 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidation of a new, minimally-invasive, software smartphone device to predict sleep apnea and its severity: transversal study
Jun 20, 2024Obstructive sleep apnea (OSA) is frequent and responsible for cardiovascular complications and excessive daytime sleepiness. It is underdiagnosed due to the difficulty to access the gold standard for diagnosis, polysomnography (PSG). Alternative methods using smartphone sensors could be useful to increase diagnosis. The objective is to assess the performances of Apneal, an application that records the sound using a smartphone's microphone and movements thanks to a smartphone's accelerometer and gyroscope, to estimate patients' AHI. In this article, we perform a monocentric proof-of-concept study with a first manual scoring step, and then an automatic detection of respiratory events from the recorded signals using a sequential deep-learning model which was released internally at Apneal at the end of 2022 (version 0.1 of Apneal automatic scoring of respiratory events), in adult patients during in-hospital polysomnography.46 patients (women 34 per cent, mean BMI 28.7 kg per m2) were included. For AHI superior to 15, sensitivity of manual scoring was 0.91, and positive predictive value (PPV) 0.89. For AHI superior to 30, sensitivity was 0.85, PPV 0.94. We obtained an AUC-ROC of 0.85 and an AUC-PR of 0.94 for the identification of AHI superior to 15, and AUC-ROC of 0.95 and AUC-PR of 0.93 for AHI superior to 30. Promising results are obtained for the automatic annotations of events.This article shows that manual scoring of smartphone-based signals is possible and accurate compared to PSG-based scorings. Automatic scoring method based on a deep learning model provides promising results. A larger multicentric validation study, involving subjects with different SAHS severity is required to confirm these results.
Toward a realistic model of speech processing in the brain with self-supervised learning
Jun 03, 2022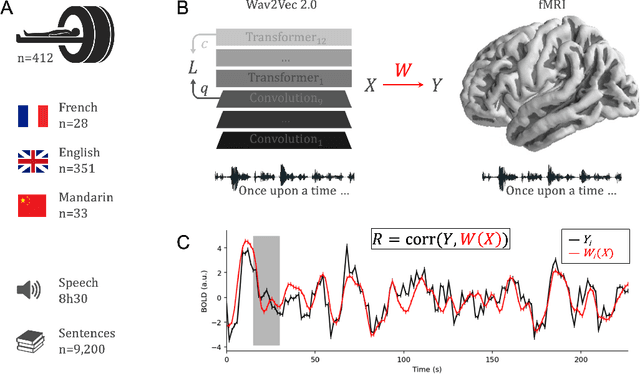
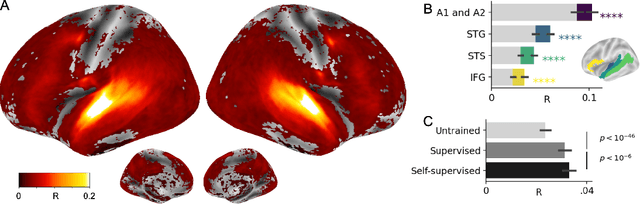
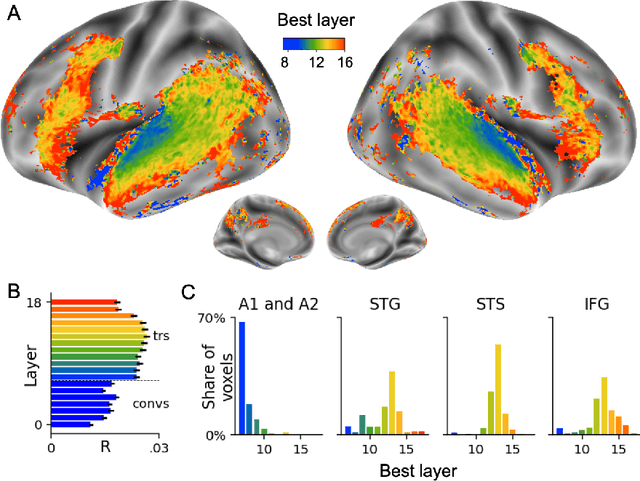
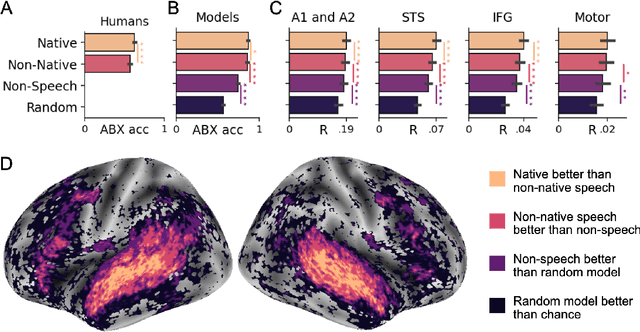
Several deep neural networks have recently been shown to generate activations similar to those of the brain in response to the same input. These algorithms, however, remain largely implausible: they require (1) extraordinarily large amounts of data, (2) unobtainable supervised labels, (3) textual rather than raw sensory input, and / or (4) implausibly large memory (e.g. thousands of contextual words). These elements highlight the need to identify algorithms that, under these limitations, would suffice to account for both behavioral and brain responses. Focusing on the issue of speech processing, we here hypothesize that self-supervised algorithms