 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptimatic: A human speech perception benchmark for unsupervised subword modelling
Paper and Code

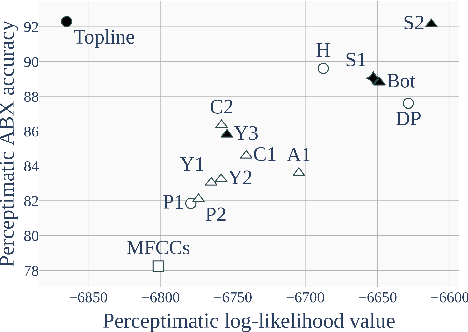
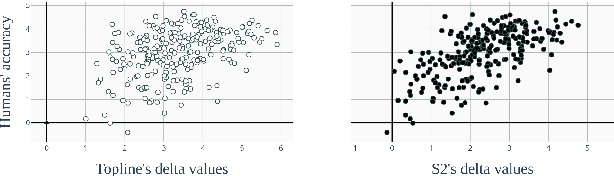
In this paper, we present a data set and methods to compare speech processing models and human behaviour on a phone discrimination task. We provide Perceptimatic, an open data set which consists of French and English speech stimuli, as well as the results of 91 English- and 93 French-speaking listeners. The stimuli test a wide range of French and English contrasts, and are extracted directly from corpora of natural running read speech, used for the 2017 Zero Resource Speech Challenge. We provide a method to compare humans' perceptual space with models' representational space, and we apply it to models previously submitted to the Challenge. We show that, unlike unsupervised models and supervised multilingual models, a standard supervised monolingual HMM-GMM phone recognition system, while good at discriminating phones, yields a representational space very different from that of human native listeners.