 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscoPhon: Benchmarking the Unsupervised Discovery of Phoneme Inventories With Discrete Speech Units
Mar 19, 2026We introduce DiscoPhon, a multilingual benchmark for evaluating unsupervised phoneme discovery from discrete speech units. DiscoPhon covers 6 dev and 6 test languages, chosen to span a wide range of phonemic contrasts. Given only 10 hours of speech in a previously unseen language, systems must produce discrete units that are mapped to a predefined phoneme inventory, through either a many-to-one or a one-to-one assignment. The resulting sequences are evaluated for unit quality, recognition and segmentation. We provide four pretrained multilingual HuBERT and SpidR baselines, and show that phonemic information is available enough in current models for derived units to correlate well with phonemes, though with variations across languages.
Iterative refinement, not training objective, makes HuBERT behave differently from wav2vec 2.0
Aug 11, 2025
Self-supervised models for speech representation learning now see widespread use for their versatility and performance on downstream tasks, but the effect of model architecture on the linguistic information learned in their representations remains under-studied. This study investigates two such models, HuBERT and wav2vec 2.0, and minimally compares two of their architectural differences: training objective and iterative pseudo-label refinement through multiple training iterations. We find that differences in canonical correlation of hidden representations to word identity, phoneme identity, and speaker identity are explained by training iteration, not training objective. We suggest that future work investigate the reason for the effectiveness of iterative refinement in encoding linguistic information in self-supervised speech representations.
The Faetar Benchmark: Speech Recognition in a Very Under-Resourced Language
Sep 12, 2024
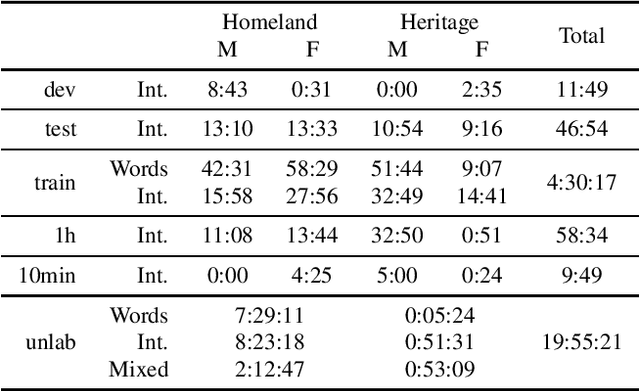
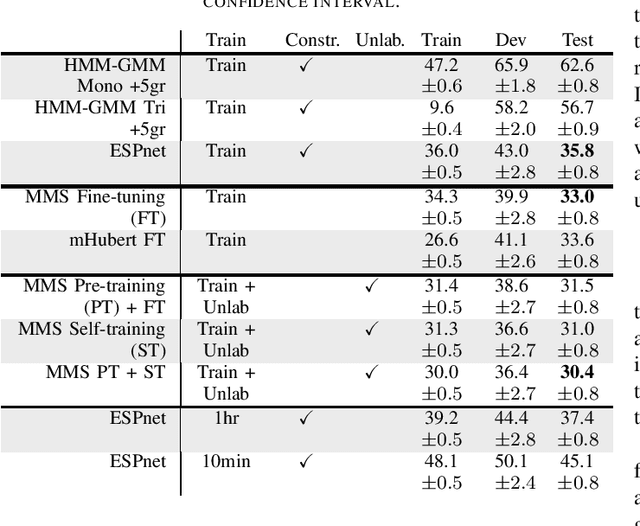
We introduce the Faetar Automatic Speech Recognition Benchmark, a benchmark corpus designed to push the limits of current approaches to low-resource speech recognition. Faetar, a Franco-Proven\c{c}al variety spoken primarily in Italy, has no standard orthography, has virtually no existing textual or speech resources other than what is included in the benchmark, and is quite different from other forms of Franco-Proven\c{c}al. The corpus comes from field recordings, most of which are noisy, for which only 5 hrs have matching transcriptions, and for which forced alignment is of variable quality. The corpus contains an additional 20 hrs of unlabelled speech. We report baseline results from state-of-the-art multilingual speech foundation models with a best phone error rate of 30.4%, using a pipeline that continues pre-training on the foundation model using the unlabelled set.
