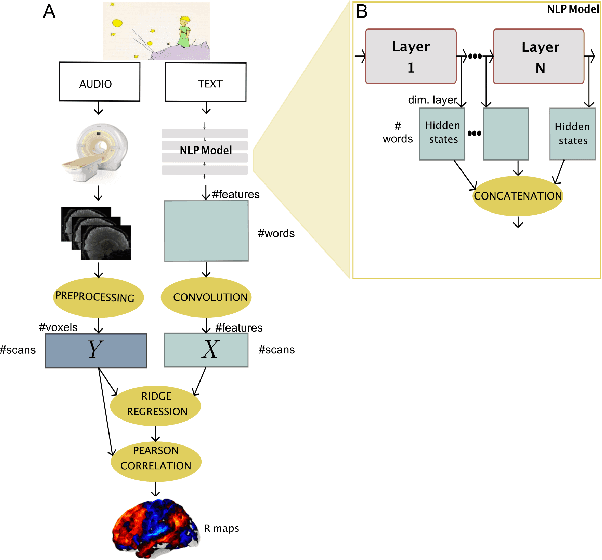
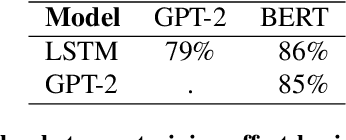
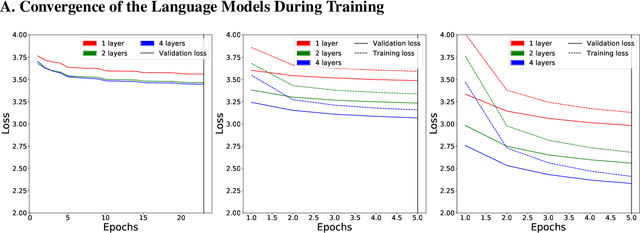
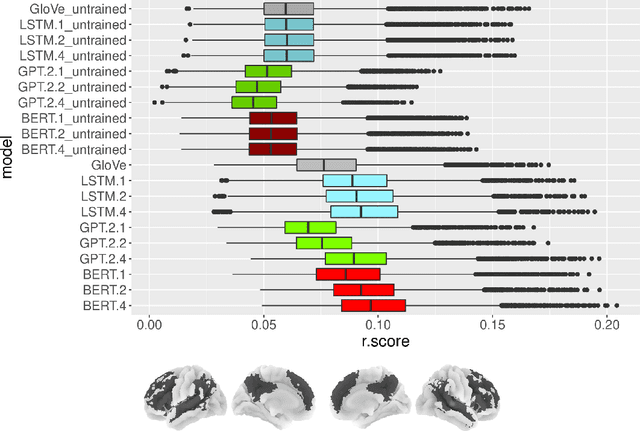
Neural Language Models (NLMs) have made tremendous advances during the last years, achieving impressive performance on various linguistic tasks. Capitalizing on this, studies in neuroscience have started to use NLMs to study neural activity in the human brain during language processing. However, many questions remain unanswered regarding which factors determine the ability of a neural language model to capture brain activity (aka its 'brain score'). Here, we make first steps in this direction and examine the impact of test loss, training corpus and model architecture (comparing GloVe, LSTM, GPT-2 and BERT), on the prediction of functional Magnetic Resonance Imaging timecourses of participants listening to an audiobook. We find that (1) untrained versions of each model already explain significant amount of signal in the brain by capturing similarity in brain responses across identical words, with the untrained LSTM outperforming the transformerbased models, being less impacted by the effect of context; (2) that training NLP models improves brain scores in the same brain regions irrespective of the model's architecture; (3) that Perplexity (test loss) is not a good predictor of brain score; (4) that training data have a strong influence on the outcome and, notably, that off-the-shelf models may lack statistical power to detect brain activations. Overall, we outline the impact of modeltraining choices, and suggest good practices for future studies aiming at explaining the human language system using neural language models.