trained on the raw waveform constitute a promising candidate. Specifically, we compare a recent self-supervised architecture, Wav2Vec 2.0, to the brain activity of 412 English, French, and Mandarin individuals recorded with functional Magnetic Resonance Imaging (fMRI), while they listened to ~1h of audio books. Our results are four-fold. First, we show that this algorithm learns brain-like representations with as little as 600 hours of unlabelled speech -- a quantity comparable to what infants can be exposed to during language acquisition. Second, its functional hierarchy aligns with the cortical hierarchy of speech processing. Third, different training regimes reveal a functional specialization akin to the cortex: Wav2Vec 2.0 learns sound-generic, speech-specific and language-specific representations similar to those of the prefrontal and temporal cortices. Fourth, we confirm the similarity of this specialization with the behavior of 386 additional participants. These elements, resulting from the largest neuroimaging benchmark to date, show how self-supervised learning can account for a rich organization of speech processing in the brain, and thus delineate a path to identify the laws of language acquisition which shape the human brain.
Predicting non-native speech perception using the Perceptual Assimilation Model and state-of-the-art acoustic models
May 31, 2022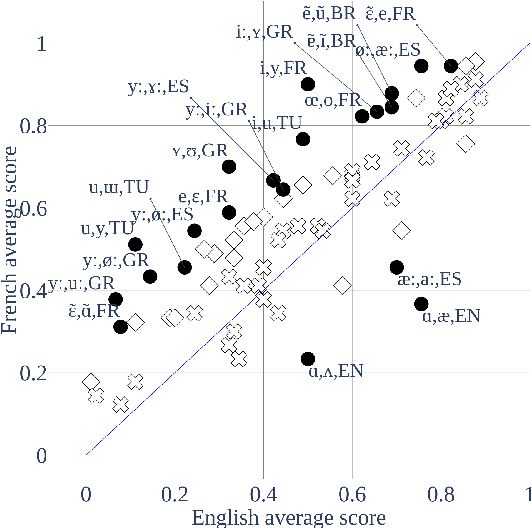
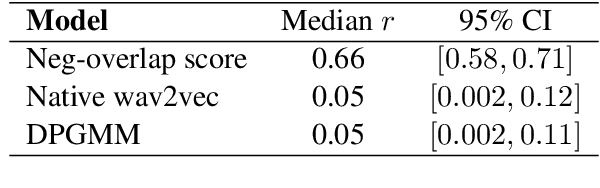

Our native language influences the way we perceive speech sounds, affecting our ability to discriminate non-native sounds. We compare two ideas about the influence of the native language on speech perception: the Perceptual Assimilation Model, which appeals to a mental classification of sounds into native phoneme categories, versus the idea that rich, fine-grained phonetic representations tuned to the statistics of the native language, are sufficient. We operationalize this idea using representations from two state-of-the-art speech models, a Dirichlet process Gaussian mixture model and the more recent wav2vec 2.0 model. We present a new, open dataset of French- and English-speaking participants' speech perception behaviour for 61 vowel sounds from six languages. We show that phoneme assimilation is a better predictor than fine-grained phonetic modelling, both for the discrimination behaviour as a whole, and for predicting differences in discriminability associated with differences in native language background. We also show that wav2vec 2.0, while not good at capturing the effects of native language on speech perception, is complementary to information about native phoneme assimilation, and provides a good model of low-level phonetic representations, supporting the idea that both categorical and fine-grained perception are used during speech perception.
