 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Faetar Benchmark: Speech Recognition in a Very Under-Resourced Language
Sep 12, 2024
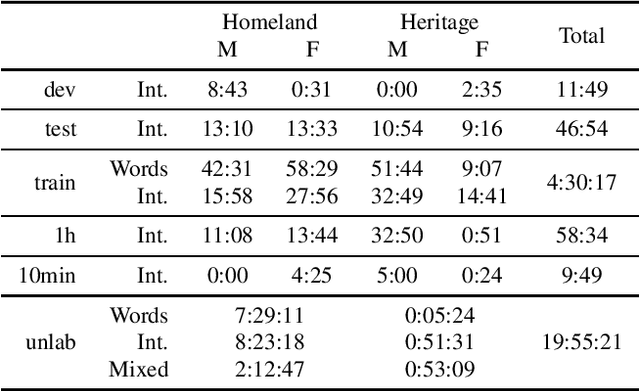
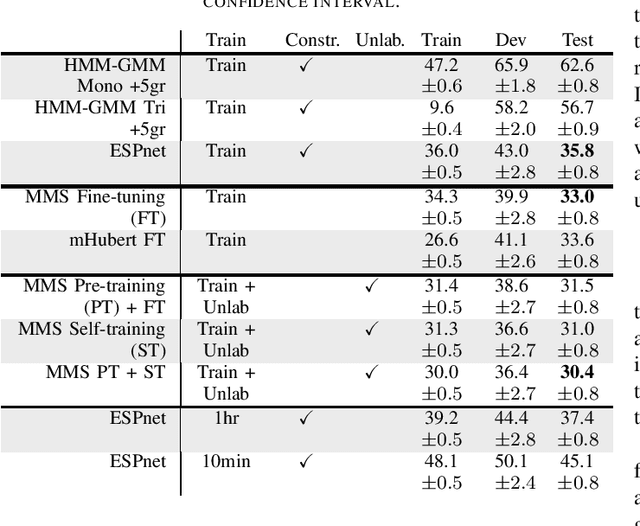
We introduce the Faetar Automatic Speech Recognition Benchmark, a benchmark corpus designed to push the limits of current approaches to low-resource speech recognition. Faetar, a Franco-Proven\c{c}al variety spoken primarily in Italy, has no standard orthography, has virtually no existing textual or speech resources other than what is included in the benchmark, and is quite different from other forms of Franco-Proven\c{c}al. The corpus comes from field recordings, most of which are noisy, for which only 5 hrs have matching transcriptions, and for which forced alignment is of variable quality. The corpus contains an additional 20 hrs of unlabelled speech. We report baseline results from state-of-the-art multilingual speech foundation models with a best phone error rate of 30.4%, using a pipeline that continues pre-training on the foundation model using the unlabelled set.
Quantifying the Role of Textual Predictability in Automatic Speech Recognition
Jul 23, 2024



A long-standing question in automatic speech recognition research is how to attribute errors to the ability of a model to model the acoustics, versus its ability to leverage higher-order context (lexicon, morphology, syntax, semantics). We validate a novel approach which models error rates as a function of relative textual predictability, and yields a single number, $k$, which measures the effect of textual predictability on the recognizer. We use this method to demonstrate that a Wav2Vec 2.0-based model makes greater stronger use of textual context than a hybrid ASR model, in spite of not using an explicit language model, and also use it to shed light on recent results demonstrating poor performance of standard ASR systems on African-American English. We demonstrate that these mostly represent failures of acoustic--phonetic modelling. We show how this approach can be used straightforwardly in diagnosing and improving ASR.