Toward a realistic model of speech processing in the brain with self-supervised learning
Jun 03, 2022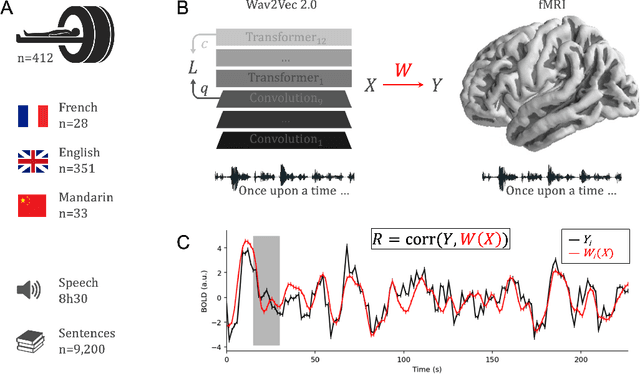
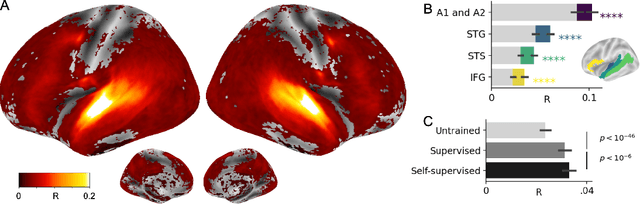
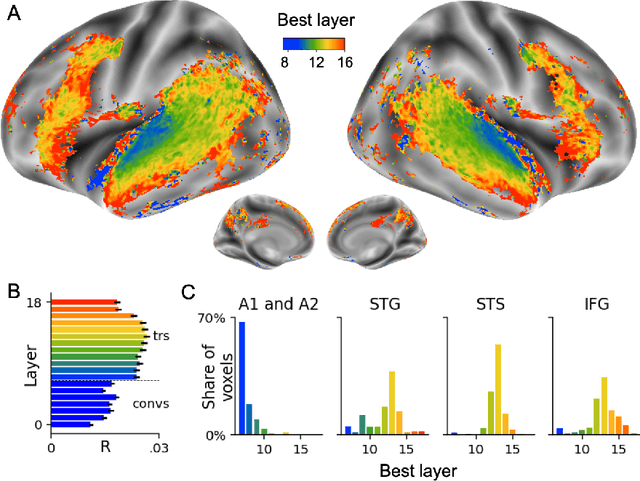
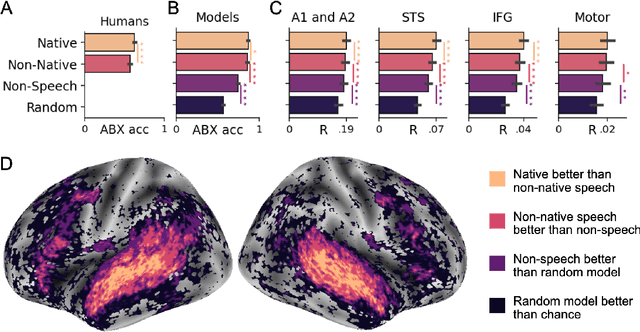
Several deep neural networks have recently been shown to generate activations similar to those of the brain in response to the same input. These algorithms, however, remain largely implausible: they require (1) extraordinarily large amounts of data, (2) unobtainable supervised labels, (3) textual rather than raw sensory input, and / or (4) implausibly large memory (e.g. thousands of contextual words). These elements highlight the need to identify algorithms that, under these limitations, would suffice to account for both behavioral and brain responses. Focusing on the issue of speech processing, we here hypothesize that self-supervised algorithms trained on the raw waveform constitute a promising candidate. Specifically, we compare a recent self-supervised architecture, Wav2Vec 2.0, to the brain activity of 412 English, French, and Mandarin individuals recorded with functional Magnetic Resonance Imaging (fMRI), while they listened to ~1h of audio books. Our results are four-fold. First, we show that this algorithm learns brain-like representations with as little as 600 hours of unlabelled speech -- a quantity comparable to what infants can be exposed to during language acquisition. Second, its functional hierarchy aligns with the cortical hierarchy of speech processing. Third, different training regimes reveal a functional specialization akin to the cortex: Wav2Vec 2.0 learns sound-generic, speech-specific and language-specific representations similar to those of the prefrontal and temporal cortices. Fourth, we confirm the similarity of this specialization with the behavior of 386 additional participants. These elements, resulting from the largest neuroimaging benchmark to date, show how self-supervised learning can account for a rich organization of speech processing in the brain, and thus delineate a path to identify the laws of language acquisition which shape the human brain.