Quantifying the Role of Textual Predictability in Automatic Speech Recognition
Jul 23, 2024



A long-standing question in automatic speech recognition research is how to attribute errors to the ability of a model to model the acoustics, versus its ability to leverage higher-order context (lexicon, morphology, syntax, semantics). We validate a novel approach which models error rates as a function of relative textual predictability, and yields a single number, $k$, which measures the effect of textual predictability on the recognizer. We use this method to demonstrate that a Wav2Vec 2.0-based model makes greater stronger use of textual context than a hybrid ASR model, in spite of not using an explicit language model, and also use it to shed light on recent results demonstrating poor performance of standard ASR systems on African-American English. We demonstrate that these mostly represent failures of acoustic--phonetic modelling. We show how this approach can be used straightforwardly in diagnosing and improving ASR.
Bigger is not Always Better: The Effect of Context Size on Speech Pre-Training
Dec 03, 2023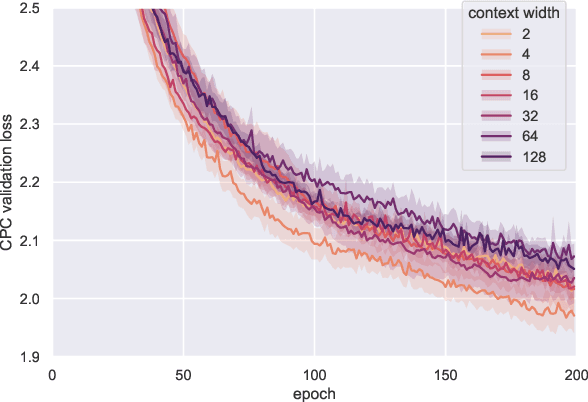
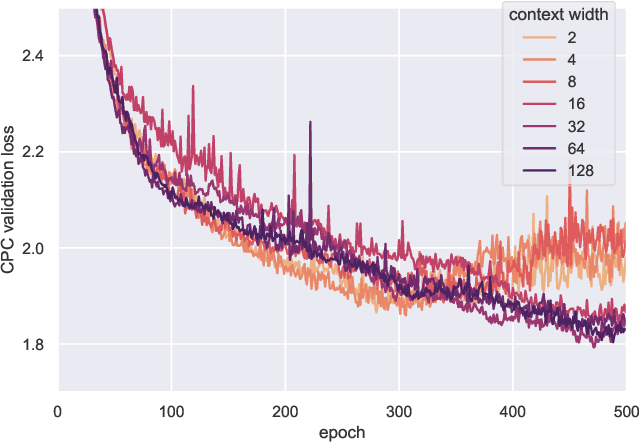
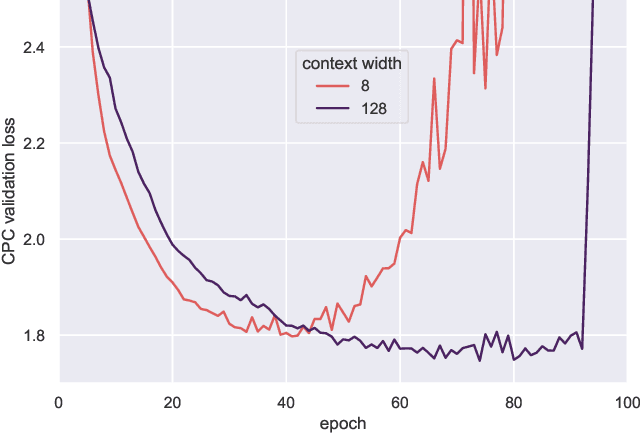
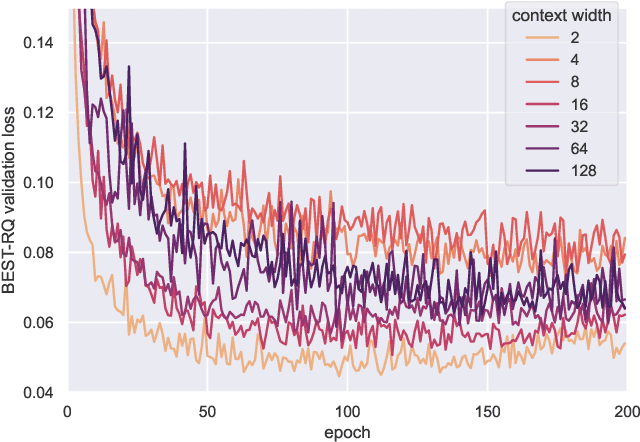
It has been generally assumed in the automatic speech recognition (ASR) literature that it is better for models to have access to wider context windows. Yet, many of the potential reasons this might be true in the supervised setting do not necessarily transfer over to the case of unsupervised learning. We investigate how much context is necessary to achieve high-quality pre-trained acoustic models using self-supervised learning. We principally investigate contrastive predictive coding (CPC), which we adapt to be able to precisely control the amount of context visible to the model during training and inference. We find that phone discriminability in the resulting model representations peaks at around 40~ms of preceding context, and that having too much context (beyond around 320 ms) substantially degrades the quality of the representations. Surprisingly, we find that this pattern also transfers to supervised ASR when the pre-trained representations are used as frozen input features. Our results point to potential changes in the design of current upstream architectures to better facilitate a variety of downstream tasks.
