 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigger is not Always Better: The Effect of Context Size on Speech Pre-Training
Paper and Code
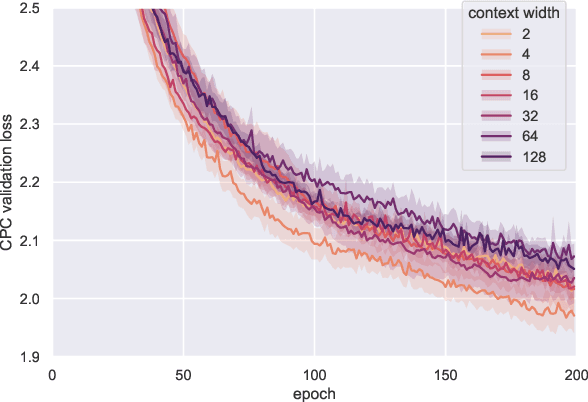
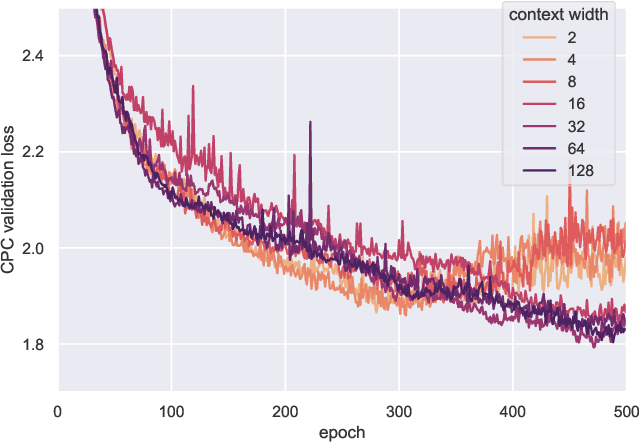
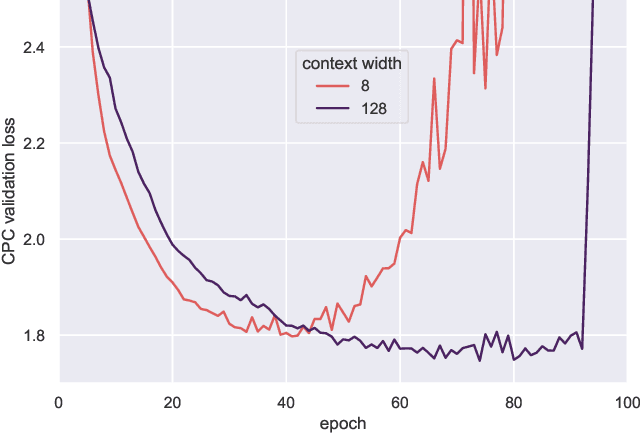
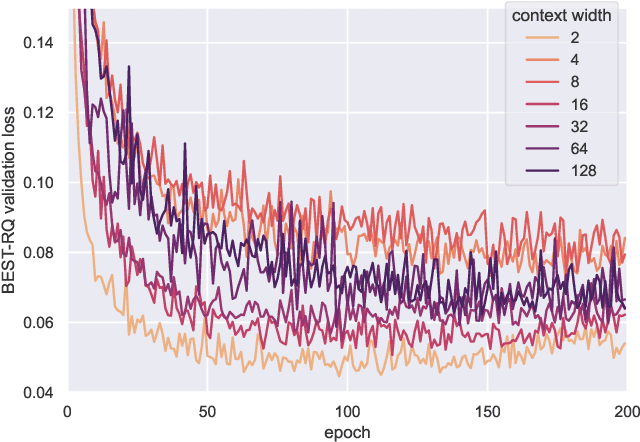
It has been generally assumed in the automatic speech recognition (ASR) literature that it is better for models to have access to wider context windows. Yet, many of the potential reasons this might be true in the supervised setting do not necessarily transfer over to the case of unsupervised learning. We investigate how much context is necessary to achieve high-quality pre-trained acoustic models using self-supervised learning. We principally investigate contrastive predictive coding (CPC), which we adapt to be able to precisely control the amount of context visible to the model during training and inference. We find that phone discriminability in the resulting model representations peaks at around 40~ms of preceding context, and that having too much context (beyond around 320 ms) substantially degrades the quality of the representations. Surprisingly, we find that this pattern also transfers to supervised ASR when the pre-trained representations are used as frozen input features. Our results point to potential changes in the design of current upstream architectures to better facilitate a variety of downstream tasks.