Learning to rank from medical imaging data
Sep 30, 2012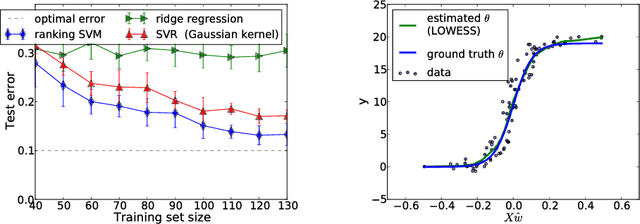
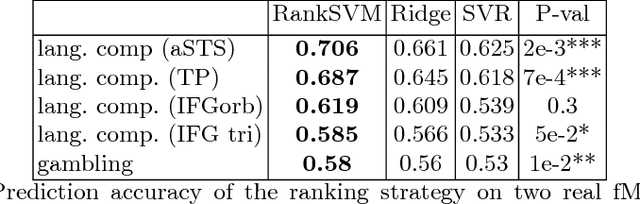
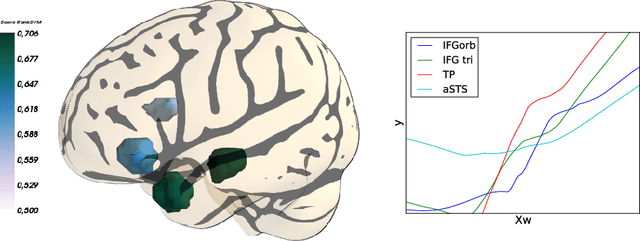
Medical images can be used to predict a clinical score coding for the severity of a disease, a pain level or the complexity of a cognitive task. In all these cases, the predicted variable has a natural order. While a standard classifier discards this information, we would like to take it into account in order to improve prediction performance. A standard linear regression does model such information, however the linearity assumption is likely not be satisfied when predicting from pixel intensities in an image. In this paper we address these modeling challenges with a supervised learning procedure where the model aims to order or rank images. We use a linear model for its robustness in high dimension and its possible interpretation. We show on simulations and two fMRI datasets that this approach is able to predict the correct ordering on pairs of images, yielding higher prediction accuracy than standard regression and multiclass classification techniques.
Improving accuracy and power with transfer learning using a meta-analytic database
Sep 28, 2012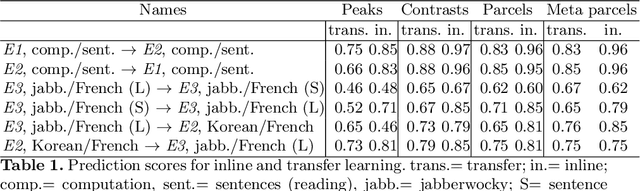
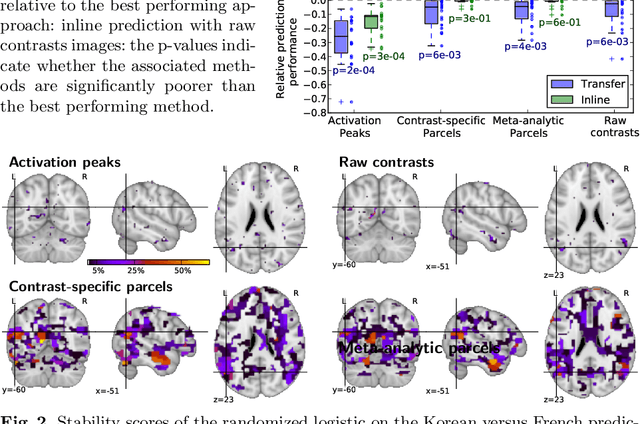

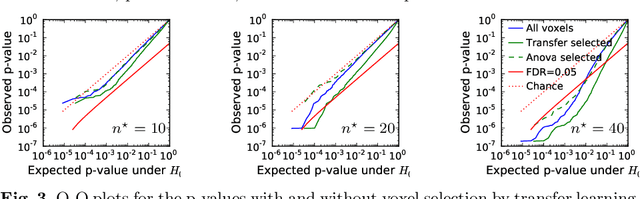
Typical cohorts in brain imaging studies are not large enough for systematic testing of all the information contained in the images. To build testable working hypotheses, investigators thus rely on analysis of previous work, sometimes formalized in a so-called meta-analysis. In brain imaging, this approach underlies the specification of regions of interest (ROIs) that are usually selected on the basis of the coordinates of previously detected effects. In this paper, we propose to use a database of images, rather than coordinates, and frame the problem as transfer learning: learning a discriminant model on a reference task to apply it to a different but related new task. To facilitate statistical analysis of small cohorts, we use a sparse discriminant model that selects predictive voxels on the reference task and thus provides a principled procedure to define ROIs. The benefits of our approach are twofold. First it uses the reference database for prediction, i.e. to provide potential biomarkers in a clinical setting. Second it increases statistical power on the new task. We demonstrate on a set of 18 pairs of functional MRI experimental conditions that our approach gives good prediction. In addition, on a specific transfer situation involving different scanners at different locations, we show that voxel selection based on transfer learning leads to higher detection power on small cohorts.