Bigger is not Always Better: The Effect of Context Size on Speech Pre-Training
Dec 03, 2023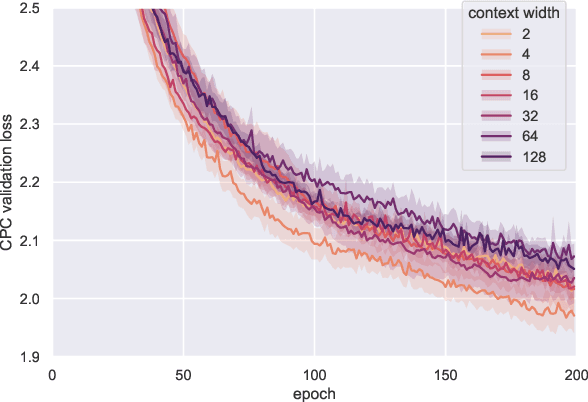
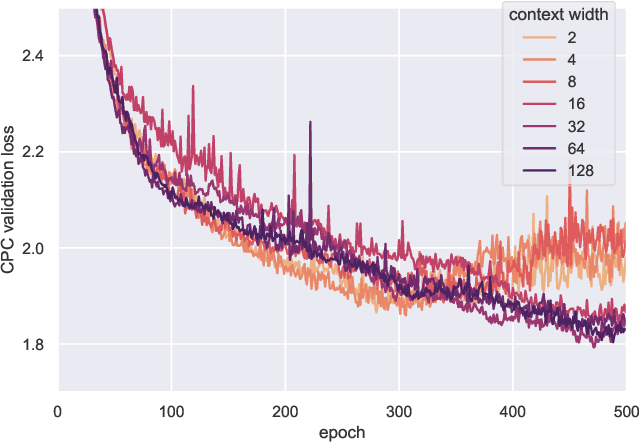
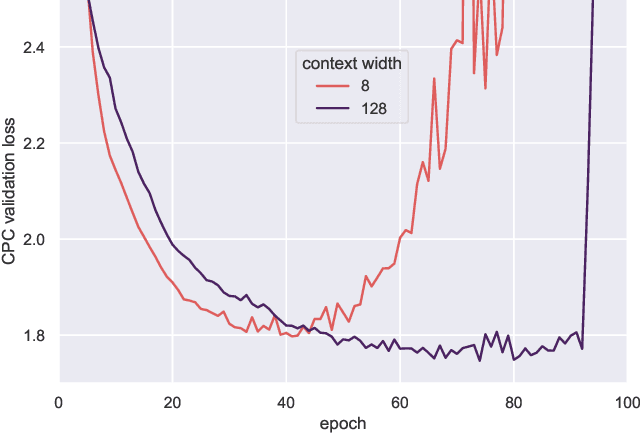
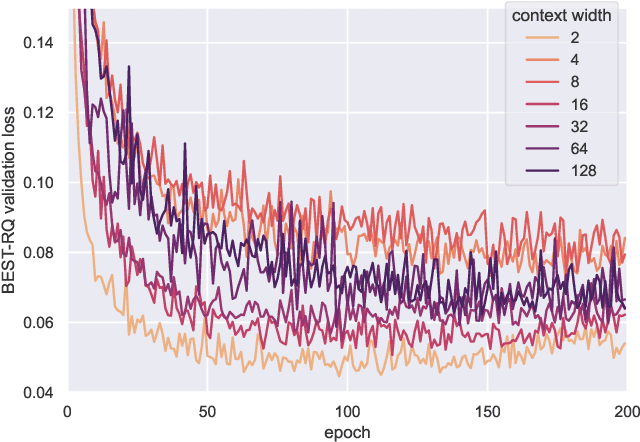
It has been generally assumed in the automatic speech recognition (ASR) literature that it is better for models to have access to wider context windows. Yet, many of the potential reasons this might be true in the supervised setting do not necessarily transfer over to the case of unsupervised learning. We investigate how much context is necessary to achieve high-quality pre-trained acoustic models using self-supervised learning. We principally investigate contrastive predictive coding (CPC), which we adapt to be able to precisely control the amount of context visible to the model during training and inference. We find that phone discriminability in the resulting model representations peaks at around 40~ms of preceding context, and that having too much context (beyond around 320 ms) substantially degrades the quality of the representations. Surprisingly, we find that this pattern also transfers to supervised ASR when the pre-trained representations are used as frozen input features. Our results point to potential changes in the design of current upstream architectures to better facilitate a variety of downstream tasks.