Do self-supervised speech models develop human-like perception biases?
May 31, 2022
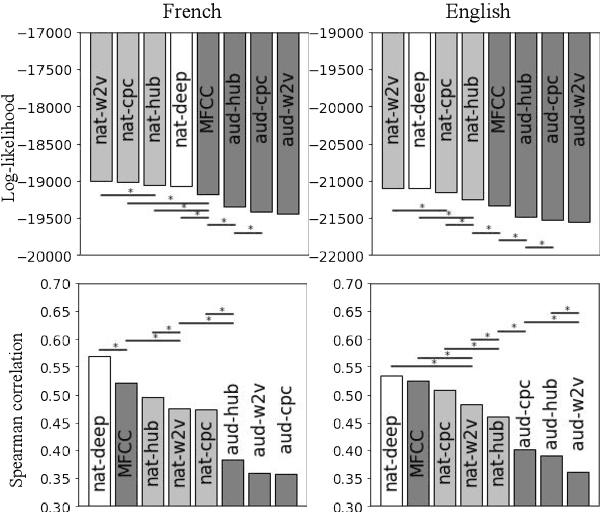
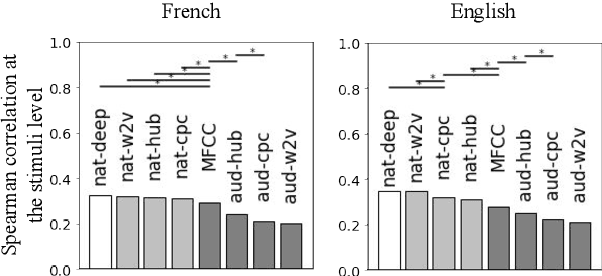

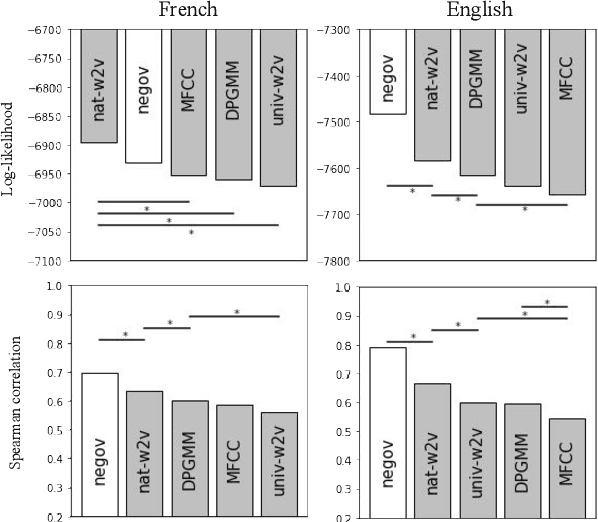
Self-supervised models for speech processing form representational spaces without using any external labels. Increasingly, they appear to be a feasible way of at least partially eliminating costly manual annotations, a problem of particular concern for low-resource languages. But what kind of representational spaces do these models construct? Human perception specializes to the sounds of listeners' native languages. Does the same thing happen in self-supervised models? We examine the representational spaces of three kinds of state-of-the-art self-supervised models: wav2vec 2.0, HuBERT and contrastive predictive coding (CPC), and compare them with the perceptual spaces of French-speaking and English-speaking human listeners, both globally and taking account of the behavioural differences between the two language groups. We show that the CPC model shows a small native language effect, but that wav2vec 2.0 and HuBERT seem to develop a universal speech perception space which is not language specific. A comparison against the predictions of supervised phone recognisers suggests that all three self-supervised models capture relatively fine-grained perceptual phenomena, while supervised models are better at capturing coarser, phone-level, effects of listeners' native language, on perception.