Zero Resource Code-switched Speech Benchmark Using Speech Utterance Pairs For Multiple Spoken Languages
Oct 04, 2023
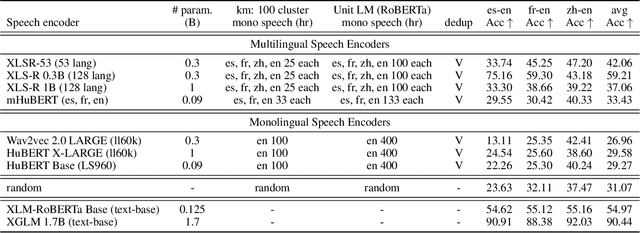
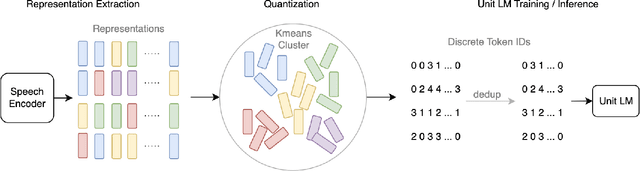
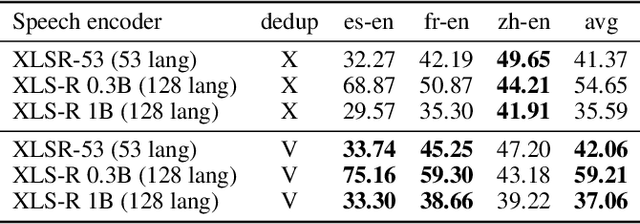
We introduce a new zero resource code-switched speech benchmark designed to directly assess the code-switching capabilities of self-supervised speech encoders. We showcase a baseline system of language modeling on discrete units to demonstrate how the code-switching abilities of speech encoders can be assessed in a zero-resource manner. Our experiments encompass a variety of well-known speech encoders, including Wav2vec 2.0, HuBERT, XLSR, etc. We examine the impact of pre-training languages and model size on benchmark performance. Notably, though our results demonstrate that speech encoders with multilingual pre-training, exemplified by XLSR, outperform monolingual variants (Wav2vec 2.0, HuBERT) in code-switching scenarios, there is still substantial room for improvement in their code-switching linguistic abilities.
Evaluating context-invariance in unsupervised speech representations
Oct 27, 2022



Unsupervised speech representations have taken off, with benchmarks (SUPERB, ZeroSpeech) demonstrating major progress on semi-supervised speech recognition, speech synthesis, and speech-only language modelling. Inspiration comes from the promise of ``discovering the phonemes'' of a language or a similar low-bitrate encoding. However, one of the critical properties of phoneme transcriptions is context-invariance: the phonetic context of a speech sound can have massive influence on the way it is pronounced, while the text remains stable. This is what allows tokens of the same word to have the same transcriptions -- key to language understanding. Current benchmarks do not measure context-invariance. We develop a new version of the ZeroSpeech ABX benchmark that measures context-invariance, and apply it to recent self-supervised representations. We demonstrate that the context-independence of representations is predictive of the stability of word-level representations. We suggest research concentrate on improving context-independence of self-supervised and unsupervised representations.