Bringing the State-of-the-Art to Customers: A Neural Agent Assistant Framework for Customer Service Support
Feb 07, 2023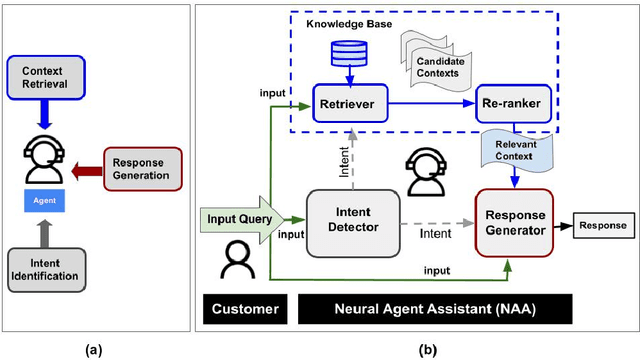
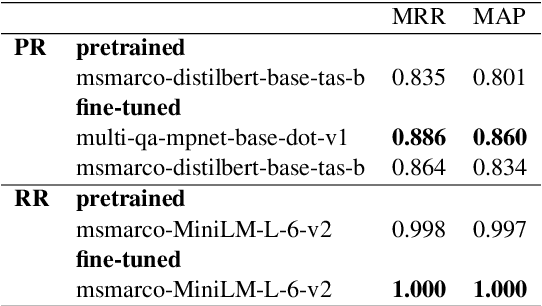
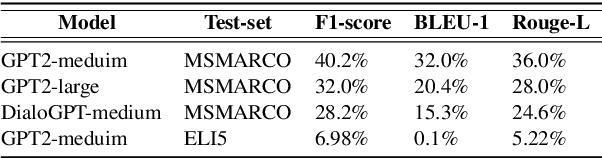
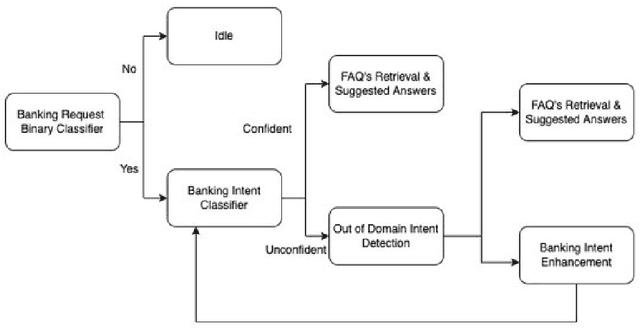
Building Agent Assistants that can help improve customer service support requires inputs from industry users and their customers, as well as knowledge about state-of-the-art Natural Language Processing (NLP) technology. We combine expertise from academia and industry to bridge the gap and build task/domain-specific Neural Agent Assistants (NAA) with three high-level components for: (1) Intent Identification, (2) Context Retrieval, and (3) Response Generation. In this paper, we outline the pipeline of the NAA's core system and also present three case studies in which three industry partners successfully adapt the framework to find solutions to their unique challenges. Our findings suggest that a collaborative process is instrumental in spurring the development of emerging NLP models for Conversational AI tasks in industry. The full reference implementation code and results are available at \url{https://github.com/VectorInstitute/NAA}
Exploring spectro-temporal features in end-to-end convolutional neural networks
Jan 01, 2019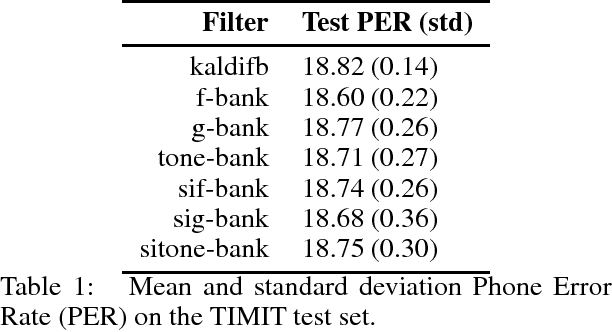
Triangular, overlapping Mel-scaled filters ("f-banks") are the current standard input for acoustic models that exploit their input's time-frequency geometry, because they provide a psycho-acoustically motivated time-frequency geometry for a speech signal. F-bank coefficients are provably robust to small deformations in the scale. In this paper, we explore two ways in which filter banks can be adjusted for the purposes of speech recognition. First, triangular filters can be replaced with Gabor filters, a compactly supported filter that better localizes events in time, or Gammatone filters, a psychoacoustically-motivated filter. Second, by rearranging the order of operations in computing filter bank features, features can be integrated over smaller time scales while simultaneously providing better frequency resolution. We make all feature implementations available online through open-source repositories. Initial experimentation with a modern end-to-end CNN phone recognizer yielded no significant improvements to phone error rate due to either modification. The result, and its ramifications with respect to learned filter banks, is discussed.