Inductive biases, pretraining and fine-tuning jointly account for brain responses to speech
Feb 25, 2021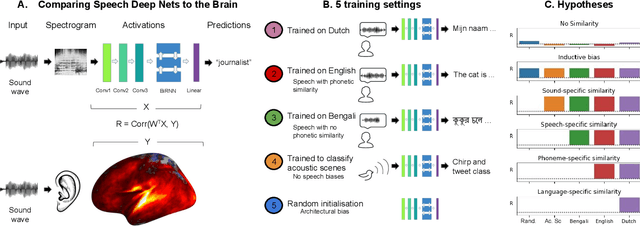
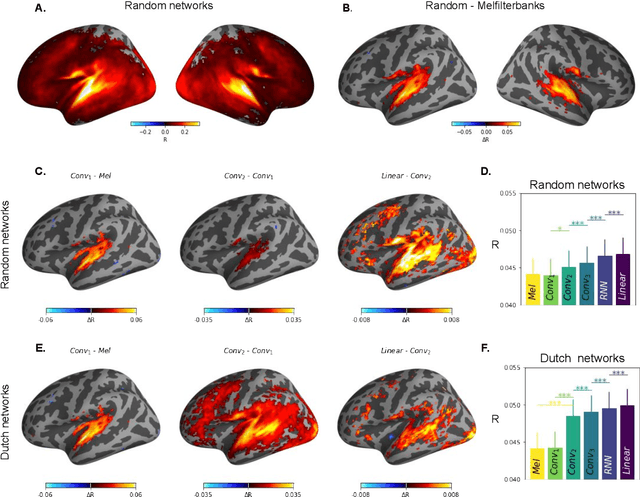
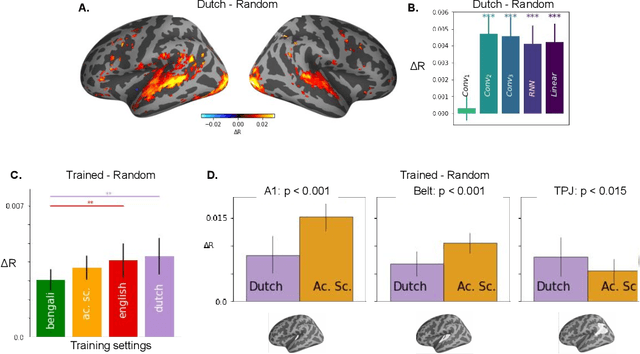
Our ability to comprehend speech remains, to date, unrivaled by deep learning models. This feat could result from the brain's ability to fine-tune generic sound representations for speech-specific processes. To test this hypothesis, we compare i) five types of deep neural networks to ii) human brain responses elicited by spoken sentences and recorded in 102 Dutch subjects using functional Magnetic Resonance Imaging (fMRI). Each network was either trained on an acoustics scene classification, a speech-to-text task (based on Bengali, English, or Dutch), or not trained. The similarity between each model and the brain is assessed by correlating their respective activations after an optimal linear projection. The differences in brain-similarity across networks revealed three main results. First, speech representations in the brain can be accounted for by random deep networks. Second, learning to classify acoustic scenes leads deep nets to increase their brain similarity. Third, learning to process phonetically-related speech inputs (i.e., Dutch vs English) leads deep nets to reach higher levels of brain-similarity than learning to process phonetically-distant speech inputs (i.e. Dutch vs Bengali). Together, these results suggest that the human brain fine-tunes its heavily-trained auditory hierarchy to learn to process speech.