Self-supervised language learning from raw audio: Lessons from the Zero Resource Speech Challenge
Oct 27, 2022



Recent progress in self-supervised or unsupervised machine learning has opened the possibility of building a full speech processing system from raw audio without using any textual representations or expert labels such as phonemes, dictionaries or parse trees. The contribution of the Zero Resource Speech Challenge series since 2015 has been to break down this long-term objective into four well-defined tasks -- Acoustic Unit Discovery, Spoken Term Discovery, Discrete Resynthesis, and Spoken Language Modeling -- and introduce associated metrics and benchmarks enabling model comparison and cumulative progress. We present an overview of the six editions of this challenge series since 2015, discuss the lessons learned, and outline the areas which need more work or give puzzling results.
Are word boundaries useful for unsupervised language learning?
Oct 06, 2022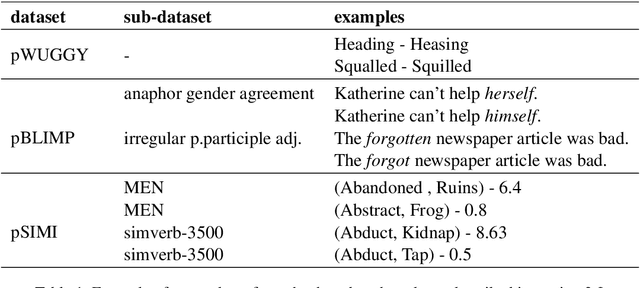

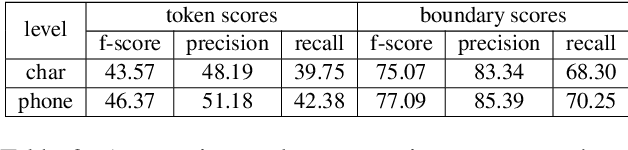
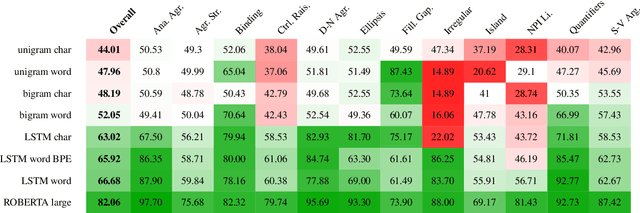
Word or word-fragment based Language Models (LM) are typically preferred over character-based ones in many downstream applications. This may not be surprising as words seem more linguistically relevant units than characters. Words provide at least two kinds of relevant information: boundary information and meaningful units. However, word boundary information may be absent or unreliable in the case of speech input (word boundaries are not marked explicitly in the speech stream). Here, we systematically compare LSTMs as a function of the input unit (character, phoneme, word, word part), with or without gold boundary information. We probe linguistic knowledge in the networks at the lexical, syntactic and semantic levels using three speech-adapted black box NLP psycholinguistically-inpired benchmarks (pWUGGY, pBLIMP, pSIMI). We find that the absence of boundaries costs between 2\% and 28\% in relative performance depending on the task. We show that gold boundaries can be replaced by automatically found ones obtained with an unsupervised segmentation algorithm, and that even modest segmentation performance gives a gain in performance on two of the three tasks compared to basic character/phone based models without boundary information.