Perceptimatic: A human speech perception benchmark for unsupervised subword modelling
Oct 12, 2020
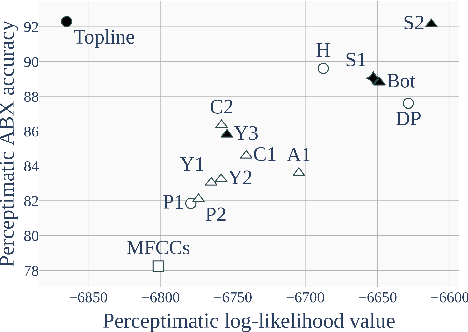
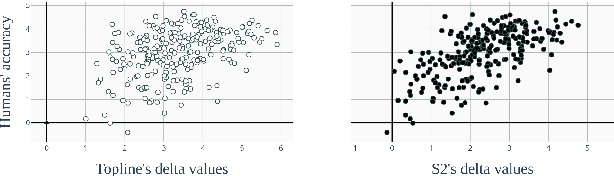
In this paper, we present a data set and methods to compare speech processing models and human behaviour on a phone discrimination task. We provide Perceptimatic, an open data set which consists of French and English speech stimuli, as well as the results of 91 English- and 93 French-speaking listeners. The stimuli test a wide range of French and English contrasts, and are extracted directly from corpora of natural running read speech, used for the 2017 Zero Resource Speech Challenge. We provide a method to compare humans' perceptual space with models' representational space, and we apply it to models previously submitted to the Challenge. We show that, unlike unsupervised models and supervised multilingual models, a standard supervised monolingual HMM-GMM phone recognition system, while good at discriminating phones, yields a representational space very different from that of human native listeners.
The Perceptimatic English Benchmark for Speech Perception Models
May 07, 2020


We present the Perceptimatic English Benchmark, an open experimental benchmark for evaluating quantitative models of speech perception in English. The benchmark consists of ABX stimuli along with the responses of 91 American English-speaking listeners. The stimuli test discrimination of a large number of English and French phonemic contrasts. They are extracted directly from corpora of read speech, making them appropriate for evaluating statistical acoustic models (such as those used in automatic speech recognition) trained on typical speech data sets. We show that phone discrimination is correlated with several types of models, and give recommendations for researchers seeking easily calculated norms of acoustic distance on experimental stimuli. We show that DeepSpeech, a standard English speech recognizer, is more specialized on English phoneme discrimination than English listeners, and is poorly correlated with their behaviour, even though it yields a low error on the decision task given to humans.
Learning to detect dysarthria from raw speech
Nov 27, 2018
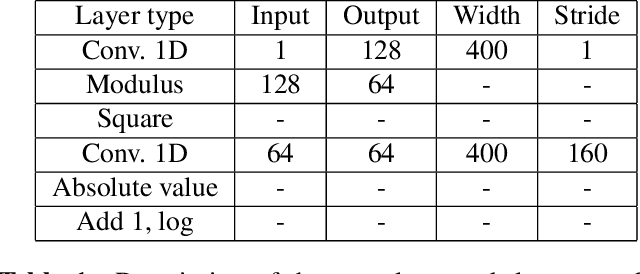

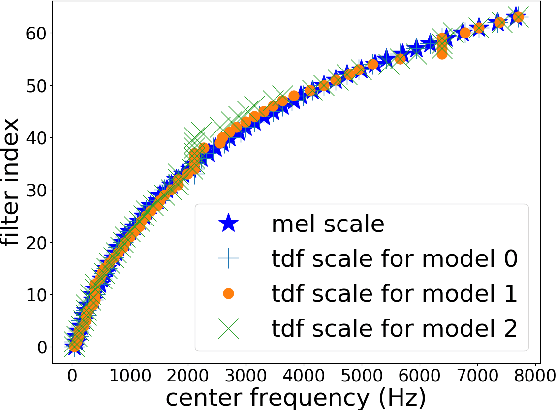
Speech classifiers of paralinguistic traits traditionally learn from diverse hand-crafted low-level features, by selecting the relevant information for the task at hand. We explore an alternative to this selection, by learning jointly the classifier, and the feature extraction. Recent work on speech recognition has shown improved performance over speech features by learning from the waveform. We extend this approach to paralinguistic classification and propose a neural network that can learn a filterbank, a normalization factor and a compression power from the raw speech, jointly with the rest of the architecture. We apply this model to dysarthria detection from sentence-level audio recordings. Starting from a strong attention-based baseline on which mel-filterbanks outperform standard low-level descriptors, we show that learning the filters or the normalization and compression improves over fixed features by 10% absolute accuracy. We also observe a gain over OpenSmile features by learning jointly the feature extraction, the normalization, and the compression factor with the architecture. This constitutes a first attempt at learning jointly all these operations from raw audio for a speech classification task.