Toward a realistic model of speech processing in the brain with self-supervised learning
Jun 03, 2022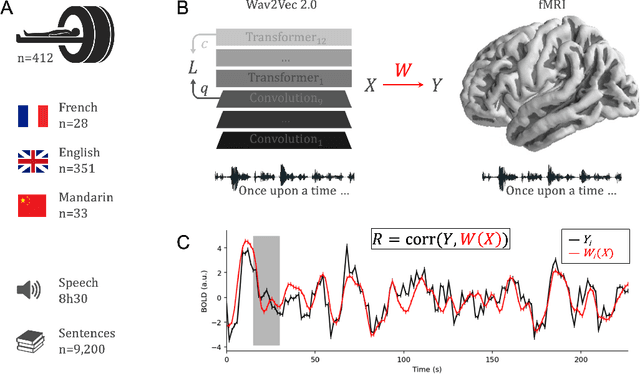
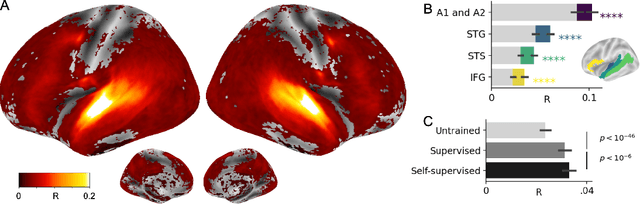
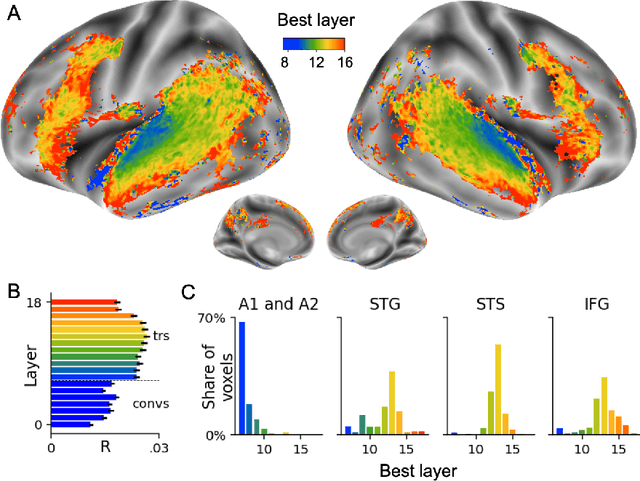
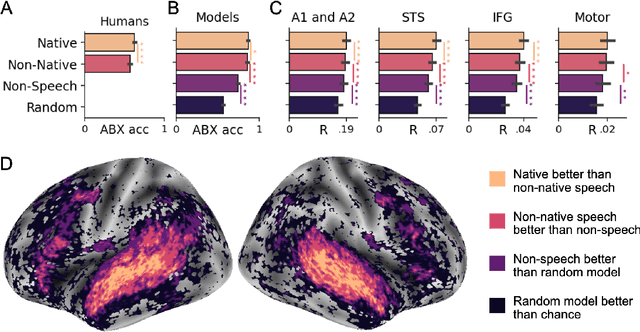
Several deep neural networks have recently been shown to generate activations similar to those of the brain in response to the same input. These algorithms, however, remain largely implausible: they require (1) extraordinarily large amounts of data, (2) unobtainable supervised labels, (3) textual rather than raw sensory input, and / or (4) implausibly large memory (e.g. thousands of contextual words). These elements highlight the need to identify algorithms that, under these limitations, would suffice to account for both behavioral and brain responses. Focusing on the issue of speech processing, we here hypothesize that self-supervised algorithms trained on the raw waveform constitute a promising candidate. Specifically, we compare a recent self-supervised architecture, Wav2Vec 2.0, to the brain activity of 412 English, French, and Mandarin individuals recorded with functional Magnetic Resonance Imaging (fMRI), while they listened to ~1h of audio books. Our results are four-fold. First, we show that this algorithm learns brain-like representations with as little as 600 hours of unlabelled speech -- a quantity comparable to what infants can be exposed to during language acquisition. Second, its functional hierarchy aligns with the cortical hierarchy of speech processing. Third, different training regimes reveal a functional specialization akin to the cortex: Wav2Vec 2.0 learns sound-generic, speech-specific and language-specific representations similar to those of the prefrontal and temporal cortices. Fourth, we confirm the similarity of this specialization with the behavior of 386 additional participants. These elements, resulting from the largest neuroimaging benchmark to date, show how self-supervised learning can account for a rich organization of speech processing in the brain, and thus delineate a path to identify the laws of language acquisition which shape the human brain.